Redis怎么快速知道挂了没,保证它一直安全运行的那些事儿

关于Redis如何快速知道是否挂了,以及保证它一直安全运行,可以从监控、高可用、日常维护和安全配置几个方面来谈,这里综合了Redis官方文档、一些技术社区的最佳实践以及常见运维经验。
怎么快速知道Redis挂了?
核心思想是建立主动和被动的监控告警体系,不能等用户投诉了才发现。
-
心跳检测(Ping-Pong检查):这是最基本、最直接的方法,通过一个定时任务(比如每5秒一次),用
PING命令连接Redis服务器,如果服务器返回PONG,说明服务正常;如果连接超时或返回错误,就认为可能出现了问题,很多监控工具(如Zabbix, Prometheus, Datadog)或自己写的脚本都能做这个事,这是最基础的存活检查。 -
关键指标监控:光是能
PING通还不够,还得看它是否“健康”,需要监控一些关键指标,这些指标可以通过Redis的INFO命令获取:- 内存使用率:这是Redis最容易出问题的地方,监控
used_memory和maxmemory,如果使用率超过80%或90%,就需要告警,防止内存写满导致数据丢失或服务拒绝。 - 连接数:监控
connected_clients,如果连接数突然暴涨或接近maxclients的限制,可能意味着有客户端异常或遭受了连接攻击。 - 阻塞客户端数:关注
blocked_clients,如果这个数字长时间不为0,可能表示有慢查询或使用了阻塞命令(如BLPOP),导致其他客户端排队。 - 持久化状态:如果使用了持久化(RDB或AOF),需要监控
rdb_last_bgsave_status和aof_last_bgrewrite_status是否为ok,以及最后一次持久化成功的时间,如果持久化持续失败,服务器重启会导致数据丢失。 - 主从复制状态:如果部署了主从,监控
master_link_status(从库视角)是否为up,以及master_repl_offset和slave_repl_offset的差值(复制延迟),复制中断或延迟过大,会影响数据的可靠性和故障切换。
- 内存使用率:这是Redis最容易出问题的地方,监控
-
日志监控:Redis的运行日志(
redis.log)是发现问题的重要来源,需要实时监控日志中的警告(WARNING)和错误(ERROR)信息,出现“OOM command not allowed when used memory > ‘maxmemory’”表示内存满了;“Background save error”表示持久化失败,将这些错误日志接入ELK等日志系统并设置告警。 -
外部业务探针:除了系统层面,还可以从业务角度设置探针,定时向Redis写入一个带时间戳的测试键值,再读出来校验,如果失败或延迟过高,就触发告警,这更能反映真实业务体验。

保证Redis一直安全运行的那些事儿
监控是为了发现问题,而以下措施是为了预防问题,确保稳定。
-
设置合理的内存淘汰策略:这是防止Redis被“撑死”的关键,不要等内存用满才处理,通过配置
maxmemory-policy,可以选择在内存不足时,是淘汰最近最少使用的键(LRU)、随机淘汰还是淘汰即将过期的键等,根据业务特点选择,比如缓存场景常用allkeys-lru。 -
做好持久化,但理解其取舍:Redis的持久化(RDB快照和AOF日志)是数据安全的基础,但会影响性能。

