云服务其实开发只是小头,真正重心全在运维上面才靠谱

这个说法其实在行业里流传很广,尤其是一些真正经历过从零到一搭建并长期运营一个云服务项目的工程师和管理者,他们往往会有更深刻的体会,这个观点的核心意思是,把一个云服务“做出来”相对容易,但要让这个服务能够一天24小时、一年365天稳定、可靠、安全地运行,并且能随着用户量的增长而平滑扩展,这个“养”的过程才是真正耗费心力和资源的大头。
(来源:基于多位资深云计算运维工程师和技术负责人的经验分享)
我们可以打个比方,开发一个云服务,就像盖一栋大楼的设计和施工阶段,设计师和建筑工人很关键,他们决定了这栋楼的功能、结构和基本质量,当大楼盖好、剪彩开业的那一刻,就相当于服务的开发完成并上线了,大家往往只看到了开业时的热闹,对于一栋要使用几十年的大楼来说,真正漫长且重要的工作是后续的物业管理:每天的水电供应、电梯维护、消防安全检查、保洁、设备老化更换、应对突发状况(比如水管爆裂、停电)、以及根据住户的新需求进行局部改造升级,如果物业管理跟不上,这栋楼很快就会问题频出,甚至变成危房,最初建设得再漂亮也失去了意义。
(来源:常见的技术团队内部用于向非技术人员解释运维重要性的比喻)

具体到云服务上,为什么运维会如此重要呢?
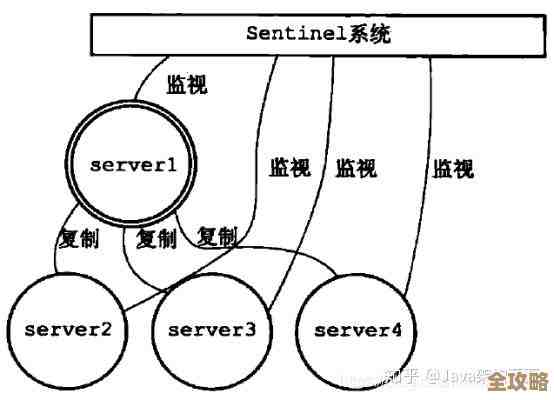
云服务是“活”的,不是一次性的产品,一个传统的软件,比如单机游戏,开发完成、压盘售卖之后,除非有重大bug需要出补丁,否则开发团队的主要工作就转向下一个项目了,但云服务不同,它一旦上线,就开始了它持续的生命周期,用户每时每刻都在使用,会产生海量的数据、日志和访问请求,运维团队需要像守护生命体征一样,7x24小时监控服务的各项指标:CPU使用率、内存占用、网络流量、磁盘空间、响应延迟、错误率等等,任何一项指标的异常波动,都可能意味着潜在的故障,需要立即排查和干预,这种持续不断的监控和保障压力,是开发阶段所没有的。
(来源:对互联网公司SRE站点可靠性工程团队工作模式的普遍描述)

规模带来的复杂性是指数级增长的,开发阶段,可能只是在几台测试服务器上跑通逻辑,模拟少量用户请求,但上线后,面对的是真实、海量且不可预测的用户流量,可能因为一个突然的热点新闻,流量在几分钟内暴涨几十倍,如果运维没有做好自动扩容准备,服务瞬间就会被冲垮,又比如,随着数据量的不断累积,最初的数据库设计可能不再适用,需要进行非常复杂且不能停机的分库分表操作,这种在“飞行中更换引擎”的技术挑战,远比从零开始设计一个数据库要困难得多,这些规模化和增长带来的问题,只有在长期的运维实践中才会暴露出来。
(来源:总结自多个大型互联网系统在应对流量洪峰和数据库扩容时的案例复盘)
安全威胁和故障是常态,而非例外,在互联网上,扫描、攻击、入侵的尝试无时无刻不在发生,运维团队需要构建多层次的安全防线,定期打补丁、分析漏洞、抵御DDoS攻击、防止数据泄露,硬件会老化、网络会抖动、机房可能遇到断电,这些底层基础设施的故障是必然会发生的事件,高水平的运维不是追求永远不出错,而是构建一个即使某个部分出错,整个服务依然能保持可用性的“弹性”架构,这需要精细的灾难恢复预案和频繁的演练,这些工作都是持续性的、深入的运维活动。

(来源:基于网络安全专家和基础设施运维团队对“混沌工程”和“容灾设计”的强调)
用户体验的优化依赖于运维数据,一个服务上线后,好不好用、哪里卡顿、用户经常在哪个环节流失,这些问题的答案都藏在运维收集的海量日志和性能数据中,通过持续监控和分析这些数据,运维和开发团队才能有针对性地进行优化迭代,这个过程是循环往复、没有终点的,可以说,运维是连接服务与真实世界的桥梁,它提供的反馈是驱动产品改进的最宝贵输入。
(来源:产品经理和数据分析师与运维团队合作进行用户体验优化的常见工作流程)
“开发只是小头,运维是重心”这个说法,并不是贬低开发工作的价值——没有高质量的开发,运维就是无米之炊,它更多的是强调一种重心和资源投入的转变,对于一项成功的、长期的云服务而言,其核心竞争力并不仅仅在于它最初有多么新颖的功能,更在于它是否具备极强的稳定性、可扩展性和安全性,而这些品质,正是在日复一日、细致入微的运维工作中被锤炼和保障出来的,意识到这一点,团队才会在项目早期就重视可运维性设计,并为后续漫长的运维阶段配备足够精力和资源,这才是让服务能够长久“靠谱”的关键。
(来源:综合自多位技术高管在规划技术团队结构和资源分配时的战略考量)
本文由帖慧艳于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82172.html