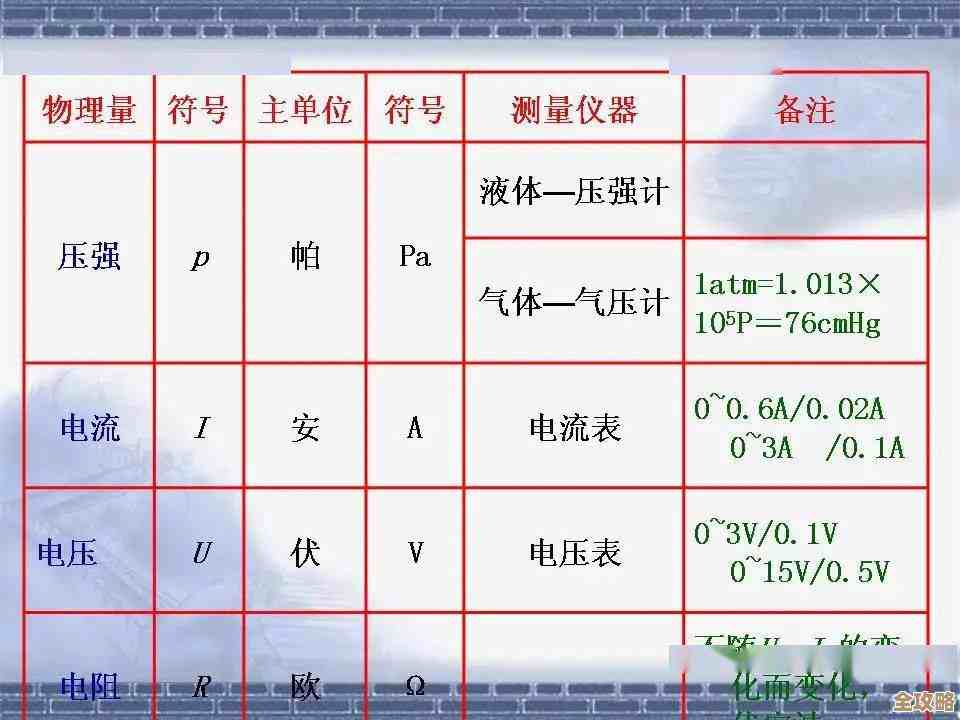
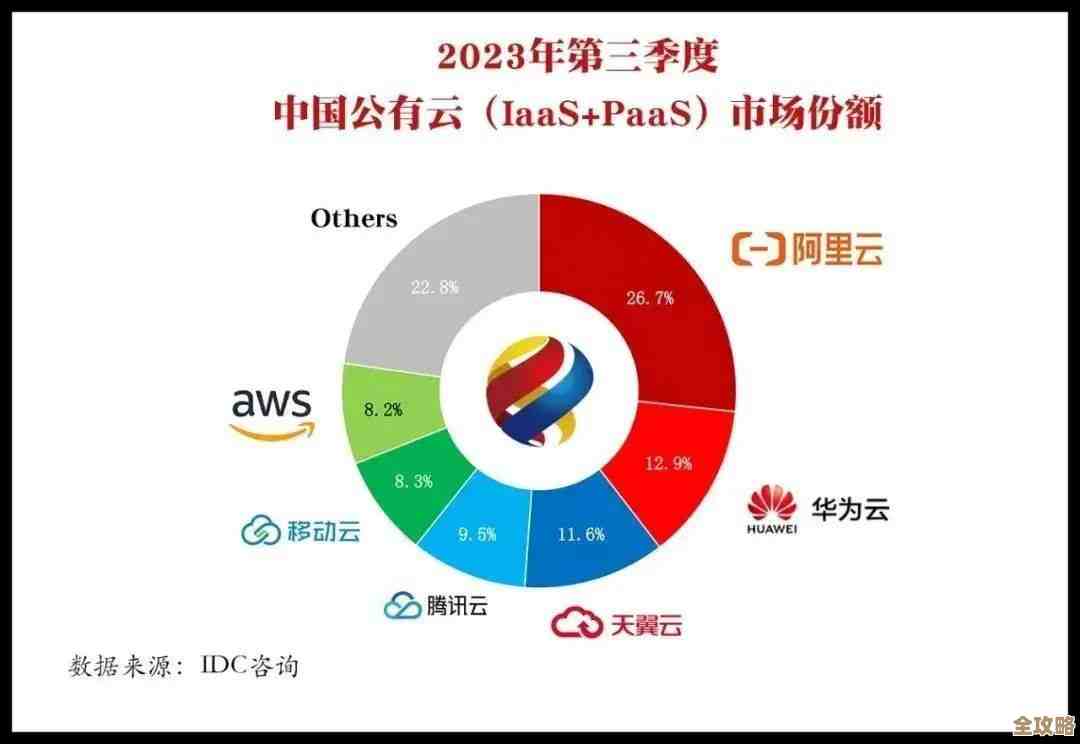
云计算基础设施需求忽上忽下,到底是啥原因让人摸不着头脑

“云计算基础设施需求忽上忽下,到底是啥原因让人摸不着头脑”,这个问题其实困扰着很多使用云服务的公司和技术团队,感觉就像天气一样,明明看着是晴天,突然就来一场暴雨,让人措手不及,这背后并不是单一的原因,而是多种因素像几股绳子一样拧在一起,共同作用的结果。
最直接、最常见的原因就是业务本身天然有波峰和波谷,很多行业的生意就不是平平淡淡的,做电商的,平时可能挺平稳,但一到像“双十一”、“黑色星期五”这种大促销的日子,访问量和交易量会瞬间飙升到平时的几十甚至上百倍,这就像春节期间的高速公路,突然涌入了海量的车流,再比如,在线视频网站,一部热门剧集更新的那一刻,或者有重大体育赛事直播的时候,同时在线观看的人数会爆炸式增长,还有做在线教育的,白天可能用户不多,但到了晚上和周末,学生都放学回家了,登录上课的并发量就会猛增,这些都不是意外,是业务特性决定的,但波动的剧烈程度依然常常超出预期,让负责基础设施的人感到压力巨大。(根据亚马逊云科技和阿里云对电商峰值案例的常见分析)
现代软件开发和发布的方式也加剧了这种不确定性,以前可能几个月才发布一个新版本,现在讲究的是“敏捷开发”和“持续部署”,一天之内可能就会上线好几个小更新,每一次代码发布、功能上线,都可能带来流量的变化,一个新功能突然成了爆款,吸引了大量用户来试用,资源消耗自然会猛增,反过来,如果一次更新出了bug,可能导致服务不稳定,需要快速回滚版本,这个过程本身也会引起资源分配的混乱,更不用说,很多公司会做A/B测试,即同时让一部分用户用A版本,另一部分用B版本,来看哪个效果更好,这种并行的流量也会让资源需求变得复杂和难以预测。(源自对现代DevOps实践和持续部署模式的观察)
第三个原因有点“自己给自己找麻烦”的意思,那就是云服务本身太方便、太灵活了,正是因为云计算的弹性伸缩能力,使得很多团队不再像过去使用物理服务器时那样,需要经过漫长的申请、采购、上架流程,现在只需要点几下鼠标或者写一行配置代码,几分钟内就能创建出大量的虚拟服务器,这种便利性是一把双刃剑,一方面它能