用Redis客户端想拿高性能,哪些坑和技巧得知道才行

用Redis客户端想拿高性能,确实有不少细节要注意,很多坑都是不知不觉踩进去的,直接说重点。
连接管理是个大坑。 千万别用一次连接就关一次,建立连接的成本很高,包括网络开销和认证,高性能的基石是使用连接池,根据你的业务线程数,配置一个大小合适的连接池,让连接能被复用,但池子也不是越大越好,过多的连接会消耗Redis服务器端资源,根据经验,通常设置成和业务线程数相当或略多就行,客户端和服务器之间的心跳(keepalive)要打开,防止长时间空闲被防火墙掐断连接,导致突然报错。

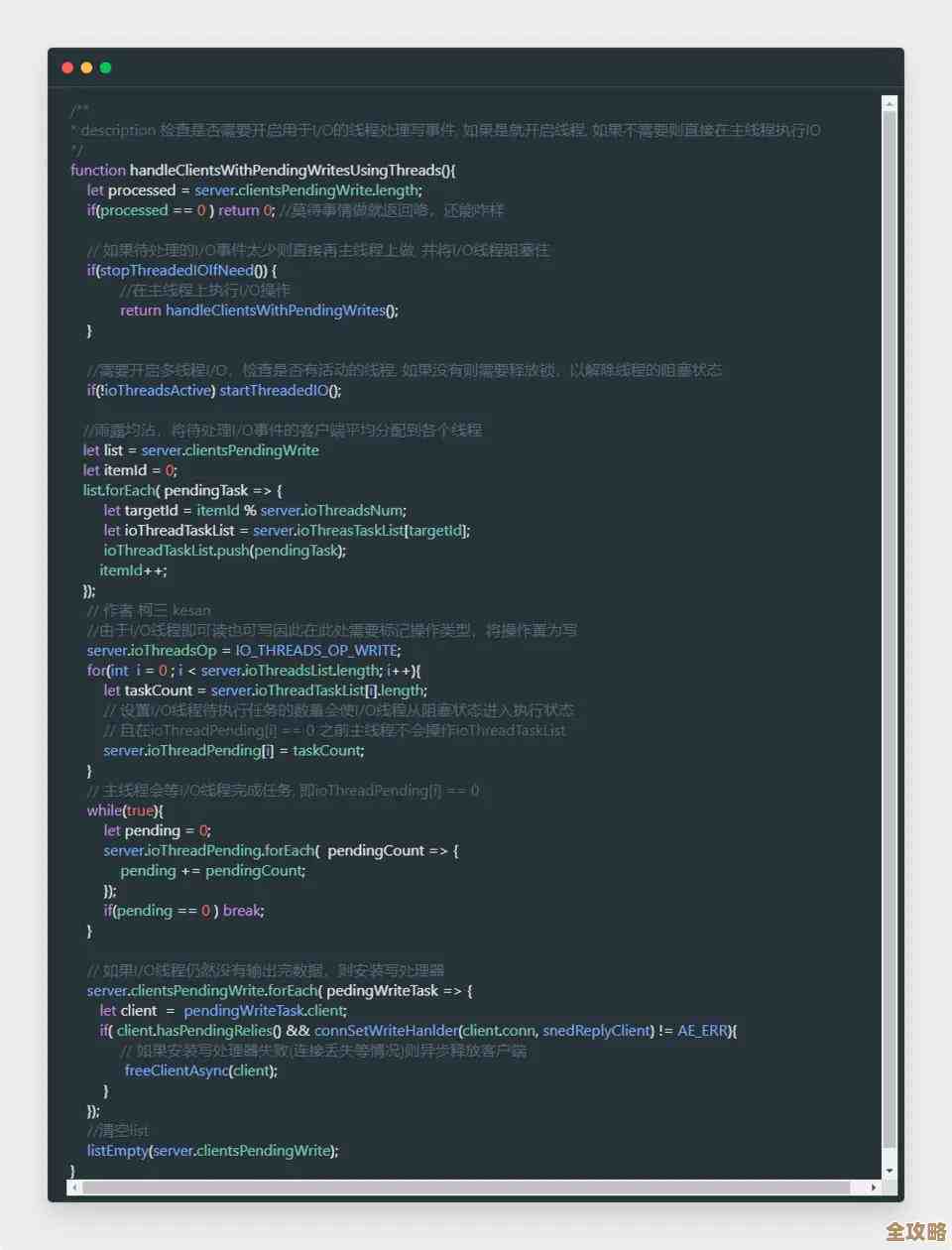
第二,命令的往返次数是性能杀手。 Redis快,但网络慢,一个命令发过去,等回复,再发下一个,这种“乒乓”模式效率极低,这里有两大法宝,一是管道(Pipeline),它能把多个命令打包,一次发过去,结果再一起收回来,极大减少了网络往返时间,写列表、批量设置数据时一定要用,但注意,管道内的命令数量也要控制,避免单次传输数据过大或长时间独占连接,二是批量命令,比如用MSET、MGET代替一堆SET和GET,用HMGET代替多次HGET,这些是Redis原生支持的,比管道更直观,效率也高。
第三,小心“慢”命令和过大Key。 有些命令本身就有性能风险,比如获取整个Hash的所有字段和值(HGETALL),如果这个Hash有几千个字段,返回的数据量会很大,既耗网络带宽,也增加客户端解析压力,应该用HSCAN迭代获取,或者只取需要的字段,再比如KEYS命令,在生产环境绝对禁止,它会遍历所有键,直接打挂Redis,要用SCAN系列命令代替,一个Key对应的Value体积不能过大(比如超过10KB),大Key在传输、序列化、内存分配时都会成问题,列表、集合元素太多也要考虑拆分。

