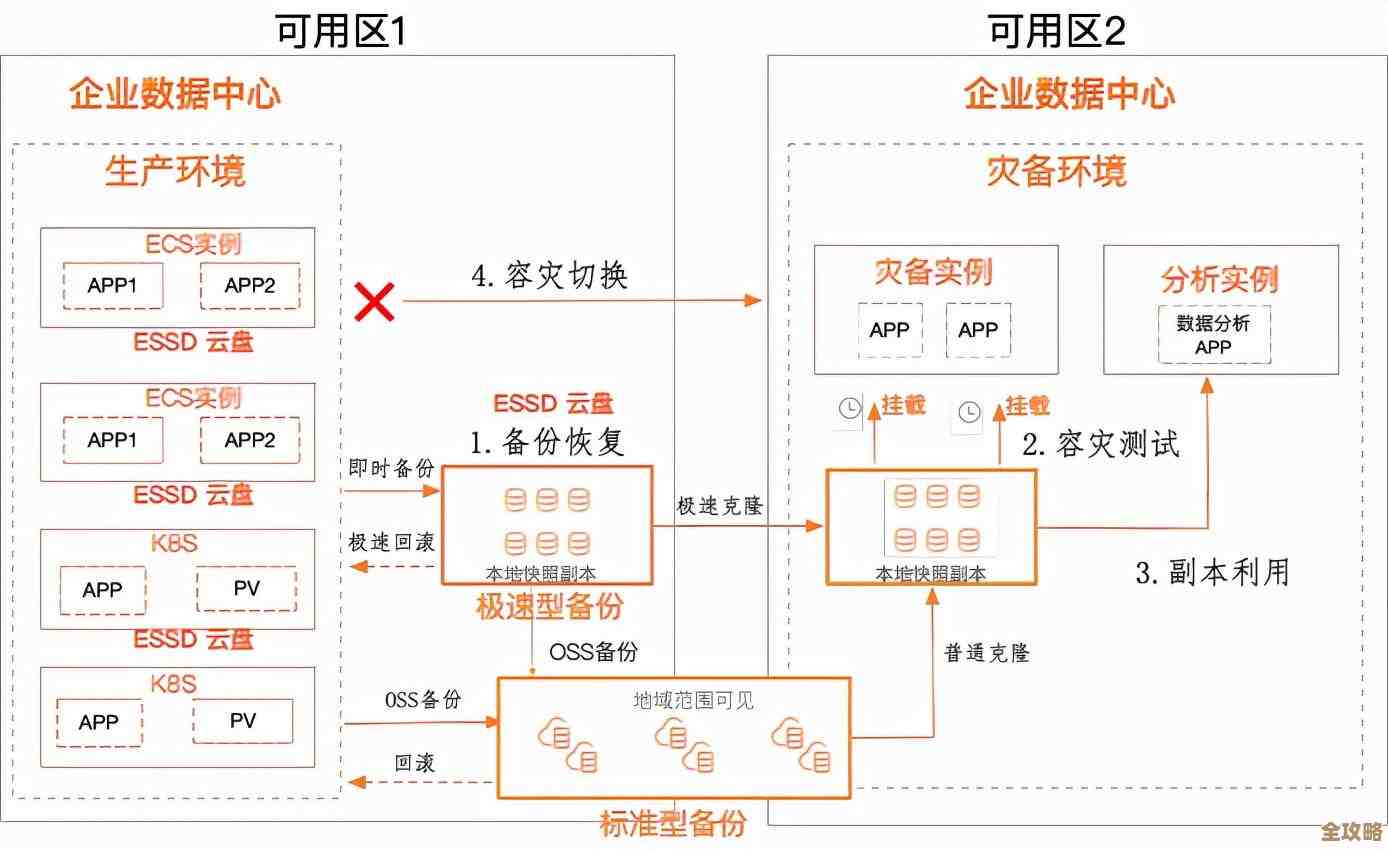
Redis真神奇,万物复活了,但redis能不能改面补这事儿还得琢磨琢磨

(引用来源:网络社区技术讨论与系统架构实践中的常见场景)
Redis这东西,现在搞互联网的几乎没人不知道了,它就像一个超级快的临时仓库,还是那种记忆力特别好的伙计,你想想看,一个网站,每次用户点开页面,都要去数据库里翻箱倒柜找信息,数据库那老胳膊老腿的,哪经得起这么折腾?慢死了,这时候Redis就派上用场了,把那些经常要用的,比如用户的昵称头像啊、热门的文章列表啊、商品的库存数量啊,先一股脑地塞到Redis这个“内存仓库”里,下次再要的时候,直接从内存里拿,唰的一下就出来了,用户感觉网站快如闪电,体验感蹭蹭往上涨,这可不就是“万物复活了”嘛!那些原本需要慢吞吞从数据库深处捞出来的数据,在Redis这里瞬间就“活”了过来,随时待命。
问题就出在这个“上,Redis这个伙计记性是快,但它有个特点,或者说是个限制:它主要就是个“缓存”,缓存是啥意思?就是说,它里面存的东西,很多时候被看作是“临时”的,不是最终的、最权威的版本,那个最终的、最权威的版本,我们称之为“真相之源”,通常还是得放在像MySQL、PostgreSQL这类正经的关系型数据库里。
这就引出了“改面补”这个非常形象的说法,你可以把数据库里的数据想象成一个人的“本来面目”,而Redis里缓存的数据,就像是根据这个“本来面目”快速画出来的一张“肖像画”或者“快照”,这张画一开始画得是挺像的,栩栩如生,假如这个人的“本来面目”变了——比如数据库里用户的手机号更新了——那么问题来了:那张旧的“肖像画”是不是就过时了?不就成了“照骗”了吗?“改面补”,指的就是当数据库里的真实数据(面)发生变化时,我们如何及时、准确地去更新Redis里的缓存数据(补),让它们重新保持一致,别让用户看到错误的信息。
这事儿说起来简单,不就是数据库一变,就让Redis也跟着变嘛?但真做起来,里面的门道可多了,确实得“好好琢磨琢磨”,为啥呢?因为现实中的系统可复杂了,不是简单的你动我就动。
