怎么做到服务器数据库共享又快又安全,别光说理论得实操才行

选对共享的“地基”——数据库类型和架构
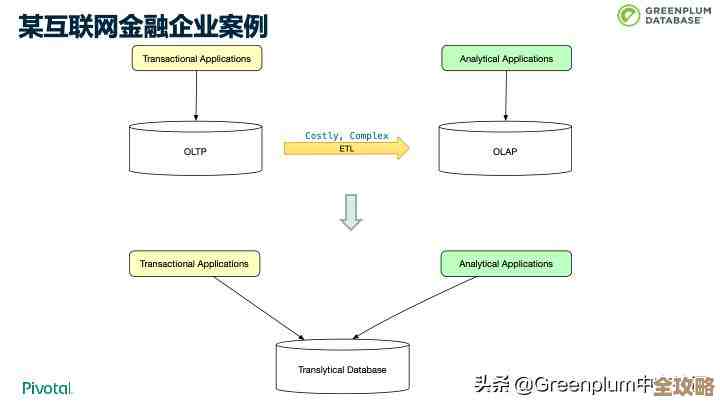
别一上来就谈优化,如果地基没打对,后面全白费,共享数据库,首先得决定是所有人往一个数据库实例里读写,还是把数据分散开。
-
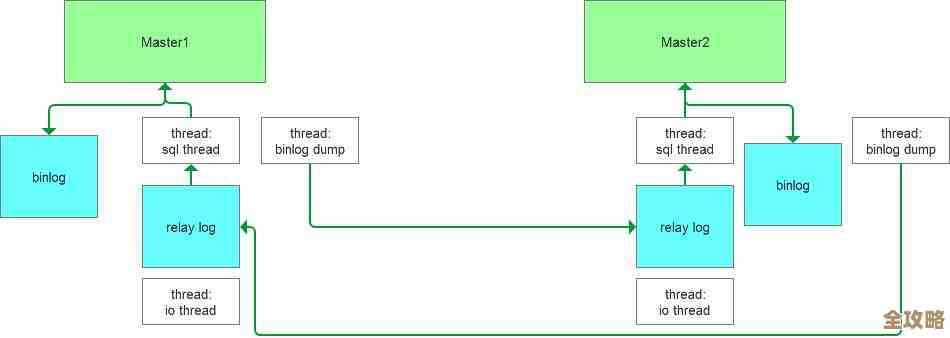
实操选择1:集中式共享(读写分离)
- 干什么: 准备两台或更多台服务器,一台叫“主服务器”,专门负责接收用户的写入操作(比如注册、下单、修改资料),另外几台叫“从服务器”,它们实时地从主服务器那里“复制”数据,但只负责提供读取操作(比如查询商品、看新闻、刷朋友圈)。
- 为什么快: 写操作很耗资源,读操作很频繁,这样分工,写和读的压力被分摊到不同的机器上,避免了所有请求挤在一台服务器上“堵车”,对于绝大多数网站和应用,这个方案提升速度非常明显。
- 具体做法(以常见的MySQL为例):
- 搭建主服务器:在主服务器的配置文件(如
my.cnf)里,设置一个唯一的server-id(比如1),并开启二进制日志(log-bin)。 - 搭建从服务器:在从服务器的配置文件中,设置不同的
server-id(比如2)。 - 授权复制权限:在主数据库里,创建一个专门用于复制的用户账号,并授予
REPLICATION SLAVE权限。 - 获取主服务器状态:在主服务器上执行
SHOW MASTER STATUS,记下当前的日志文件和位置。 - 配置从服务器连接:在从服务器上,执行命令告诉它主服务器是谁,用哪个账号连接,以及从哪个日志文件的哪个位置开始复制,命令类似:
CHANGE MASTER TO MASTER_HOST='主服务器IP', MASTER_USER='复制账号', MASTER_PASSWORD='密码', MASTER_LOG_FILE='刚才记下的文件名', MASTER_LOG_POS=刚才记下的位置; - 启动复制:在从服务器上执行
START SLAVE;,之后可以用SHOW SLAVE STATUS\G查看复制状态,确保没有报错。
- 搭建主服务器:在主服务器的配置文件(如
- 参考来源: 这种模式是数据库领域的标准实践,在MySQL、PostgreSQL等主流数据库的官方文档中均有详细指南,常被称为“主从复制”。
-
实操选择2:分布式共享(分库分表)
- 干什么: 当数据量巨大到一台机器根本存不下,或者某个业务的访问量高到连读写分离都扛不住时,就得“分家”,按用户ID的尾数,把不同用户的数据存到不同的数据库服务器上;或者把一年的订单表,按月拆分成12个小表。
- 为什么快: 化整为零,将巨大的访问压力和存储压力分散到一群服务器上,实现 scale-out(水平扩展),这是大型互联网公司(如淘宝、微信)的必用技术。
- 具体做法:
- 引入中间件: 自己写代码管理分库分表极其复杂,容易出错,强烈建议使用成熟的中间件,ShardingSphere(国产开源,非常强大)或者 MyCat,这些中间件对你应用程序来说,就像一个普通的数据库,你只需要连接它,它会在背后帮你自动处理数据应该去哪台机器查、去哪台机器写。
- 制定分片规则: 这是最关键的一步,你需要和开发人员一起决定按什么规则分数据,常见的有关键字取模(比如用户ID除以10,按余数分)、按时间范围(比如按月分)、按地域分,规则选不好会导致“数据倾斜”(某台机器数据特别多,其他机器很闲)。
- 迁移历史数据: 如果是从现有的大库改造过来,还需要一个工具将老数据按照新规则,平滑地迁移到各个分库中,并保证迁移过程中业务不受影响,ShardingSphere也提供了数据迁移工具。
第二步:打造安全的“护城河”——访问控制和加密
速度上去了,安全绝不能松懈,数据库的大门不能谁想进就进。

