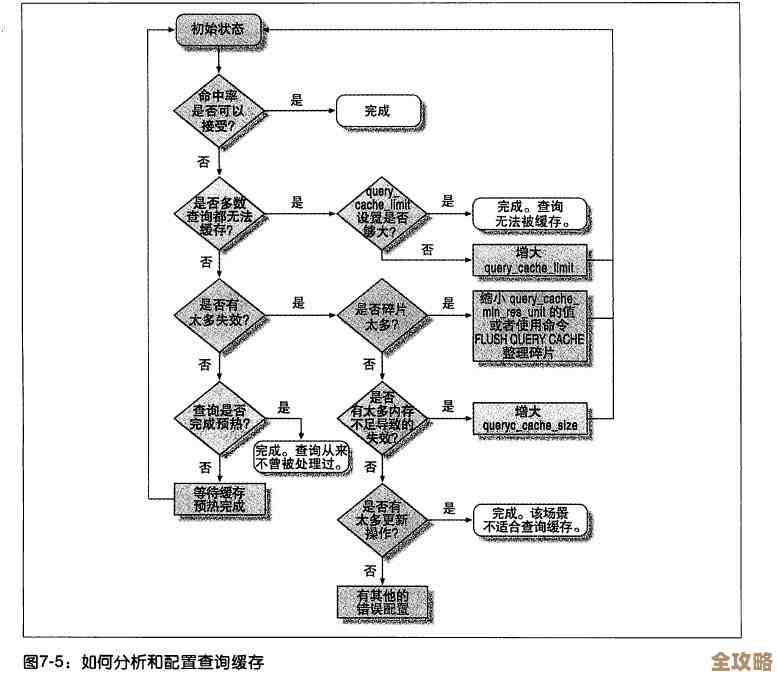
ORA-09938信号处理失败,Oracle报错紧急修复远程支援方案分享

ORA-09938错误是一个与Oracle数据库后台进程(特别是后台进程与操作系统内核交互时)相关的严重错误,它的完整错误信息通常是“ORA-09938: fatal two-task communication protocol error”,并伴随着操作系统相关的错误号,例如Linux/Unix系统上常见的“Signal 38”或“Signal 9”,这个错误往往会导致数据库实例突然、意外地崩溃(Crash),对业务系统造成严重影响。
来源分析:Oracle官方文档和资深DBA社区讨论
根据Oracle官方支持文档(MOS Note)以及像Oracle-L邮件列表、ITPUB等技术社区的资深DBA分享,ORA-09938错误的根本原因通常不在于数据库内部的SQL或PL/SQL代码,而是更深层次地指向了操作系统环境,可以把它理解为数据库的某个核心进程(比如PMON、SMON、DBWn等)在尝试执行某项关键任务时,被操作系统“强制终止”了,这个“强制终止”的信号就是问题的核心。
常见的触发原因分析(基于实际案例总结)
根据多个远程支援案例的复盘,导致操作系统发送终止信号的原因主要集中在以下几个方面:
-
操作系统资源耗尽:这是最常见的原因之一,当服务器上的物理内存(RAM)被耗尽,操作系统内核的“内存杀手”(OOM Killer)机制会被激活,为了保全系统本身不宕机,OOM Killer会选择一个它认为“最占用内存”的进程将其杀死,而庞大的Oracle数据库进程往往是首要目标,当Oracle进程被OOM Killer杀死时,就会表现为ORA-09938错误。来源:大量Linux系统下的故障排查记录。
-
内核参数设置不当:Oracle数据库稳定运行严重依赖于正确的操作系统内核参数,如果某些关键参数设置不合理,也可能引发此问题。
- 信号量(Semaphore)限制:Oracle使用信号量来协调多个进程对共享内存(SGA)的访问,如果操作系统允许的信号量数量(SEMMSL, SEMMNI, SEMMNS)设置得过低,当数据库并发连接数较高或进程间通信频繁时,可能会耗尽信号量资源,导致进程无法正常通信而被终止。
- 进程数(Processes)或文件描述符(File Descriptor)限制:如果操作系统对单个用户能打开的进程数和文件数设定了过低的上限,当数据库负载升高,需要创建新的服务器进程或打开更多文件时,就会触碰到这个天花板,进而导致进程创建失败或异常终止。来源:Oracle官方安装文档中关于操作系统配置的部分。
-
存储或I/O子系统故障:虽然不那么直接,但严重的、持续的I/O问题也可能间接导致ORA-09938,如果存储阵列出现故障,导致数据库写入进程(如DBWn)在尝试将数据块写入数据文件时长时间等待或无响应,操作系统可能会认为该进程“僵死”而将其终止。
-
操作系统或硬件层面的不稳定:极少数情况下,操作系统内核本身的Bug、有缺陷的硬件(如内存条故障、CPU缓存错误)或固件问题,也可能导致对正常运行的进程发送错误的终止信号。
紧急修复与远程支援方案(基于实战流程)
当客户报告数据库因ORA-09938崩溃,并请求远程支援时,一个高效的支援流程通常如下:
第一步:立即恢复服务(治标)
- 首要目标:尽快让数据库重新上线,减少业务中断时间。
- 操作:指导客户尝试重启数据库实例,通常使用
