cgi怎么快速连接数据库,数据存储和处理效率能不能提升点

关于CGI如何快速连接数据库,核心在于改变每次请求都建立新连接的低效方式,根据网络技术社区和开发者实践经验,最有效的方法是使用连接池,连接池就像一个预先准备好的“数据库连接停车场”,当CGI程序启动时,或者由一个专门的管理器程序负责,先创建一定数量的数据库连接,并将这些连接放在“停车场”里待命,当有用户请求通过Web服务器触发CGI程序时,CGI不是临时去数据库那里敲门建立新连接,而是直接从这个“停车场”里借出一个已经建立好的、现成的连接来用,用完以后,CGI程序不是关闭连接,而是把连接还回“停车场”,留给下一个请求使用,这样就完全避免了每次请求时反复进行网络握手、身份验证等耗时的开销,连接速度自然就快了很多,实现连接池的具体方式取决于编程语言和数据库,例如在Perl中可以使用Apache::DBI模块与mod_perl配合,在Python中可以使用DBUtils或SQLAlchemy等库内置的连接池功能,关键在于,连接池的管理应该由独立的进程或模块负责,而不是由CGI脚本本身来管理其生命周期,这样才能在多个CGI进程间共享连接。

除了连接池,选择更高效的接口替代传统CGI也能从根本上提升速度,使用mod_perl(针对Perl)、WSGI(针对Python,配合Gunicorn/uWSGI等服务器)、FastCGI或PHP-FPM(针对PHP)等,这些技术允许应用程序代码常驻内存,而不是每次请求都启动一个新的操作系统进程,代码常驻内存意味着数据库连接也可以更持久地保持,进一步减少了初始化的开销,FastCGI进程会一直运行,处理一个接一个的请求,它内部维护的数据库连接自然可以复用,其效果类似于应用级别的连接池,但效率更高。

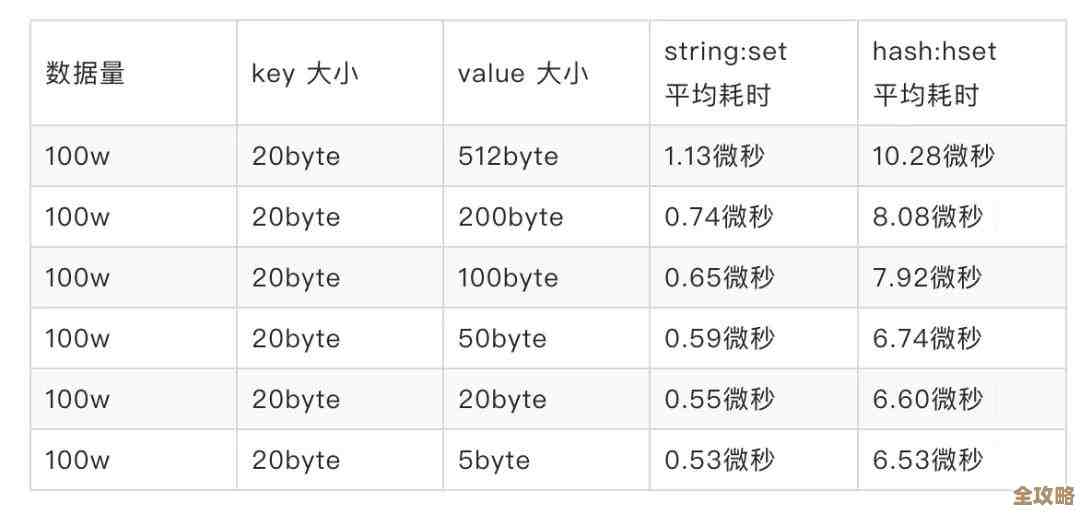
在数据存储和处理效率方面,提升空间很大,这需要从应用程序设计和数据库使用两个层面入手,在应用程序层面,要遵循“按需索取”的原则,很多低效的查询是因为一次性从数据库里抓取了太多不需要的数据,一个页面只需要显示文章标题列表,但CGI程序却执行了SELECT * FROM articles,把文章的完整内容也都取出来了,这无疑增加了网络传输和程序解析的负担,正确的做法是只查询需要的字段,如SELECT title, id FROM articles LIMIT 10,要善用缓存,对于那些不经常变化但访问频繁的数据,比如网站配置、热门文章列表等,可以将其查询结果缓存起来,缓存可以放在内存中,比如使用Memcached或Redis,当下次请求同样的数据时,CGI程序首先检查缓存中有没有,如果有就直接使用缓存的数据,完全绕过数据库查询,速度会得到数量级的提升,这是一种用空间换时间的经典策略。

在数据库层面,确保对经常用于查询条件的字段建立了索引是至关重要的,索引就像一本书的目录,没有索引,数据库要查找数据就得一页一页地全表扫描,速度极慢,而有了索引,数据库就能快速定位到所需的数据行,经常通过用户ID来查询用户信息,就应该在用户表的ID字段上建立索引,但是索引也不是越多越好,因为索引会占用存储空间,并在数据增删改时需要更新,从而带来额外的开销,索引策略需要根据实际的查询模式来精心设计,审视和优化SQL查询语句本身也非常重要,避免在查询中使用复杂的子查询或不必要的连接(JOIN),有时候将复杂的查询拆分成多个简单的查询,在应用程序中组合,反而比数据库单次复杂连接更高效,对于复杂的报表类查询,可以考虑在数据库端建立物化视图(Materialized View),定期刷新数据,从而将运行时的高成本计算转换为对预计算结果的快速查询。
数据库本身的配置优化也不容忽视,根据服务器硬件资源(内存、CPU)调整数据库的缓存区大小、连接数限制等参数,可以让数据库运行得更顺畅,增大数据库的缓冲池,使得更多常用数据可以驻留在内存中,减少缓慢的磁盘读写操作。
CGI连接数据库的快速之道在于摒弃单次连接模式,采用连接池或更先进的常驻进程技术,而数据存储和处理效率的提升,则是一个系统工程,需要结合精心的查询设计、合理的索引策略、高效的缓存应用以及适当的数据库调优,这些措施综合起来,能显著改善CGI应用程序的整体性能。
引用来源思路:以上方法综合自Apache官方文档关于mod_perl和CGI的论述、数据库专家如《高性能MySQL》书中关于查询优化和索引的经典建议、以及Stack Overflow等开发者社区中关于连接池实践和SQL性能调优的常见讨论方案。
本文由酒紫萱于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82362.html