用Redis缓存商品列表数据,提升浏览体验和响应速度探讨

在现代的电商网站或者带有商品展示功能的应用程序中,商品列表页是用户访问最频繁的页面之一,用户希望能够快速、流畅地浏览和搜索商品,任何卡顿或长时间的等待都可能导致用户失去耐心并离开,传统的做法是每当用户请求商品列表时,程序都直接去查询数据库,数据库虽然能稳定地存储数据,但当同时访问的用户非常多,或者商品数据量巨大时,频繁的数据库查询就会成为一个瓶颈,导致页面响应变慢,影响用户体验,为了解决这个问题,一个非常有效且广泛使用的技术就是引入缓存层,而Redis正是充当这一角色的理想选择。
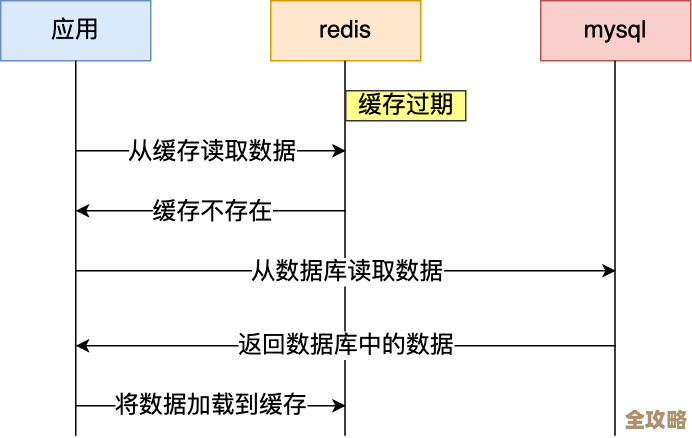
Redis是一个基于内存的数据存储系统,它的数据读写速度极快,远远超过基于硬盘的传统数据库,我们可以把Redis想象成是在应用程序和数据库之间设立的一个“高速临时仓库”,当用户第一次请求商品列表时,程序还是会去数据库查询数据,但在将查询结果返回给用户之前,会把这个结果复制一份,存放到Redis这个“高速仓库”里,并给这份数据设置一个有效期,比如10分钟。
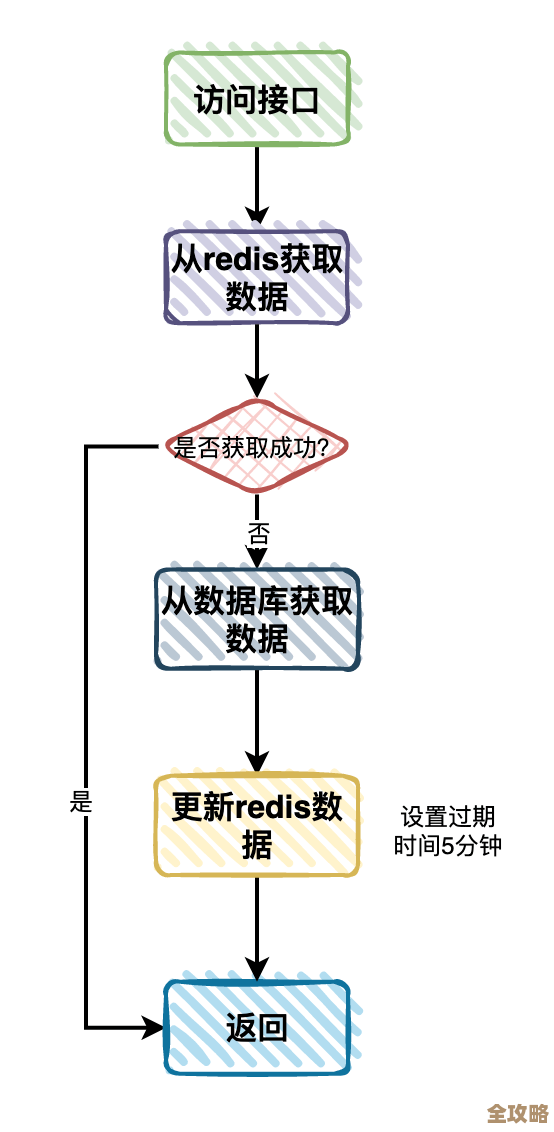
在接下来的10分钟内,如果再有其他用户(甚至包括同一个用户)请求完全相同的商品列表,程序就不再需要去麻烦数据库了,它会首先到Redis这个“高速仓库”里查看一下,发现已经有现成的数据了,便直接取出来返回给用户,由于所有的操作都在内存中完成,这个响应的速度非常快,通常能在毫秒级别完成,从而极大地提升了用户的浏览体验和页面的响应速度,这种“先查缓存,没有再查数据库”的模式,极大地减轻了数据库的压力。
具体如何用Redis来缓存商品列表数据呢?这个过程可以大致分为几步,我们需要一个唯一的标识来代表这次查询,这个标识通常由商品列表页的关键参数生成,例如分类ID、排序方式、页码、每页大小等,将这些参数组合成一个字符串,作为存储在Redis中的键(Key),而查询数据库得到的结果,即商品列表数据本身,就是值(Value),在存储之前,通常需要将数据序列化成JSON字符串这样的格式,以便于存储和读取,使用Redis的命令,比如SETEX,将这个键值对存储到Redis中,并同时设置好过期时间,当下次请求来时,用同样的规则生成键,先去Redis中尝试获取(GET),如果获取到了(我们称之为“缓存命中”),就直接反序列化后返回;如果没获取到(称之为“缓存未命中”),再执行数据库查询,并重复上述缓存的过程。
使用Redis缓存商品列表也并非一劳永逸,需要考虑一些关键问题,其中最核心的就是数据一致性问题,因为Redis里的数据是数据库数据的一个副本,它可能不是最新的,假设后台管理员修改了某个商品的价格或下架了某个商品,如果Redis中缓存的旧列表还没有过期,用户看到的就依然是过时的信息,为了解决这个问题,常见的策略有几个,一是合理设置缓存过期时间,让数据在一段时间后自动失效,然后重新从数据库加载,这对于不常变动的商品信息是可行的,二是主动清除缓存,当后台对商品数据进行增、删、改操作时,在完成数据库操作后,立即删除或更新与之相关的缓存数据,这样下次用户请求时,因为缓存不存在,就会去查询最新的数据库并重新缓存,这种方式能更好地保证数据的实时性,但对程序逻辑的要求更高。
除了数据一致性,缓存的设计也很重要,对于不同筛选条件下的商品列表(如按价格排序、按销量排序),应该缓存成不同的键,以确保数据的准确性,要预防缓存穿透问题,即频繁查询一个根本不存在的数据(比如一个不存在的商品ID),导致请求每次都绕过缓存直接访问数据库,解决方法可以是对不存在的结果也进行短暂缓存,还有缓存雪崩,即大量缓存数据在同一时间点过期,导致所有请求瞬间涌向数据库,可以通过为缓存过期时间设置一个随机波动值来避免。
通过引入Redis作为缓存层来存储商品列表数据,是一种非常有效的提升系统性能和用户体验的手段,它利用内存的高速读写特性,将最常访问的数据放在离用户“更近”的地方,显著减少了数据库的访问压力,加快了页面的响应速度,虽然在实现时需要仔细处理数据一致性等挑战,但只要设计得当,Redis能够为商品浏览这类高并发场景提供稳定而强大的支持。

本文由钊智敏于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84807.html