sqlplus / as sysdba连接后,执行shutdown abort命令强制关闭(因为实例可能已处于不一致状态),然后再次执行startup命令,在大多数资源耗尽或临时性问题的场景下,简单的重启可以暂时解决问题。 - 警告:必须告知客户,
shutdown abort后紧接着startup,数据库在打开时可能会自动进行实例恢复,需要一定时间,要立即安排后续的问题排查,因为根本原因未解决,问题很可能复发。
第二步:收集关键日志信息(诊断) 在尝试重启的同时或之后,立即远程指导客户从操作系统和数据库层面收集第一手日志证据,这是定位根源的关键。
- 操作系统日志:重点查看
/var/log/messages(Linux)或/var/adm/messages(Unix)文件,在错误发生的时间点附近,寻找与Oracle进程PID(进程ID)相关的记录,特别留意是否有“OOM killer”、“killed process”、“signal 9 (SIGKILL)”或“signal 15 (SIGTERM)”等关键字,这些信息能直接告诉我们是否是操作系统主动杀死了进程。 - 数据库告警日志(Alert Log):这是Oracle自身记录运行信息的地方,告警日志会清晰地记录实例异常终止的时间点和最后的操作,有时也会包含一些错误堆栈信息,有助于辅助判断。
- Trace文件:在
udump或diag/rdbms/<db_name>/<instance_name>/trace目录下,查找在错误时间点生成的跟踪文件,这些文件可能包含更详细的错误信息。
第三步:分析原因并实施根本性修复(治本) 根据收集到的日志信息,进行判断并采取相应措施:
- 如果确认是OOM Killer所致:
- 分析服务器当前的内存使用情况(使用
free -m命令),确认是否真的存在内存不足。 - 检查SGA和PGA的当前设置是否合理,是否存在设置过大导致与物理内存及其他应用争抢的情况。
- 解决方案可能是:1)增加物理内存;2)优化数据库内存参数(SGA_TARGET, PGA_AGGREGATE_TARGET),为操作系统和其他应用留出足够空间;3)优化应用,减少内存消耗。
- 分析服务器当前的内存使用情况(使用
- 如果怀疑是内核参数问题:
- 远程查看当前的内核参数设置(使用
sysctl -a | grep sem和sysctl -a | grep file-max等命令),并与Oracle官方针对特定操作系统和版本推荐的参数进行比对。 - 指导客户修改
/etc/sysctl.conf文件中的相关参数(如kernel.sem,fs.file-max等),然后执行sysctl -p使其生效。重要提示:修改内核参数需要谨慎,最好在业务低峰期进行,并有可能需要重启服务器才能完全生效。
- 远程查看当前的内核参数设置(使用
- 如果指向存储/I/O问题:
- 检查操作系统的I/O监控(如
iostat)是否有持续的高延迟或错误。 - 联系存储管理员,检查存储阵列的健康状态和日志。
- 检查操作系统的I/O监控(如
第四步:后续监控与预防 问题解决后,建议客户建立持续的监控机制,
- 监控服务器的内存、交换分区(Swap)使用率。
- 监控Oracle进程的数量和状态。
- 定期检查数据库告警日志,以便及时发现潜在问题。
处理ORA-09938错误的关键在于快速将“症状”(数据库宕机)与“病因”(操作系统层面的信号终止)联系起来,远程支援的成功,极度依赖于对操作系统日志的准确解读和系统资源的合理配置经验,这是一个典型的DBA需要具备跨领域(数据库+操作系统)知识才能有效解决的问题。

本文由盘雅霜于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84441.html