快速应对需求高峰,但另一方面,它也容易导致资源的“无序扩张”,一个开发人员为了测试,临时开启了几台高性能的测试服务器,但测试完后忘记关闭了,这些资源就会一直空转,产生不必要的费用,或者,一个自动伸缩策略设置得过于激进,可能因为一个微小的流量波动就触发扩容,等流量回落后,缩容策略又比较保守,导致资源长时间闲置,这种由于人为疏忽或配置不当造成的资源浪费和需求波动,在云环境中非常普遍。(根据Flexera每年发布的《云现状报告》中关于云资源浪费的常见原因分析)
第四,来自外部的、不可控的“黑天鹅”或“灰犀牛”事件也会猛烈冲击基础设施,突然爆发的社会热点新闻,会让相关的资讯APP或网站流量瞬间暴涨;一次全球性的网络安全事件,可能导致扫描和恶意攻击流量激增,这些恶意流量虽然不产生价值,但同样会消耗大量的带宽和防护资源;甚至是一次区域性的网络运营商故障,也可能导致流量路径发生变化,使得原本负载均衡的架构出现单点压力过大的情况,这类事件无法提前精准预测,但其影响却是实实在在的,直接压在云计算基础设施上。(参考了Cloudflare等网络服务商对突发流量事件的分析报告)
监控和预测工具的局限性也是一个因素,虽然现在有很多先进的监控工具能实时显示CPU、内存、网络的使用情况,但它们更多是告诉你“现在正在发生什么”,对于“接下来会发生什么”的预测,仍然有很大挑战,机器学习模型预测的准确性依赖于历史数据,但如果业务在快速创新,历史模式可能不再适用,或者,一些微小的、关联性的异常指标没有被及时捕捉到,等它们累积起来引发大问题时,已经需要紧急扩容来应对了,这种从“看到问题”到“理解原因”再到“采取正确行动”之间的时间差,也是让人感觉需求“忽上忽下”、难以捉摸的原因之一。
云计算需求之所以像坐过山车,是业务的内在节奏、快速的软件迭代、云平台自身的灵活性、外部世界的突发事件以及我们认知工具的局限共同导演的一出戏,它不是一个能彻底解决的“问题”,而是一个需要持续管理和优化的“新常态”,摸不着头脑的感觉,正是因为我们身处一个复杂、动态的系统之中,唯一能做的就是不断提升对这个系统的观察、理解和响应能力。

本文由帖慧艳于2025-12-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/67154.html