Redis架构指南教你搭建弹性又分布式的系统,实用教程分享

开始)
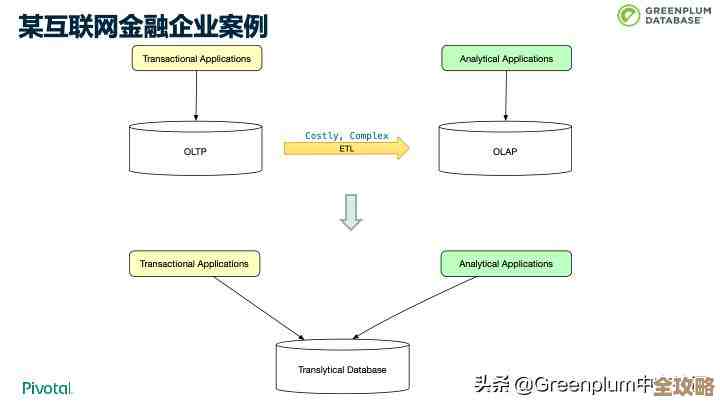
Redis这个东西,大家都知道它快,是个内存数据库,拿来当缓存用特别顺手,但如果你以为Redis只能单机跑跑,做个简单的缓存,那就太小看它了,真正要在生产环境里用得好,让系统既能应对海量数据和高并发,又能在机器出故障时不瘫痪,就得搞懂它的分布式和弹性架构,今天我们就来聊聊怎么一步步搭建一个既结实又伸缩自如的Redis系统,这部分基础概念在Redis官方文档和许多入门教程里都有强调。
第一步:从单机到分片——解决数据量大的问题
最开始,你可能只有一个Redis实例,所有数据都放在一台服务器上,但当数据量越来越大,一台机器的内存装不下了怎么办?这时候就要引入“分片”(Sharding)的概念,简单说,就是把一大份数据切成很多小份,分散到多个Redis实例上去存。
怎么分呢?常见的方法有几种:
- 范围分片: 比如用户ID从1到10000的存到实例A,10001到20000的存到实例B,这种方法简单,但容易导致数据分布不均。
- 哈希分片: 这是更常用的方法,对一个数据的键(Key)计算哈希值(比如用CRC16算法),然后根据哈希值对实例数量取模,决定这个键值对落到哪个实例上,这样做数据分布会比较均匀,很多流行的Redis客户端都直接支持这种分片逻辑。
客户端自己分片会有点麻烦,比如当你想增加或减少Redis实例数量时,需要重新计算几乎所有数据的存放位置,导致大量数据迁移,这叫做“重新分片”,非常折腾,这个痛点在高并发的互联网应用中经常被提及。
第二步:引入代理层——让分片对应用透明
为了让应用端不用关心复杂的分片规则,我们可以加一个“代理”(Proxy)在中间,应用就像连接单个Redis一样,直接连代理;代理则负责接收请求,根据预设的分片规则,把命令转发到正确的Redis实例上,再把结果返回给应用。
这样做的好处是,应用代码基本不用改,分片的复杂性被代理层隐藏了,市面上有一些成熟的代理软件,比如Twemproxy(昵称“nutcracker”),以及更现代的Redis Cluster协议兼容的代理等,使用代理层是构建分布式缓存系统的常见架构模式,在各大公司的技术博客中多有介绍。
第三步:高可用与故障转移——解决单点故障问题
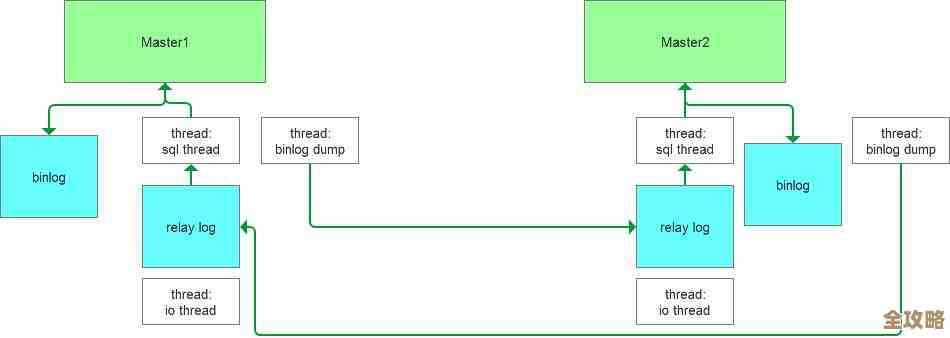
现在数据分片了,但每个分片如果还是单点,一旦某台Redis服务器宕机,它负责的那部分数据就完全无法访问了,系统就会出问题,所以我们必须为每个分片准备“备胎”,这就是主从复制(Replication)。
你可以为每个主分片(Master)配置一个或多个从分片(Slave),主分片负责写操作,它会自动把数据变更同步给从分片,从分片主要用来读,分担主分片的压力。
