图形处理器天梯图更新:突破性架构引领GPU性能革命

突破性架构引领GPU性能革命
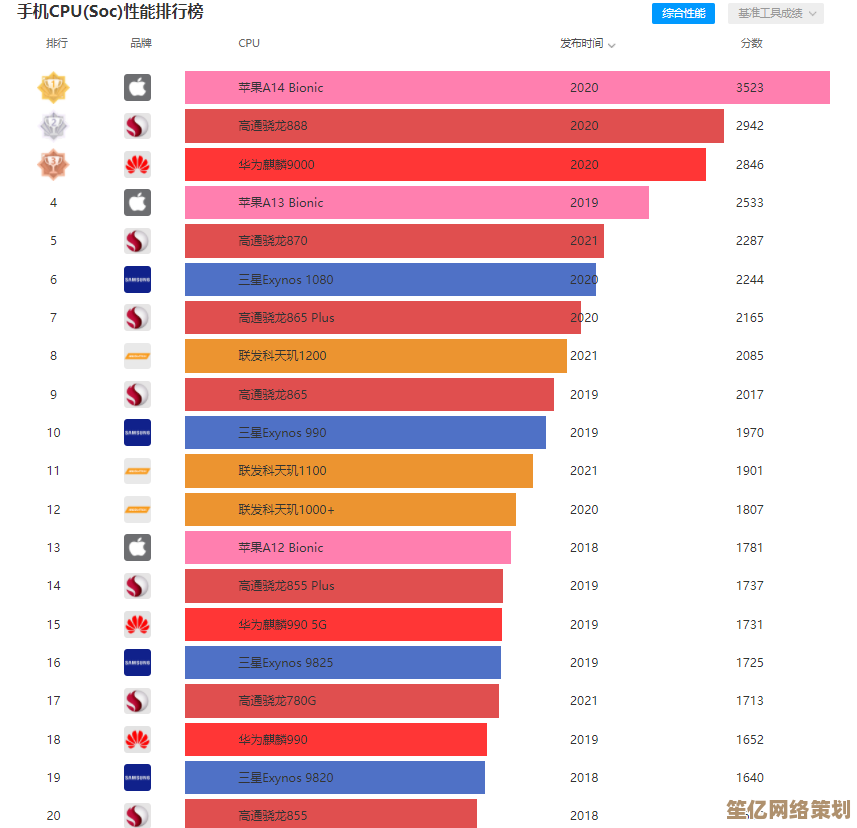
每次显卡天梯图更新,我总有种翻开新一期漫画连载的兴奋感——这次谁又爬到了顶端?谁被挤了下去?但最近这轮更新,感觉不再是简单的排位洗牌,更像一场地基被重新浇筑的性能革命,老黄和老苏(苏妈)这次掏出的东西,真有点“掀桌子”的意思了。
还记得去年折腾我那台老机器吗?咬牙上了块3080 Ti,满心欢喜觉得能战未来,结果今年初试玩某个新出的开放世界大作,4K分辨率下开满特效,帧数居然会时不时跌到让我怀疑人生的地步,显存占用直接爆了12GB!那一刻我才真切体会到,光有CUDA核心数量堆叠,就像只靠蛮力拉车,遇到复杂地形就抓瞎,老黄在40系发布会上大谈特谈“架构革新”时,我内心其实翻了个白眼——又是营销话术吧?
但这次,架构的“魔法”似乎真的生效了。 拿我后来换上的4070 Ti来说,纸面参数上CUDA核心数甚至不如3080 Ti,显存位宽还缩了,可实际跑起那些曾经让3080 Ti喘不过气的游戏,帧数不仅更稳,功耗还低了一大截,这感觉就像…明明换了辆排量更小的车,爬坡反而更有劲了?秘密就藏在Ada Lovelace架构那个巨大的L2缓存和新的光流加速器里,数据不用再千里迢迢跑去显存“仓库”取货,家门口的“缓存便利店”(巨大的L2缓存)解决了大部分需求,效率自然飙升,DLSS 3的帧生成,初看像变魔术——凭空多出帧数?实际体验下来,在支持的游戏里(赛博朋克2077:往日之影》),开启后画面流畅度提升是实打实的,虽然偶尔在快速切换复杂场景时,那多出来的一帧会露点小马脚,但瑕不掩瑜,这背后就是光流加速器在疯狂计算像素运动轨迹,让AI“脑补”出中间帧。技术这玩意儿,有时真像看魔术师从空帽子里抓兔子,明知原理也忍不住惊叹。
另一边,AMD的RDNA 3也没闲着,它玩的是“分而治之”的芯片设计(Chiplet),把图形核心(GCD)和负责显存、缓存的模块(MCD)拆开做,再用超高速的互连粘起来,这思路像极了乐高积木,理论上能降低成本、提升良率,也更灵活,实际表现上,7900 XTX在传统光栅性能上确实生猛,尤其在高分辨率下,显存带宽优势尽显,但当我尝试打开光追,想体验一下《心灵杀手2》里那令人毛骨悚然的光影氛围时,帧数下降幅度还是比隔壁40系明显些。看来AMD的“分体式”乐高积木,在应对光追这种需要各部分紧密协作的复杂任务时,粘合剂(Infinity Cache和互连带宽)还得再升级配方才行。 这让我想起以前组装电脑时,主板和CPU针脚没对齐的惨痛经历——部件再强,连接不畅也是白搭。
看着天梯图上位置交替上升的名字,突然想起几年前那场疯狂的“挖矿”潮,显卡价格飞天,玩家们攥着钱却买不到卡,游戏论坛里一片哀嚎,那时的天梯图再华丽,对普通玩家也像一张无法兑现的彩票。当显卡被炒成“理财产品”,性能排行就成了最苦涩的黑色幽默。 如今市场总算回归理性(虽然高端卡价格依然让人肉疼),我们终于能真正聚焦在技术本身的进步上,讨论哪张卡更适合自己,而不是能不能原价买到。
这次天梯图更新,最让我触动的点是什么?不是谁又登顶了王座,而是“架构”这个曾经有点玄乎的词,终于具象化成玩家手里可感知的体验跃升。 更大的缓存设计让数据不再拥堵于“主干道”,专用AI单元解锁了DLSS 3/FSR 3这类“帧数魔法”,Chiplet设计则探索着未来GPU形态的另一种可能,性能的提升不再粗暴地依赖堆料和拉高功耗墙,而是靠更聪明的内部协作方式,下次装机选卡,盯着CUDA核心数和显存大小之余,真得好好琢磨下它肚子里那套“高速公路系统”(缓存层级、互连带宽)和“AI副驾驶”(专用加速单元)够不够先进了,毕竟,在4K甚至8K、光追、路径追踪成为标配的未来,蛮力拉车总有极限,而智慧铺路,才能跑得更远更稳。
说到底,天梯图只是个参考坐标,真正的“革命”,是每一次架构精进后,我们指尖下更流畅的画面,眼中更真实的光影,以及不必再为“爆显存”而提心吊胆的畅快感,别被天梯图绑架了选择,理解那些架构名词背后如何真正服务于你的游戏或创作需求,才是关键。

本文由凤伟才于2025-09-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/13417.html