- RDB:生成快照,恢复快,但可能丢失最近几分钟的数据,需要根据业务容忍度配置
save参数(如save 900 1)。 - AOF:记录每一条写命令,数据完整性高,但文件大、恢复慢,可以配置
appendfsync everysec在性能和数据安全间取得平衡。 - 混合持久化(Redis 4.0+):结合两者优点,推荐使用,定期生成RDB快照,同时增量记录AOF日志。
- RDB:生成快照,恢复快,但可能丢失最近几分钟的数据,需要根据业务容忍度配置
-
搭建高可用架构:单点Redis故障必然导致服务中断,因此需要高可用方案。
- 主从复制(Replication):一个主节点,多个从节点,数据从主节点同步到从节点,这提供了数据备份和读请求分流的能力,但主节点故障时需要人工干预切换。
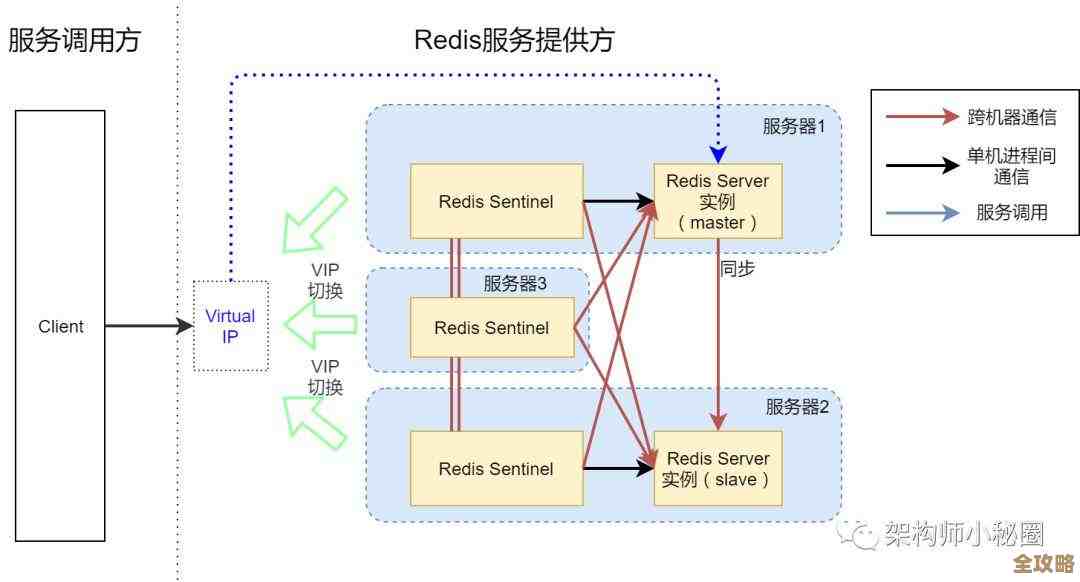
- 哨兵模式(Sentinel):在主从基础上,引入若干个哨兵进程来监控主从节点,当主节点被判断为故障时,哨兵会自动选举一个从节点提升为主节点,并通知客户端新的地址,实现自动故障转移,这是保证服务不中断的常用方案,根据官方文档,哨兵模式是Redis高可用的标准解决方案。
- 集群模式(Cluster):当数据量巨大或写压力很高时,可以使用官方集群模式,它将数据分片存储在多个主节点上,每个主节点又有对应的从节点,集群模式同时实现了数据分片、高可用和负载均衡,是应对更大规模场景的方案。
-
实施定期备份:即使有持久化和主从,对RDB文件或AOF文件进行定期异地备份仍然是最后的安全防线,备份策略应包含全量备份和增量备份,并定期进行恢复演练。
-
安全配置:
- 设置密码:通过
requirepass配置项为Redis设置一个强密码,防止未授权访问。 - 绑定网络接口:生产环境不要监听所有IP(
0.0.0),通过bind配置项只绑定内网IP。 - 禁用高危命令:通过
rename-command配置项,将FLUSHALL、FLUSHDB、CONFIG、KEYS等可能导致服务中断或数据丢失的命令重命名为一个随机字符串,甚至直接禁用,降低误操作和攻击风险。
- 设置密码:通过
-
运维规范:
- 容量规划:根据业务增长预估数据量和访问量,提前规划好内存和服务器资源。
- 慢查询监控:使用
SLOWLOG GET命令定期检查慢查询,并对超过一定阈值(如10毫秒)的命令进行优化,避免它们拖慢整个服务。 - 避免大Key和热Key:大Key(如一个哈希包含百万字段)会阻塞网络和持久化;热Key(一个Key被极高频率访问)可能导致单台服务器压力过大,需要通过设计或使用集群来分散。
要让Redis安全稳定运行,不能只靠一个方法,它需要一套组合拳:建立全面的监控告警系统(眼睛和警报)、配置合理的内存和持久化策略(内部调理)、搭建高可用架构(消除单点)、执行严格的安全配置和备份计划(设防和留后路),再加上良好的日常运维规范(定期体检),这样多管齐下,才能最大程度地确保Redis的持续健康运行。
(主要参考了Redis官方文档关于持久化、复制、哨兵、安全的章节,以及互联网技术社区如Redis中国用户组、Stack Overflow等常见的运维实践讨论。)
本文由度秀梅于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/85378.html