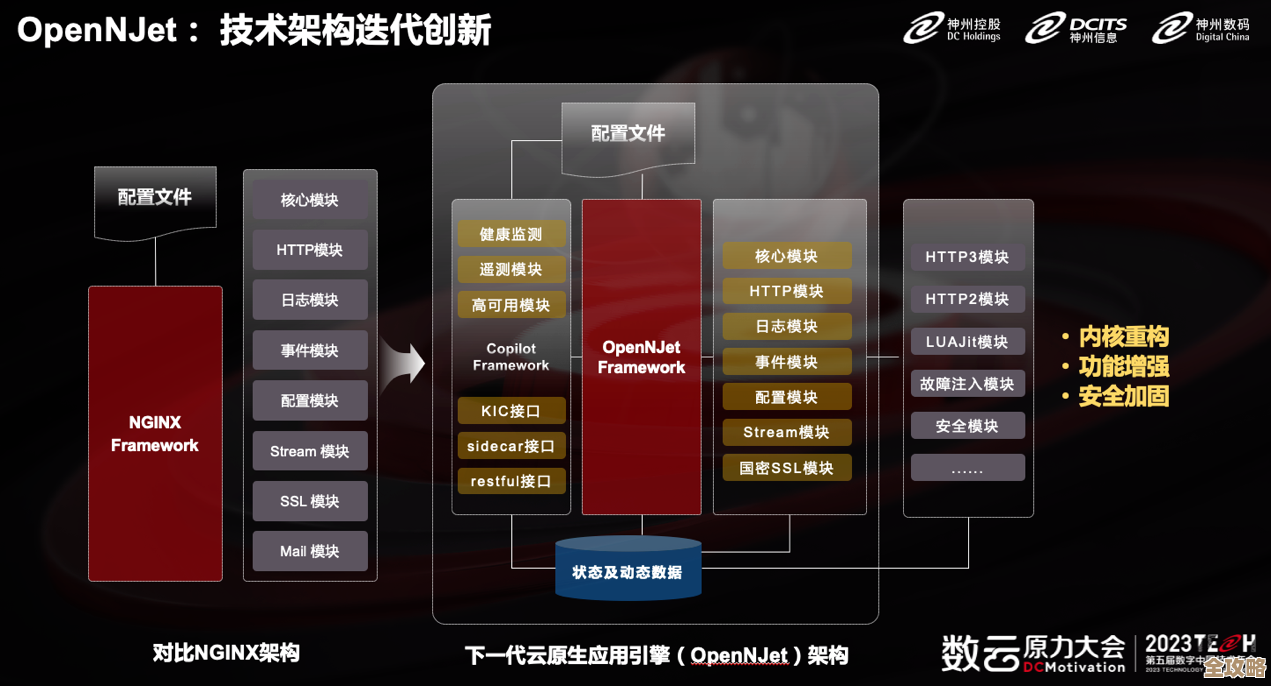
SQL里EXISTS和=ANY到底啥区别,举例说说看

要理解SQL里的EXISTS和= ANY的区别,咱们就别管那些书本上复杂的定义了,直接用大白话和例子来把它讲清楚,你可以把它们想象成两种不同的找人方式。
核心区别一句话:EXISTS关心的是“有没有”,而= ANY关心的是“是不是其中一个”。
EXISTS就像一个侦探,他接到一个任务:检查某个房间里“有没有”人,他根本不在乎房间里的人是谁,是张三还是李四,他只需要把门推开一条缝,看到里面有至少一个人影,就可以立刻回头报告:“存在(EXISTS)!” 如果房间里空无一人,他就报告:“不存在。” 这个过程非常快,因为他不需要认识里面的每一个人。
而= ANY则像一个严格的面试官,他手里有一份候选人名单(比如名单上是:张三、李四、王五),现在来了一个求职者,叫赵六,面试官会做一件事:把赵六和名单上的“每一个”人进行比对,他会问:“赵六等于张三吗?”(赵六=张三?),“赵六等于李四吗?”(赵六=李四?),“赵六等于王五吗?”(赵六=王五?),只要有一次比对成功(比如赵六正好就是李四),他就会立刻说:“是的,他等于名单中的任何一个(= ANY)。” 如果比对了所有名字都不匹配,他就说:“不,他不等于名单里的任何一个。”
我们把这个比喻变成实际的SQL例子,假设我们有两张表:
学生表 (Students): 存放所有学生的信息。获奖表 (Awards): 存放获奖记录,里面有一个学生ID字段关联到学生表。
| 学生ID | 学生姓名 |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 获奖ID | 学生ID | 奖项名称 |
|---|---|---|
| 101 | 1 | 数学竞赛一等奖 |
| 102 | 2 | 作文比赛优秀奖 |
| 103 | 1 | 三好学生 |
找出所有获过奖的学生(不管获了什么奖)。

