数据库里重复行怎么快速找出来然后删掉才靠谱呢?

这个问题是每个捣鼓数据的人几乎都会遇到的麻烦事,想象一下,你的客户名单里同一个人出现了两次,或者销售记录里同一笔交易被错误地录入了两回,这些重复数据不仅让统计结果失真,还可能引发一系列业务问题,找到它们并清理掉,是维护数据健康的关键一步,但这事儿不能蛮干,得讲究方法,否则很容易出错,甚至把正确的数据给删了,那可就得不偿失了。
第一步:千万别急着删!先备份!
这是最最重要、绝对不能跳过的一步,无论你对自己的技术多么有信心,都必须先为要操作的数据表做一个完整的备份,用数据库的话术叫“备份”,你可以简单理解为“复制一份一模一样的存起来”,万一后面的操作出了什么岔子,你还能有个“后悔药”,把数据恢复成原来的样子,这是保证操作“靠谱”的基石。(来源:普遍认可的数据库操作最佳实践)
第二步:找准“重复”的标准
什么叫重复?你得先定义清楚,是靠一个字段判断,还是几个字段组合起来判断?对于“用户表”,你可能认为“身份证号”唯一,那么所有身份证号相同的行就是重复行,但有时候,可能需要“姓名+手机号”两个字段都一样才算重复,明确标准是后续所有操作的前提。
第三步:把重复的行找出来

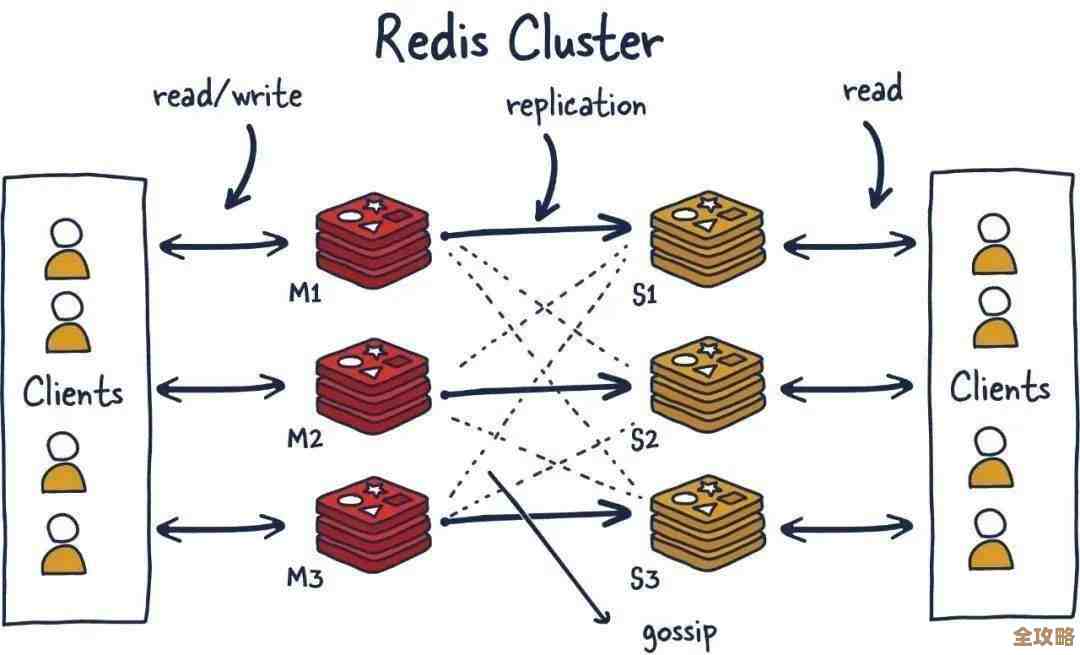
找重复行,一个非常实用且通用的方法是使用 GROUP BY 和 HAVING 子句,这个方法在大多数数据库系统(MySQL, PostgreSQL, SQL Server 等)里都适用,它的核心思路是:先把你认为是判断重复的那些字段分组,然后数一数每个组里有多少行,那些数量大于1的组,就是有重复的。
举个例子,假设我们有一张 customers 表,里面有 id(主键,唯一)、name、email 等字段,我们怀疑邮箱地址有重复,也就是同一个邮箱注册了多个账号。
查找重复邮箱的SQL语句可以这么写:
SELECT email, COUNT(*) as duplicate_count FROM customers GROUP BY email HAVING COUNT(*) > 1;
这条语句的意思是:按照 email 字段进行分组,然后计算每个邮箱地址出现的次数。HAVING COUNT(*) > 1 这个条件会过滤出那些出现次数大于1的邮箱地址,也就是重复的邮箱,执行后,你会得到一个列表,清楚地显示哪些邮箱是重复的,以及重复了多少次。
如果你想看得更详细,想知道具体是哪些行的数据重复了,可以把这个查询和原表连接起来:

