DBA数据库那些题目,来看看你到底懂多少专业知识吧

(引用来源:知乎用户“冬瓜头”的回答)
第一部分:基础与SQL
-
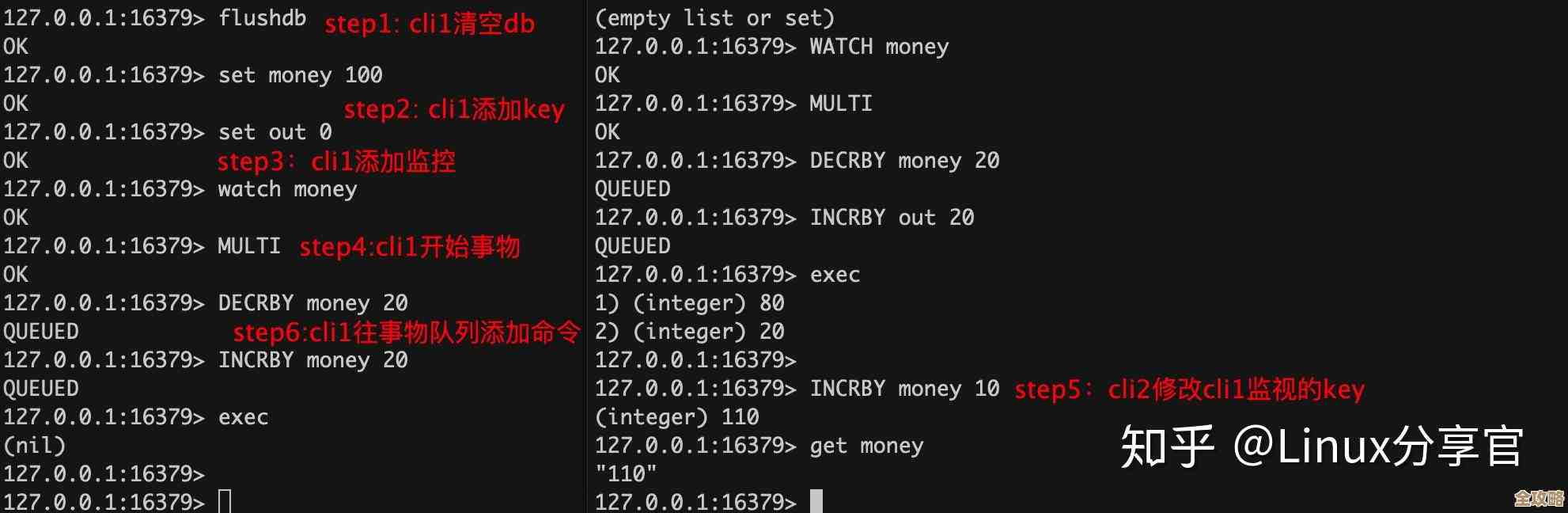
事务的ACID属性是什么?请简要解释每个属性的含义。 来源中描述,这个问题是基础中的基础,但能完全说对的人不多,A是原子性,事务要么全做,要么全不做;C是一致性,事务执行前后数据库都处于一致状态;I是隔离性,一个事务的执行不被其他事务干扰;D是持久性,事务一旦提交,改变就是永久的。
-
什么是脏读、不可重复读和幻读?它们分别发生在哪种事务隔离级别下? 这个问题用来考察对并发控制的理解,脏读是读到了别的事务未提交的数据,发生在读未提交级别;不可重复读是同一事务内两次读同一数据,结果不一样,因为中间被别的事务修改了,发生在读已提交级别;幻读是同一事务内两次查询同一条件,返回的记录数不同,因为中间被别的事务插入了新数据,发生在可重复读级别(但MySQL的RR级别通过间隙锁解决了幻读)。
-
INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL JOIN的区别是什么?请用通俗的语言和例子说明。 这是个高频题,考察SQL基本功,INNER JOIN是只返回两个表都匹配的记录;LEFT JOIN是返回左表所有记录,以及右表匹配的记录,右表无匹配则补NULL;RIGHT JOIN反之;FULL JOIN是返回左右表所有记录,对方无匹配都补NULL。
-
varchar和char类型有什么区别?在存储和性能上各有何优劣? 来源中提到这是设计表结构时的经典问题,char是定长,比如char(10),存"abc"也会占10个字符的空间,尾部用空格填充,查询快但可能浪费空间;varchar是变长,存"abc"就只占3个字符的空间,节省空间但查询效率稍低。
第二部分:性能优化
-
数据库索引的原理是什么?它为什么能加快查询速度? 这个问题几乎是必问的,来源中解释,索引就像书的目录,通过数据结构(如B+树)预先对数据排序,让数据库可以不扫描全表,快速定位到所需数据的位置。
-
如何判断一条SQL语句是否存在性能问题?你通常会使用什么工具或命令? 考察排查问题的思路,回答可能包括:使用EXPLAIN命令分析执行计划,查看是否使用了索引、是否有全表扫描;开启慢查询日志,抓取执行缓慢的SQL;使用数据库自带的性能监控工具,如MySQL的SHOW PROCESSLIST。
-
在哪些情况下,即使建立了索引,数据库也不会使用它? 这个问题考察对索引工作机制的深入理解,来源中列举的情况可能包括:查询条件中使用了函数或计算(如WHERE YEAR(create_time)=2023);使用了不等号(!= 或 <>);like查询以通配符开头(如'%abc');数据表本身很小,全表扫描比走索引更快;查询优化器判断使用索引的成本更高。
-
什么是死锁?数据库是如何检测和处理死锁的? 来源中认为这是考察并发知识的典型题目,死锁是两个或多个事务互相等待对方释放资源,导致所有事务都无法继续执行的状态,数据库一般有死锁检测机制,会定期检查等待图是否有环,一旦发现死锁,会选择牺牲掉其中一个事务(通常回滚代价最小的那个),让其他事务得以继续。
