高并发和海量数据环境里,系统解耦到底该怎么搞才不崩溃呢?

主要综合了业界常见的解决方案和实践经验,如Martin Fowler的微服务架构论述、Netflix的云原生实践分享、以及《企业集成模式》等著作中的经典模式)

想象一下,一个超级市场在节假日大促销,如果只有一个收银台,所有人挤作一团,那肯定崩溃,系统也是一样,“高并发”就是瞬间涌来成千上万的顾客(请求),“海量数据”就是仓库里堆积如山的商品,解耦的核心思想就是,别让这些顾客都挤在一个地方,而是把他们分流到不同的、专门负责某项任务的区域,这样即使某个区域暂时忙不过来,也不会导致整个市场瘫痪,下面就是几种实实在在的“分流”办法。
第一招,用“消息队列”当“等候区”和“缓冲带”。 这是最常用、最有效的一招,别让请求直接去冲击那个最核心、最耗时的服务,用户点击“下单”,系统立刻把订单信息像写一张小纸条一样,扔进一个叫“消息队列”(比如Kafka、RocketMQ)的盒子里,然后马上就告诉用户“下单成功,正在处理中”,这样一来,前端服务很快就解脱了,可以继续接待下一个用户。 盒子另一边,专门负责扣库存、生成订单的“仓库管理员”服务,可以按照自己的节奏,从盒子里一张一张地取出小纸条来处理,即使瞬间有一万个人下单,也只是有一万张小纸条在盒子里排队,核心服务不会被冲垮,它处理完一个,再拿下一个,整个系统稳稳当当,这就实现了前端下单和后端处理的“解耦”,高峰期的压力被这个“缓冲带”消化掉了。

第二招,把大系统拆成一个个“小专卖店”(微服务)。 别把所有功能都塞进一个巨大的程序里,想象一下,如果把生鲜、家电、服装所有部门都混在一个大厅里,管理肯定混乱,我们应该把它拆开:用户服务专门管登录注册,商品服务专门管商品信息,订单服务专门管交易流程,每个服务都是独立的“小专卖店”。 它们之间通过简单的网络调用(比如HTTP API)或者刚才说的“消息队列”来通信,这样做的巨大好处是,即使“商品服务”因为要处理海量商品图片暂时变慢了,也不会影响到“用户服务”的正常登录,出了问题,也只会是某个“专卖店”需要整顿,而不是整个商场停业,这就叫“故障隔离”,哪个“专卖店”客人多(比如秒杀时的订单服务),我们就可以单独给这个店多派几个店员(增加服务器数量),其他店照常营业,资源利用更合理。
第三招,设立“数据分库分表”,给海量数据安多个家。 海量数据存在一个数据库里,就像把所有商品都堆在一个巨型仓库的同一个货架上,找起来会慢得要命,解耦的思路是对数据进行“拆分”,可以按用户ID的尾数,把用户数据分散到10个不同的数据库里(分库);或者把一个巨大的订单表,按时间切成每个月一个表(分表)。 这就像是开了10个一模一样的仓库,或者把一个大仓库隔成很多小隔间,当需要查询某个用户的信息时,系统自动根据他的ID尾数就知道该去几号仓库找,压力一下子就分散了,这样,读写数据的瓶颈就被打破了,系统处理海量数据的能力自然就增强了。
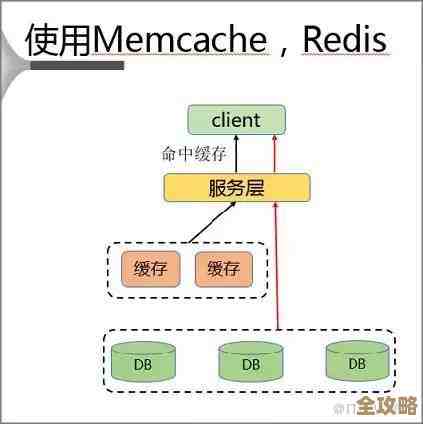
第四招,设置“缓存层”,把热门商品摆在门口。 大部分时候,用户看的都是那些热门的商品信息,没必要每次都去翻仓库(查询核心数据库),我们可以在核心数据库前面,架设一个速度极快的“缓存区”(比如Redis),像超市的门口展柜一样,专门存放最热门的商品数据。 当用户请求来时,先到展柜看看,有就直接拿走,没有再去仓库里取,这样绝大部分请求在“缓存层”就被满足了,根本不会去打扰后方辛苦的数据库,数据库的压力骤减,这也是解耦的一种形式,把高频的读请求和核心的数据存储分开了。
第五招,搞个“配置中心”和“服务发现”,让服务自己能找到彼此。 当系统拆分成很多小服务后,一个问题出现了:订单服务需要调用用户服务来验证用户信息,它怎么知道用户服务今天在哪台机器上呢?因为服务可能会随时增加或迁移。 这时候就需要一个“电话簿”一样的中心设施,叫“服务注册与发现中心”(比如Nacos、Eureka),每个服务启动时都到这个中心“报到”,告诉别人“我是谁,我在哪”,订单服务需要找人时,只要查这个电话簿就行了,这样,服务之间的位置就解耦了,运维人员可以灵活地调整服务器,而不用修改任何业务代码。
在高并发和海量数据的压力下,防止系统崩溃的解耦之道,核心就是“分而治之”,通过消息队列缓冲瞬时压力,通过微服务拆分隔离故障,通过分库分表分散数据压力,通过缓存阻挡大部分读请求,再通过服务发现让这些分散的部分能有机协作,这一套组合拳打下来,系统就从一根容易被压垮的竹竿,变成了一个弹性十足、韧性强大的网状结构,自然就更难崩溃了,关键是让系统的各个部分保持相对独立,避免“一损俱损”的局面。

本文由雪和泽于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82623.html