Redis 分布式高可用其实挺复杂,哨兵机制是关键但细节还得慢慢琢磨才行

你提到“Redis 分布式高可用其实挺复杂,哨兵机制是关键但细节还得慢慢琢磨才行”,这句话说得非常到位,一下子就点到了核心,我根据自己的理解,来聊聊这事儿为什么说它复杂,以及哨兵这个“关键”角色到底有哪些需要琢磨的细节。

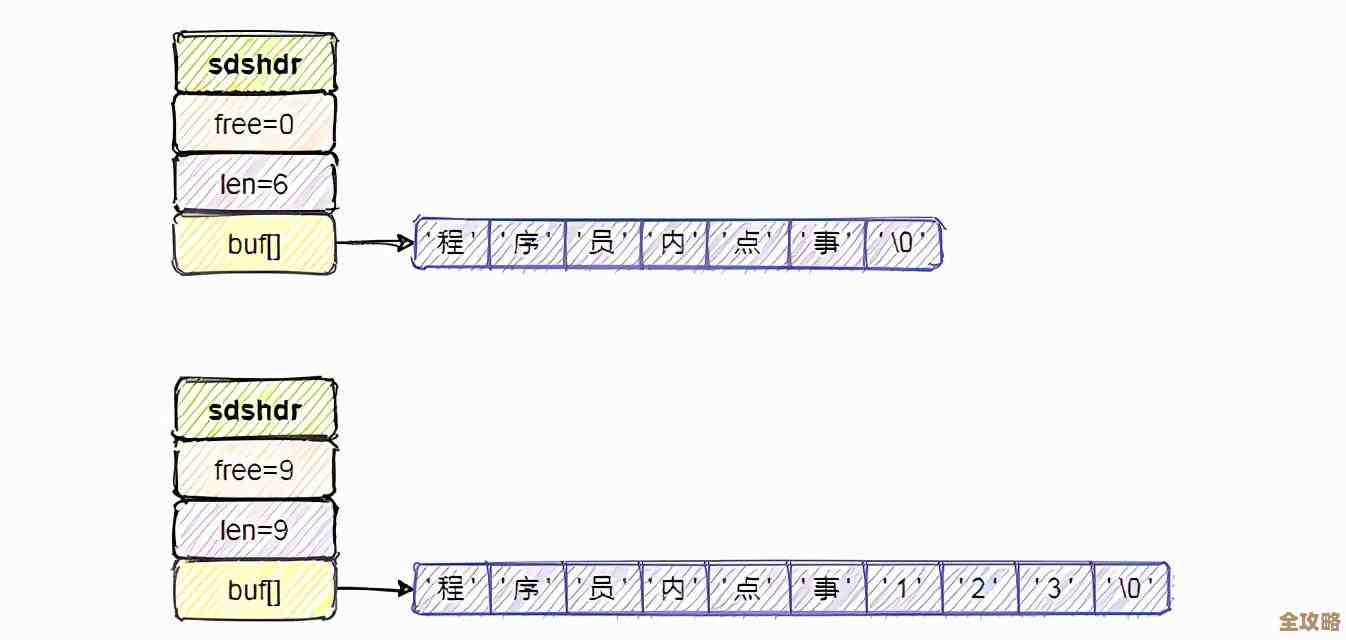
咱们得明白为啥要搞分布式高可用,单机的Redis再快,它也怕出事,机器硬盘坏了、网络抽风了、机房断电了,随便一个情况都能让服务彻底停摆,得有个备胎,也就是主从复制,这算是高可用的基础,就像《Redis设计与实现》这本书里讲的,一个主节点(Master)带着几个从节点(Slave),主节点负责写,然后把数据同步给从节点,从节点主要用来读,也能在主节点挂掉的时候顶上,这个主从复制的机制本身就有不少讲究,比如数据同步是异步的还是半同步的?网络不好时数据会不会丢?但这些还不是最磨人的,最磨人的是那个“顶上去”的过程。
这时候,哨兵(Sentinel)机制就登场了,它的核心任务就像个自动的运维管家,7x24小时盯着主节点还活着没,一旦发现主节点“失联”了,它就得立马行动起来,从一堆从节点里选个最合适的,把它扶正成为新的主节点,然后还得通知其他的从节点和客户端:“喂,换老大了,以后都听它的!”这个过程叫做“故障自动转移”,听起来挺智能对吧?但魔鬼全在细节里。

第一个要琢磨的细节是,哨兵怎么就知道主节点真的挂了? 它可不能因为一次网络抖动就慌慌张张地宣布改朝换代,哨兵自己也是个“分布式系统”,通常要求至少部署三个实例,它们之间会互相通信,形成一个集群,判断主节点下线分两步:一个是“主观下线”,就是某个哨兵自己觉得主节点联系不上了;但真要动手切换,得达成“客观下线”的共识,也就是多个哨兵(比如超过半数)都认为主节点挂了才行,这就避免了单个哨兵误判导致的无谓切换,这个“半数”是多少,怎么配置,就是个需要根据实际网络环境和可靠性要求来权衡的点。
第二个更复杂的细节是领导者选举和新主选举,一旦哨兵们达成客观下线的共识,它们不能一窝蜂都去执行切换操作,那不就乱套了嘛,所以哨兵们得先内部投票选出一个“领头哨兵”(Leader),由这个领头哨兵来负责后续的故障转移,这个选举过程本身就是个分布式共识问题,可能会因为网络分区等原因失败或者延迟,选出领头哨兵后,它还得从剩下的从节点里挑一个新主节点,挑谁呢?不是随便抓一个就行,它得考虑很多因素,比如哪个从节点的数据最新(复制偏移量最大)、哪个从节点和旧主节点断连的时间最短、以及可以手动配置的优先级等等,这个选择策略直接影响到数据的一致性和服务的恢复速度。
第三个让人头疼的细节是切换过程中的数据丢失和客户端感知,即使哨兵流程走得再完美,在旧主节点挂掉的那个瞬间,很可能还有一部分最新数据没来得及同步到从节点,这部分数据就永久丢失了,这是异步复制带来的固有风险,切换不是瞬间完成的,从发现故障到选举新主,再到通知所有客户端更新连接信息,这中间有个时间窗口,在这段时间里,客户端可能既写不了旧主(因为旧主挂了),也找不到新主(因为还没通知到),服务就是不可用的,怎么缩短这个窗口,减少对业务的影响,是需要精心调优的。
哨兵机制本身也不是铁板一块。哨兵集群的高可用也得考虑,如果哨兵节点数量太少,或者部署不合理(比如全放在一台机器上),一旦哨兵集群自己出了问题,整个Redis高可用体系就瞎了,保证哨兵集群的健壮性和网络连通性,是这一切的前提。
所以你看,就像你说的,Redis分布式高可用真的挺复杂,哨兵机制确实是实现自动故障转移的关键,但它背后涉及的分布式系统的经典问题——健康检查、共识达成、领导者选举、状态切换、客户端通知——每一个环节都有深坑等着去填,光是把哨兵配起来跑通可能不难,但真要让它在大流量、复杂网络的生产环境里稳定可靠地工作,里面的这些细节确实得花时间慢慢琢磨透才行。

本文由颜泰平于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/83919.html