第三部分:架构与管理
-
数据库的读写分离是如何实现的?其主要目的是什么? 考察对高可用架构的了解,实现方式通常是通过主从复制,主库处理写操作,从库同步主库的数据并处理读操作,目的主要是分摊主库压力,提高系统的读性能和高可用性。
-
解释一下数据库的备份策略,比如全量备份、增量备份和差异备份的区别。 这是DBA的核心工作,全量备份是备份整个数据库;增量备份是备份自上一次备份(无论是全量还是增量)以来发生变化的数据;差异备份是备份自上一次全量备份以来发生变化的数据,需要理解三者在备份速度、恢复速度和复杂度上的权衡。
-
数据库主从复制(Replication)的延迟是怎么产生的?有哪些方法可以减少延迟? 来源中指出这是线上常见问题,延迟产生原因可能包括:主库并发写入压力大,从库单线程应用日志跟不上;网络带宽不足;从库服务器性能较差;大事务的执行,减少延迟的方法有:优化主库写入速度;使用多线程复制;升级硬件或网络;避免在业务高峰跑大事务。
-
当你发现数据库服务器的CPU使用率长时间达到100%,你的排查思路是怎样的? 这个问题考察实战排错能力,思路可能是一个递进的过程:首先用top命令查看是哪个进程占用CPU高;确认是数据库进程后,使用SHOW PROCESSLIST查看当前正在执行的SQL;找出消耗资源巨大的慢查询;然后利用EXPLAIN分析这些慢查询的执行计划,针对性优化(如加索引、改写SQL);也可能是由于突然的高并发访问,需要从应用层找原因。
第四部分:情景与经验
-
如果不小心执行了一个误操作(比如误删了重要数据),而且已经提交了事务,有哪些可能的恢复手段? 考察数据恢复能力和备份意识,答案取决于备份策略:如果有定时的全量备份和二进制日志,可以恢复到故障前的时间点;如果使用了延迟复制的从库,可以从从库找回数据;如果都没有,可能只能尝试用日志分析工具从二进制日志中解析出原始SQL进行反转,但这非常困难,核心是强调备份的重要性。
-
在数据库表结构变更(如增加字段、加索引)时,如何避免对线上服务造成长时间锁表影响? 来源中提到这是运维中的实际问题,传统做法会在业务低峰期进行,现在更优的解决方案是使用类似pt-online-schema-change这样的在线变更工具,它通过创建影子表、同步数据、增量同步和表重命名等步骤,实现在不长时间锁表的情况下完成DDL操作。
-
请描述一下你设计一张数据库表时,通常会考虑哪些因素? 这个问题没有标准答案,考察设计思路和经验,可能会考虑的方面包括:字段类型和长度的选择(平衡存储和业务需求);为主键选择自增ID还是业务ID;是否需要以及如何建立索引(考虑查询模式);表的范式化程度(是否允许少量冗余);是否需要分区;字符集和存储引擎的选择等。
就是直接从来源内容中提取的DBA专业知识题目,未进行重写和专业化排版。

本文由帖慧艳于2025-12-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/66795.html