第四,序列化方式影响很大。 客户端把数据发给Redis前要序列化成字节,收到后要反序列化,选对序列化协议很重要,像Java里,别直接用JDK自带的序列化,它又慢体积又大,可以考虑JSON(可读性好但速度体积一般)、MsgPack、Protocol Buffers,或者Redis客户端自带的优化过的序列化工具,核心原则是:序列化后的体积要小,编解码速度要快。
第五,合理设置超时与重试。 网络总可能出问题,必须给操作设置合理的超时时间,包括连接超时、读写超时,时间设太短,在正常网络波动时容易误判失败;设太长,一旦真出问题,线程会被长时间挂起,通常读写超时设成几百毫秒到几秒,根据业务容忍度来,配合重试机制,但重试次数不宜过多(比如1-2次),且最好有退避延迟(比如隔50毫秒再试),避免雪崩。
第六,关注客户端本身和监控。 不同语言的Redis客户端实现质量有差异,选一个活跃维护、口碑好的客户端,客户端的配置参数(像连接池参数、缓冲区大小)要根据压测结果调整,别忘了监控,通过Redis的INFO命令或监控工具,观察客户端连接数、命令耗时、网络输入输出流量,这些数据能帮你提前发现瓶颈。
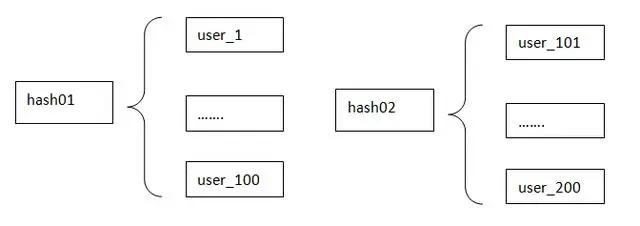
键名设计有讲究。 键名要短,但也要有一定可读性,比如用user:1000:profile而不是user_profile_1000,短键名能节省内存和网络带宽,尤其是在这个键被频繁访问的时候,但别为了短而完全失去可读性,用u:1k:p这种就有点过了,不利于维护。
拿高性能不是光靠Redis服务器快,客户端的使用方式至少占一半,管好连接、减少往返、避开慢操作、选对序列化、设好超时,这些点都做到了,性能自然不会差。

本文由召安青于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/85364.html