SELECT a.*
FROM customers a
JOIN (
SELECT email
FROM customers
GROUP BY email
HAVING COUNT(*) > 1
) b ON a.email = b.email
ORDER BY a.email;
这样,所有重复的行都会按邮箱顺序列出来,你可以仔细检查每一行。
第四步:谨慎地删除重复行
找到重复行之后,怎么删呢?目标是:在每一组重复的数据中,保留一条,删除其他多余的,这里的关键在于,你需要一个标准来决定“保留谁”,通常是保留最新创建的(如果有创建时间字段),或者保留ID最小的那条。
这里介绍一个利用“子查询”或“临时表”的常见方法(以MySQL为例):
-
先确认要保留的那条数据:在每组重复的邮箱中,我们想保留
id最小的那条记录。
-
删除不在“要保留名单”里的重复行:
DELETE FROM customers
WHERE email IN (
SELECT email FROM customers GROUP BY email HAVING COUNT(*) > 1
)
AND id NOT IN (
SELECT MIN(id) FROM customers GROUP BY email HAVING COUNT(*) > 1
);
这个语句稍微复杂点,我们拆开看:
- 最外层的
DELETE表示要执行删除操作。 - 第一个子查询
WHERE email IN (...)用于定位所有有重复邮箱的记录。 - 第二个条件
AND id NOT IN (...)是关键,它排除了每组中那个id最小的记录(也就是我们要保留的记录)。
这样,执行后,所有重复邮箱的记录中,就只有 id 最小的那条被留了下来,其他的都被删除了。
其他情况和注意事项
- 没有唯一ID的情况:如果表里没有一个像
id这样的唯一字段,处理起来会麻烦一些,你可能需要根据其他字段(如时间戳)来排序和决定保留哪条,或者使用数据库特有的功能,MySQL 的ROW_NUMBER()窗口函数,为每一行生成一个序号后再处理。 - 使用窗口函数(更现代的方法):在较新版本的数据库系统中,使用
ROW_NUMBER()函数是更清晰的方式,它可以给数据分区(比如按邮箱分区)并编号,然后你直接删除编号大于1的行即可,这个方法逻辑上更直观,但语法可能稍微复杂一点。 - 在图形化工具里操作:如果你使用的是 Navicat、DBeaver 这类图形化管理工具,它们通常提供了“查找重复项”的向导功能,可以引导你一步步选择字段、查看重复数据,并生成删除语句,这对新手更友好。
总结一下最靠谱的流程:
- 备份数据:这是你的安全绳。
- 定义重复:想清楚按什么条件算重复。
- 先查询后删除:务必先使用
SELECT语句把要删除的数据准确地找出来,仔细核对,确认无误后,再把SELECT换成DELETE执行。 - 决定保留规则:明确每组重复数据中保留哪一条。
- 执行删除:使用严谨的SQL语句,确保只删除目标数据。
- 验证结果:删除后再跑一遍查找重复的查询,确认重复数据已经消失。
处理数据尤其是删除操作,慢就是快,谨慎就是高效,宁可多花时间在确认上,也不要因为一时手快造成无法挽回的数据丢失。
本文由钊智敏于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84385.html