第一种琢磨法叫“实时双写”,就是说,每当应用代码要修改数据库的时候,紧跟着就发一条命令把Redis里对应的缓存也给更新了,这听起来最直接,对吧?但这里头有风险,你想啊,这是两个独立的操作:先写数据库,再更新Redis,万一数据库写成功了,但紧接着更新Redis的时候网络突然抖了一下,或者Redis当时正好压力大没响应,导致更新失败了,那不就坏菜了吗?数据就不一致了,这就好比你去整容医院变了张脸,却忘了通知拍证件照的摄影师,结果你本人和身份证上的照片对不上了,过安检的时候可能就有麻烦。
第二种琢磨法叫“失效重载”,这个思路更简单粗暴:当数据库的数据更新时,我什么都不做,就直接把Redis里那个旧的缓存数据删掉(让它失效),等到下一次有请求需要读这个数据的时候,发现Redis里没有了(我们称之为“缓存未命中”),系统就会乖乖地再去数据库里把最新的数据查出来,然后塞回Redis里,供后续的请求使用,这个方法好处是逻辑简单,避免了同时写两个地方可能失败的问题,但缺点也很明显:在缓存失效后、到新数据被重新加载进Redis之前的这个极短的空窗期里,所有的请求都会直接打到数据库上,如果这个数据特别热门,瞬间可能有成千上万的请求涌向数据库,数据库压力山大,搞不好就被打趴下了,这就是可怕的“缓存击穿”。
还有一种更复杂的情况需要考虑,就是操作的顺序,应该是先更新数据库再删除缓存呢,还是先删除缓存再更新数据库?这俩顺序不同,在极端高并发的场景下,也可能导致短暂的数据不一致,比如你刚删了缓存,还没来得及更新数据库,另一个线程就读了数据库的老数据又塞回缓存了,这样缓存里的还是旧数据,这些细节都得反复推敲。
所以你看,Redis这个神器确实让数据访问速度“复活”了,极大地提升了系统性能,但“改面补”这个确保数据最终一致性的问题,绝对不是个能掉以轻心的小事,它不是一个有标准答案的开关,而是一个需要根据实际业务场景、对数据一致性的要求程度、以及系统能承受的复杂度来权衡和设计的架构问题,是用实时双写追求更强的一致性但承担操作失败风险?还是用失效重载保证最终一致性但要防范缓存击穿?或者采用更复杂的异步监听数据库变更日志(如MySQL的binlog)的方案?这些都需要开发者和架构师们根据具体情况,“琢磨琢磨”再“琢磨琢磨”,才能找到一个最适合自家系统的、平衡了性能与一致性的巧妙方案,说到底,技术工具再神奇,用得好不好,关键还得看使用它的人怎么思考和决策。

本文由寇乐童于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82851.html