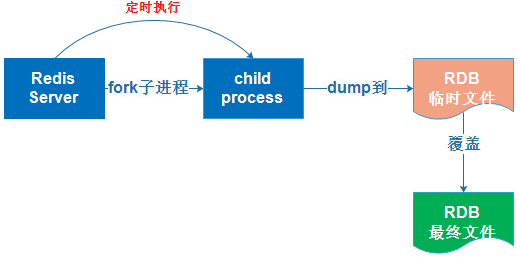
Redis里头那个IO复用技术到底怎么高效发挥作用,聊聊它的原理和应用

想象一下,你开了一家小餐馆,只有一个服务员,如果这家餐馆采用最原始的方式,也就是“阻塞IO”模式,那会是什么样子呢?一个客人点单,服务员就得一直站在他旁边,等他慢慢看菜单、纠结吃什么,直到点完单,服务员才能去服务下一桌,这期间,其他已经坐下的客人就算想加水、结账,也只能干等着,这效率太低了,餐馆根本接待不了几桌客人。
Redis就像一个要求超高效率的“数据餐厅”,它要同时处理成千上万个客户端的点单(也就是数据请求),如果它用上面那种笨办法,一个请求没处理完就啥也干不了,那它的速度根本快不起来,Redis用了更聪明的办法,这就是“IO复用”。
IO复用,简单说就是让一个“超级服务员”(Redis服务进程)可以同时照看多个“客人”(网络连接),而且这个服务员还不用傻等着。

这个“超级服务员”是怎么工作的呢?它不再主动去问每一个客人“你要点菜吗?”,而是把所有客人的需求都交给一个“大堂经理”来统一调度,在Linux系统里,这个“大堂经理”就有好几个名字,最常用的就是epoll。
它的核心原理是这样的:

-
建立名单,交给经理:当有新的客户端连接到Redis时,Redis不会立刻去读它发来的数据,而是把这个新连接的文件描述符(可以理解为客人的桌号)注册到
epoll这个“大堂经理”那里,并告诉经理:“帮我留意一下这个桌号,如果客人要点单了(也就是有数据可读了),你就通知我。” -
经理巡视,发现需求:Redis这个“超级服务员”就可以去休息一下(进入等待状态),把CPU资源让出来。
epoll经理开始工作,它会默默地巡视所有登记在册的“桌位”(连接),看看哪些客人已经举手下单了(连接上有数据到达了)。
-
批量通知,高效处理:
epoll经理不会有一个客人举手就立刻跑去找服务员,它会等一小会儿,或者等到有一定数量的客人都举手了,然后一次性把“有需求的桌号列表”交给Redis服务员,Redis服务员拿到这个列表后,就知道该去为哪几张桌子服务了。 -
按顺序服务,但速度极快:Redis服务员会按照列表,一张桌子一张桌子地去处理,先处理1号桌的读请求,从网络连接里把数据读进来,然后在内存中完成计算(比如查找一个键的值),再把结果写回给1号桌,接着立刻去处理5号桌、8号桌…… 这里有个关键点:Redis是单线程处理这些网络IO和命令执行的,你可能会觉得,单线程不是会慢吗?恰恰相反,这正是高效的关键,因为它避免了多线程之间切换、加锁带来的巨大开销,由于所有操作都在内存中完成,速度非常快,就算有几万个连接,每个请求的处理时间也极短,短到对于每个客户端来说,都感觉自己是被独占服务的。
这样一来,IO复用的高效性就体现出来了:
- 避免了空等:Redis进程再也不需要浪费CPU时间在那些还没有数据可读的连接上“干等着”,它大部分时间都在“休息”(等待
epoll的通知),一旦被唤醒,就全是“有效工作”。 - 批量处理:从“一个一个问”变成了“一批一批处理”,大大减少了来回切换的代价,就像服务员一次从后厨端出好几个菜,比分好几次端要高效得多。
- 单线程无锁化:配合单线程的内存操作,整个流程极其简洁、高效,没有复杂的并发问题。
在实际应用中, 正是因为这套机制,Redis才能实现极高的吞吐量(每秒处理数十万甚至上百万次请求)和极低的延迟,无论是作为网站的热点数据缓存、会话存储,还是消息队列,这种高效处理海量并发连接的能力都是Redis成功的基石。
Redis的IO复用技术,核心就是找了个厉害的“大堂经理”(如epoll)帮它盯梢,让它自己能从繁琐的等待中解放出来,只专注于处理真正有需求的客户,并且用单线程的方式把每个需求都处理得飞快,这就是它高效发挥作用的秘密。
本文由黎家于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/85031.html