-
实操1:最小权限原则
- 干什么: 绝对禁止使用数据库的root或sa这种超级管理员账号给应用程序连接,必须为每个需要连接数据库的应用或服务,创建独立的、权限被严格限制的账号。
- 具体做法:
- 只给读权限的账号: 给那些只做查询功能的从服务器或者缓存服务,创建一个只有
SELECT权限的账号。 - 只给写特定表的账号: 比如一个负责用户注册的服务,只给它对
users表的INSERT权限,不给DELETE和UPDATE权限,更不给它访问订单表的权限。 - 限制登录IP: 在创建数据库账号时,可以指定这个账号只能从某个或某段IP地址的服务器登录,只允许来自内部应用服务器网段的连接,这在MySQL中可以通过
'用户名'@'192.168.1.%'这样的语法实现。
- 只给读权限的账号: 给那些只做查询功能的从服务器或者缓存服务,创建一个只有
-
实操2:通道加密(SSL/TLS)
- 干什么: 防止数据在网络上传输时被窃听,你的用户名、密码以及所有查询结果,如果在网上是“裸奔”的,黑客很容易截获。
- 具体做法(MySQL为例):
- 生成证书: 需要为数据库服务器生成一个SSL证书(可以自签名,生产环境建议用权威机构签发的证书)。
- 服务器端配置: 在MySQL配置文件里,指定证书和密钥的路径,并开启SSL支持。
- 客户端强制SSL: 在创建数据库用户时,要求该用户必须使用SSL连接,命令如:
GRANT ... REQUIRE SSL; - 应用连接串: 在应用程序的连接数据库字符串中,需要增加参数来启用SSL验证,例如JDBC连接串可能会加上
&useSSL=true&verifyServerCertificate=true。
-
实操3:网络隔离

- 干什么: 把数据库服务器藏起来,不让它直接暴露在公网上。
- 具体做法:
- 使用私有网络: 在云平台(如阿里云、腾讯云)上,一定要将数据库实例创建在“私有网络”内,这个网络与外部互联网是逻辑隔离的。
- 配置安全组/防火墙: 这是最关键的安全屏障,数据库服务器的防火墙规则应该极其严格:只开放数据库端口(如MySQL的3306),并且源IP地址只允许来自你前面应用服务器的内网IP地址。 拒绝来自
0.0.0/0(即所有IP)的访问。
第三步:给速度加上“涡轮增压”——缓存和连接池
-
实操1:使用Redis/Memcached做缓存
- 干什么: 把最常用、最热点的数据(比如网站首页内容、热门商品信息)从较慢的数据库里提前取出来,放到极快的内存数据库(如Redis)中,下次用户请求来时,直接从内存返回,速度提升几十倍上百倍。
- 具体做法:
- 部署一个Redis服务器。
- 在应用程序的代码里,在查询数据库之前,先写一段逻辑:去Redis里查一下有没有想要的数据,如果有(缓存命中),直接使用,如果没有(缓存未命中),再去数据库查,并将查到的结果在放一份到Redis里,并设置一个过期时间(比如5分钟)。
- 当数据库中的数据被修改时,要及时清理或更新Redis中对应的缓存,防止用户读到旧数据。
-
实操2:使用数据库连接池
- 干什么: 应用程序每次执行SQL都重新建立一次到数据库的连接,开销巨大,非常慢,连接池就是事先建立好一批连接放在那里“池子”里,应用需要时直接从池子里取一个用,用完了放回去,避免了频繁创建和关闭连接的开销。
- 具体做法: 这主要在应用程序端配置,比如Java项目中使用
HikariCP或Druid(阿里开源,带监控功能)这类优秀的连接池组件,在项目的配置文件中,设置连接池的初始连接数、最大连接数、超时时间等参数即可,这是提升数据库并发处理能力的低成本高收益方案。
总结一下实操流程:
- 架构设计: 根据业务规模,先定是读写分离还是分库分表,中小项目前者足够,大型项目考虑后者并引入ShardingSphere。
- 安全加固: 部署在私有网络,用防火墙严格限制IP,为应用创建最小权限账号,并强制SSL加密连接。
- 性能优化: 引入Redis缓存热点数据,在应用端配置数据库连接池。
这套组合拳打下来,你的数据库共享方案在速度和安全性上就会有一个质的飞跃,所有这些操作都需要在测试环境充分验证后再上线生产环境。
本文由颜泰平于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84382.html