关键是,当主分片挂掉时,需要有一个机制能自动把一个从分片“提拔”成新的主分片,让服务快速恢复,这个过程叫“故障转移”(Failover),靠自己写脚本监控和切换比较麻烦,Redis提供了一个官方的工具叫Redis Sentinel(哨兵)。
Sentinel本身是多个独立的进程,它们会持续监控所有主从分片的状态,多个哨兵之间会互相通信,如果大部分哨兵都认为某个主分片失联了,它们就会自动协商,选举出一个领头哨兵,然后由它来执行故障转移:挑一个健康的从分片升级为主分片,并通知客户端和其他的从分片这个变化,这样,系统就在几乎不用人工干预的情况下恢复了正常,Sentinel的详细工作机制在Redis官方文档中有最权威的阐述。
第四步:终极方案——Redis Cluster
虽然上面“分片+哨兵”的方案已经很成熟,但部署和管理起来还是有点复杂(需要分别部署哨兵和Redis实例,并配置关联),Redis官方从3.0版本开始,推出了一个更一体化的分布式解决方案:Redis Cluster。
你可以把Redis Cluster理解成一个“自带分片和故障转移能力”的Redis,它没有引入额外的代理组件,而是通过一种叫“Gossip”的协议,让所有Redis节点自己互相通信,来维护集群的元数据(比如哪个键由哪个节点负责),数据被划分为16384个槽位(Slot),每个节点负责一部分槽位。
客户端连接集群时,会先获取一份“槽位配置图”,当客户端要访问一个键时,会自己计算这个键属于哪个槽位,然后直接连接负责该槽位的节点进行操作,如果客户端找错了节点,节点会告诉客户端正确的节点地址(这被称为“重定向”),客户端之后就会连接正确的节点,这种方式减少了代理层的开销,性能更好。
Redis Cluster内置了主从复制和故障转移功能,不需要额外部署Sentinel,当主节点故障时,其从节点会自动接替,这套架构是Redis官方的核心解决方案,在性能和高可用之间取得了很好的平衡,是当前构建大规模Redis系统的首选方案,其设计细节在Redis官网的Cluster规范中有完整说明。
搭建弹性分布式Redis系统,路径很清晰:
- 数据量小、要求不高时,用单机版。
- 数据量大起来,先考虑客户端分片或代理分片。
- 要求高可用,在分片基础上为每个主节点添加从节点+哨兵。
- 追求更简洁、更强大的官方方案,直接采用Redis Cluster。
选择哪种方案,要看你的具体需求:数据量、并发量、运维能力和对一致性的要求,Redis Cluster在某些场景下(如需要跨多个键的事务操作时)有限制,而代理模式可能更灵活,这些实践经验来自于众多开发者在社区论坛(如Stack Overflow, Redis中文社区)的讨论和分享,希望这篇指南能帮你理清思路,搭出适合自己的结实系统。 结束)

本文由帖慧艳于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84376.html