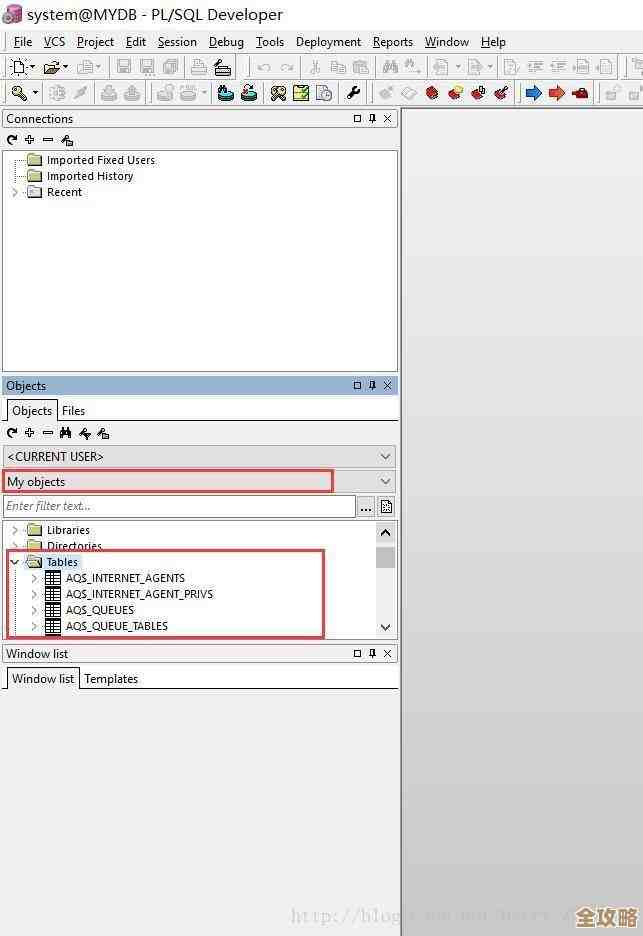
Redis消息队列用着挺方便,但那些限制和坑其实不少,得好好说说才行

Redis用来做消息队列,确实非常方便,几行代码就能让不同的系统部分互相通信,感觉就像一把瑞士军刀,小巧又多功能,很多初创公司或者快速迭代的项目一开始都会用它,因为它简单、快,而且大家通常都对Redis有一定了解,用久了或者业务量上来了,你就会发现,这把瑞士军刀干一些精细活儿的时候,还是有点力不从心,里面有不少限制和坑等着你。
首先一个大问题就是消息丢失,Redis默认是纯内存的,虽然快,但万一服务器突然宕机了,内存里还没处理完的那些消息可就全没了,你可能说可以开启AOF持久化,但这会牺牲一些性能,就算开了持久化,也存在风险,消费者从队列里取走了一个消息,这个动作是瞬间完成的,但如果消费者还没来得及处理这个消息,自己就挂掉了,那这个消息就等于彻底消失了,因为Redis认为已经被消费了,这在一些要求消息绝对不能丢的场景,比如支付通知,是致命的,像专业的消息队列RabbitMQ或Kafka,它们有消息确认(Ack)机制,消费者处理完才告诉队列“可以删了”,没确认的消息会重新放回去,这就可靠多了。
消息重复消费也是个头疼事,这经常和上面的问题连带发生,比如消费者处理一个消息,处理了一半,可能因为网络超时或者自身重启,没有及时给Redis发送确认信号,Redis那边可能以为消费者挂了,过一会儿又把同一条消息分配给了另一个消费者实例,结果同一条支付指令可能就被执行了两次,你得在自己的业务代码里想办法解决这种重复问题,通常要自己做幂等性校验,也就是保证同一个操作执行多次结果都一样,这无疑增加了开发的复杂性。

再来就是队列拥堵和内存爆炸的风险,Redis的内存是有限的,如果消息的生产速度远远大于消费速度,比如消费者服务出了bug卡住了,消息就会在Redis里大量堆积,很快内存就会被撑满,然后Redis可能就开始报错,甚至触发淘汰机制把一些数据删掉,或者直接崩溃,专业的消息队列通常会把消息存在硬盘上,对海量消息的支撑能力要强得多,不会因为积压了点消息就威胁到整个服务的稳定性,你就得时刻盯着Redis的内存使用情况,心里总悬着一块石头。
还有功能上的单一性,Redis的消息队列模型很简单,基本就是“先进先出”的队列或者“发布订阅”模式,但现实中的业务场景要复杂得多,我想要延迟队列,就是让消息过几分钟再被消费,用Redis实现起来就得绕个弯子,用有序集合之类的方式来模拟,很别扭,又比如,我想要消息按照优先级处理,或者想对消息进行复杂的路由(比如满足条件的消息去A队列,其他的去B队列),用Redis原生支持就很难办到,都得自己写代码逻辑去 hack,而这些功能在RabbitMQ这样的专业队列里都是现成的。

“消费者组”这个功能是后来才加的,在早期版本里,如果你想实现一条消息被多个消费者竞争消费(保证只被一个处理),或者想实现一条消息广播给多个消费者组(每个组都收到一份),自己实现起来非常麻烦,虽然新版本的Redis加入了Stream数据类型和消费者组的概念,弥补了这方面的不足,但很多老项目可能还在用旧的LIST结构,或者开发者不熟悉新功能,依然在用老办法,就会觉得很蹩脚。
监控和管理也是个事儿,专业的消息队列一般会提供非常丰富的管理控制台,你能清晰地看到每个队列里有多少消息积压、每个消费者的处理速度、有没有失败的消息等等,而Redis在这方面就比较原始,主要靠一些命令行工具来看,想获得清晰的视图往往需要借助第三方工具或者自己开发监控脚本,运维成本不低。
Redis作为一个轻量级的消息队列解决方案,在开发初期、消息量不大、且可以容忍少量消息丢失的简单场景下,确实非常方便快捷,但一旦你的业务对消息的可靠性、顺序性、吞吐量或者功能多样性有了更高要求,它固有的那些限制和坑就会显现出来,这时候,迁移到RabbitMQ、RocketMQ、Kafka这样的专业消息中间件,几乎是一个必然的选择,说白了,就是用对场景很重要,知道它的好处,更要清楚它的边界在哪里。
本文由歧云亭于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84362.html