用EXISTS怎么写:
SELECT * FROM Students s
WHERE EXISTS (
SELECT 1 FROM Awards a
WHERE a.学生ID = s.学生ID
);
这个查询的过程就是:
- 从
Students表拿出第一个学生,比如张三(学生ID=1)。 - 然后执行EXISTS子查询:去
Awards表里找,看看“有没有”任何一条记录的学生ID等于1。 - 一找,发现有一条记录(数学竞赛一等奖),好了,任务完成!子查询立刻返回“TRUE”(存在)。
- 主查询就把张三这条记录放到结果集里。
- 接着处理李四,同样在获奖表里找到了记录,也放入结果集。
- 处理王五时,子查询在获奖表里找不到
学生ID=3的记录,返回“FALSE”(不存在),主查询就跳过王五。
注意: EXISTS后面的子查询里,SELECT 1或者SELECT *甚至SELECT ‘随便什么’都可以,因为EXISTS根本不关心你返回什么数据,它只关心子查询能不能返回至少一行记录,这是一种“半连接”特性,查到就停,效率通常很高。
用= ANY怎么写这个查询呢?这里就需要变通一下,因为= ANY需要一个明确的列表来比较,我们不能直接把整个表塞进去,通常我们会用子查询先构造出这个列表,我们想找“学生ID等于获奖表中所有学生ID里的任何一个”的学生。
SELECT * FROM Students s
WHERE s.学生ID = ANY (
SELECT a.学生ID FROM Awards a
);
这个查询的过程是:

- 先执行子查询
SELECT a.学生ID FROM Awards a,得到一个结果列表:[1, 2, 1]。 - 然后主查询开始工作,拿出学生张三(ID=1)。
- 问:1 = ANY ([1, 2, 1]) 吗? 也就是,1是否等于列表中的1、2或1中的任何一个?是的,第一次比较就匹配了。
- 所以张三被选中。
- 同样,李四(ID=2)也与列表中的2匹配,被选中。
- 王五(ID=3)与列表里的1、2、1都不相等,所以不被选中。
在这个例子里,两者达到了相同的效果,但它们的底层逻辑是不同的。
凸显区别的场景——处理NULL值。
假设获奖表里有一条记录的学生ID是NULL(可能是因为录入错误)。
| 获奖ID | 学生ID | 奖项名称 |
|---|---|---|
| ... | ... | ... |
| 104 | NULL | 神秘奖 |
现在我们再执行上面的两个查询。
-
EXISTS查询:完全不受影响,当它检查某个学生时(比如王五,ID=3),它只是在问获奖表里“有没有”
学生ID=3的记录,那条学生ID为NULL的记录,因为3 = NULL这个判断本身的结果是未知(NULL),所以不会被算作匹配项,EXISTS只关心有没有匹配成功的行,既然没有行匹配成功(NULL不算匹配),结果就是FALSE,王五依然不会被选出来,整个查询结果和之前一样。
-
= ANY查询:这时就可能出问题了,子查询得到的列表变成了:
[1, 2, 1, NULL]。 现在问:王五的ID(3) = ANY ([1, 2, 1, NULL]) 吗? 这个比较过程是:3=1? False; 3=2? False; 3=1? False; 3=NULL? 结果是Unknown(未知)。 在SQL的逻辑中,= ANY只要列表中有一个比较结果是True,就返回True,但如果没有任何一个比较是True,而是Unknown(因为遇到NULL),最终结果不会是True,而是Unknown,而WHERE条件只接受True,所以王五还是不会被选出来。在这个特定例子下,结果看似也没问题。我们换一个问法,假设我们问一个奇怪的问题:“找出那些ID不等于获奖表中所有学生ID的学生”,我们用
<> ALL(它等价于NOT (= ANY))。-- 找出从未获过奖的学生(错误写法,因为NULL) SELECT * FROM Students s WHERE s.学生ID <> ALL ( SELECT a.学生ID FROM Awards a );我们期望找到王五(ID=3),子查询列表是
[1, 2, 1, NULL]。 现在问:3 <> ALL ([1, 2, 1, NULL]) 吗? 意思是,3必须不等于列表里的“每一个”元素。 3<>1? True; 3<>2? True; 3<>1? True; 3<>NULL? 结果是Unknown。 因为<> ALL要求所有比较结果都是True,现在有一个是Unknown,整个结果就不是True了,而是Unknown,所以王五不会被选出来!这显然不是我们想要的结果,而如果用NOT EXISTS来写,就不会有这个困扰。
- 思维角度:EXISTS是“存在性检查”,= ANY是“逐值比较”。
- 效率:在大多数情况下,当子查询结果集很大时,EXISTS(关联子查询)的性能更好,因为它一旦找到匹配就可以停止扫描,而= ANY通常需要先物化整个子查询的结果列表(当然现代数据库优化器很智能,可能会进行转换)。
- 对NULL值的处理:EXISTS更稳健,当子查询的结果可能包含NULL值时,= ANY(及其反面NOT IN / <> ALL)很容易产生非预期的结果,因为任何值与NULL比较都是Unknown,会影响最终逻辑判断,EXISTS由于不直接进行值比较,只是检查行是否存在,所以能避免这个问题。
- 灵活性:EXISTS更灵活,它可以构建非常复杂的关联条件(比如在子查询的WHERE里用AND连接多个表),而= ANY通常只用于单字段与一个列表的比较。
个人建议是:凡是涉及到判断是否存在关联记录的查询,优先考虑使用EXISTS,它意图更清晰,且能有效规避NULL值带来的坑,而= ANY在简单的、确定的数值或字符串列表比较中,读起来可能更直观。
(根据《SQL权威指南》等经典教材中的概念和常见数据库(如MySQL, PostgreSQL)的行为进行说明)
本文由盘雅霜于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/68674.html