构建稳健服务器架构:驱动企业网络效率升级的关键路径

说到构建服务器架构 这事儿吧,其实挺磨人的,很多企业一上来就想着要最牛的技术、最炫的架构,恨不得把所有流行词都塞进去…微服务、容器化、云原生,听起来是挺唬人的,但真上手了才发现,一堆坑等着呢,我见过太多项目,开局轰轰烈烈,最后因为底层架构没撑住,天天救火,团队累得人仰马翻。
真正的关键路径,我觉得反而不是那些高大上的东西,而是怎么让架构“站得住”,什么叫站得住?就是别动不动就崩,别用户一多就卡,出了问题能快速找到根儿,而不是半夜三更让运维对着日志发呆,这听起来简单,做起来全是细节。
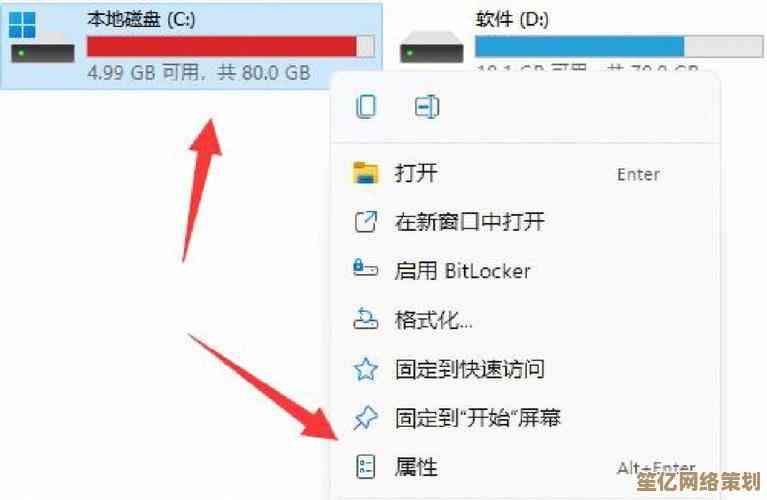
你选型的时候,是跟着感觉走,还是真摸清了自家业务的脾气?有一次我们给一个电商项目做架构评审,技术团队非要上某个特别新的数据库,说性能爆表,结果呢,业务高峰期来了几个突发的促销活动,那个数据库的某种特定查询直接锁死,整个下单链路全挂,后来复盘才发现,这数据库在超高并发写入时,对某类事务的支持有隐藏瓶颈,文档里根本没提,所以啊,稳定性有时候是“试”出来的,甚至是用教训换来的,光看纸面参数,真的不够。
还有容灾,好多团队觉得“我们业务量没那么大,备份一下就行了”,但备份和容灾是两码事,备份是留个底,容灾是怎么快速切过去、而且保证数据不丢,我记得有个客户,服务器在机房被施工队挖断了光缆,停了大半天,其实他们数据有备份,但恢复流程一团乱,权限混乱、脚本失效,等系统终于能访问了,客户早就跑光了,所以冗余不是摆设,得经常拉出来练练,做做故障演练,模拟一下硬盘坏了、网络断了、甚至整个机房宕了怎么办,平时多流汗,战时才能少流血,这话放在这儿特别对。
再说说监控,这东西太重要了,但也是最容易被应付的环节,堆一堆指标、告警,看起来挺全,真出问题的时候,告警邮件像雪片一样飞过来,反而不知道先看哪个,好的监控得能讲故事,能告诉你问题是怎么发生的、从哪儿开始的,我们之前优化过一个系统,就是把监控重点从“CPU高了、内存满了”这种表象,转移到关键业务链路的延时和错误率上,再结合日志和链路追踪,一下子就能定位到是哪个服务、甚至哪行代码拖了后腿,这就好比看病,不能光说发烧,得找到是哪里发炎引起的。
还有一点是人的问题,架构再稳,也经不住乱改,有时候开发图省事,或者为了赶进度,绕过规范直接上线,埋下各种雷,所以流程上得有些“笨”办法,比如上线前必须做压力测试,关键变更要有回滚方案,甚至强制代码审查,一开始有人嫌烦,但时间长了,大家反而安心了,因为知道系统不会因为某个手滑就崩掉。
吧,构建稳健的服务器架构,没什么一招鲜的秘籍,它更像是一个不断打磨、持续调整的过程,你得理解自己的业务到底需要什么,不能贪多求快,得耐着性子把基础打牢,故意留点缓冲、做点冗余,反而比追求极致的效率更划算,毕竟,网络效率的升级,最终是为了生意能平稳跑下去,而不是为了架构图看起来漂亮,稳,才是最大的效率。

本文由腾掣于2025-10-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/yxdt/30818.html
![[QQ邮箱登录]新体验:安全便捷的电子邮箱登录服务全面升级](http://waw.haoid.cn/zb_users/upload/2025/10/20251018155252176077397249247.jpg)