Redis频繁写入数据时到底是怎么处理的,有啥特别要注意的吗

当你的应用开始频繁地向Redis写入数据时,Redis内部其实在高速运转,它主要依靠几个核心的设计来应对这种压力,理解这些机制,就能明白在哪些地方需要特别注意,避免出现问题。
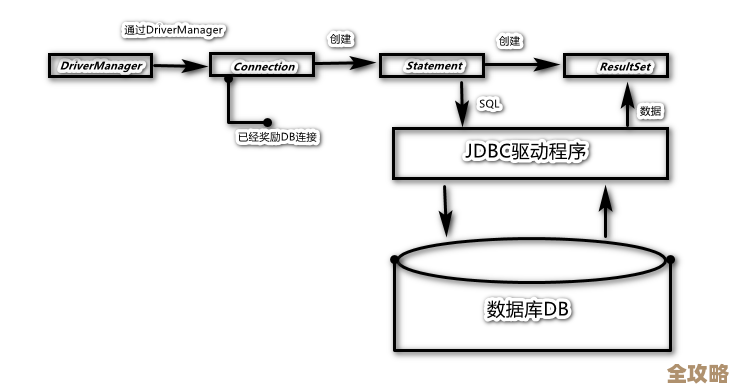
Redis处理写入请求的核心是单线程模型,很多人可能觉得奇怪,一个这么快的数据库怎么会是单线程的?这正是Redis巧妙的地方,它使用一个主线程来处理所有的网络请求(读、写)和键值对的操作,这样做的好处是,完全避免了多线程环境下复杂的锁竞争问题,减少了上下文切换的开销,使得代码更简单,性能可预测,当海量写入请求到来时,这个线程会按顺序一个一个地处理命令,所以每个命令的执行时间都必须是极短的(微秒级),这意味着,你不能在Redis中执行一个非常耗时的命令,否则它会阻塞后续所有的请求,就像高速公路上的一个收费站,如果有一辆车缴费特别慢,后面的所有车都得等着。
为了配合这个高效的单线程,Redis将所有数据都放在内存中,内存的读写速度远远快于磁盘,这是Redis能达到每秒数十万甚至上百万操作的根本原因,内存是有限的,而且比磁盘昂贵得多,当你频繁写入时,第一个必须注意的关键点就是内存容量,你需要清楚地知道你的数据量有多大,增长有多快,并为Redis配置一个合适的内存大小,如果数据写满了,Redis会根据你设定的淘汰策略(maxmemory-policy) 来决定怎么办,比如是报错、淘汰最近最少使用的数据,还是淘汰即将过期的数据等,如果你没设置好,可能导致新数据写不进去,或者重要的数据被意外删除。
虽然数据在内存中,但为了防止服务器断电导致数据全部丢失,Redis提供了持久化机制,将内存数据写入硬盘,这在高频写入场景下尤其需要关注,Redis有两种主要的持久化方式:
- RDB(快照):在特定时间点,将整个数据库生成一个快照文件,这个过程是通过fork一个子进程来完成的,子进程负责写磁盘,主进程继续处理请求,但fork操作本身在数据量很大时可能会耗时,导致主线程短暂停顿,RDB是间隔一段时间进行的,如果服务器在两次快照之间宕机,会丢失这段时间内的所有写入。
- AOF(追加日志):记录每一次写操作命令,写入一个日志文件中,当Redis重启时,会重新执行AOF文件中的所有命令来恢复数据,AOF的持久性更好,可以配置为每秒同步一次磁盘,甚至每次命令都同步(最安全但性能损耗最大),在高频写入下,AOF文件会迅速增长,并且重启恢复数据的时间会非常长。
第二个特别要注意的是持久化带来的性能影响,你需要根据业务对数据安全性的要求,权衡利弊:
- 如果可以容忍分钟级别的数据丢失,可以主要使用RDB。
- 如果要求很高,可以开启AOF,并设置为每秒同步(appendfsync everysec),这是一个兼顾性能和安全性的折中方案。
- 绝对不要在生产环境的高频写入场景下使用
appendfsync always(每次写都同步),这会让Redis的性能急剧下降。
第三个要注意的是网络和客户端,即使Redis本身再快,如果客户端和服务器之间的网络带宽不足或者延迟很高,也会成为瓶颈,频繁写入会产生大量的网络流量,使用管道(pipeline) 技术可以显著提升效率,管道允许客户端一次性发送多个命令给Redis,而不用每个命令都等待响应,减少了网络往返的时间,这在批量写入时效果极其明显。
第四个点是键值对的设计,避免使用大Key(例如一个Hash里有百万个字段,或者一个String值有几百KB),操作一个大Key会直接导致单线程被长时间占用,阻塞其他请求,同样,也要避免大量Key同时过期,因为Redis的过期策略可能会在某个时间点集中删除大量Key,引起延迟波动。
监控是必不可少的,你需要密切关注Redis的监控指标,
- 内存使用率:是否快要达到上限。
- 持久化状态:最后一次RDB/AOF操作是否成功,AOF文件大小是否正常。
- 延迟:客户端请求的响应时间是否在可接受范围内。
- 每秒操作数(QPS):了解当前的负载情况。
Redis就像一个极其高效的单一流水线工人,它能处理惊人的工作量,但前提是你不能给它太重的单件任务(大Key),要保证它的工作台足够大(内存充足),记录工作日志的方式(持久化)不能拖慢他的手速,并且给他输送物料的通道(网络)要顺畅,理解了这些,你就能更好地驾驭Redis,让它在高频写入的场景下稳定、高效地运行。
(主要概念和机制参考自Redis官方文档以及《Redis设计与实现》等常见技术资料中对单线程模型、持久化、内存管理的描述)

本文由芮以莲于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82404.html