Redis同步读取数据怎么才能更快,性能提升其实有窍门和突破点

要让Redis同步读取数据变得更快,关键在于理解Redis的工作模式并避开那些不起眼但影响巨大的“坑”,这不仅仅是调整几个参数那么简单,而是需要从架构设计、使用方式和系统配置等多个层面进行综合优化。
第一,首要大事:确保网络链路最优。
Redis的性能瓶颈绝大多数时候不在CPU,而在网络,一次简单的读取操作可能在Redis内部只需几微秒,但网络延迟却可能高达几毫秒,相差千倍,优化网络是性价比最高的选择。

- 缩短物理距离:这是最根本的方法,应用程序和Redis实例应该部署在同一个机房、同一个可用区内,最好是同一个机架甚至同一台物理机上(通过不同端口部署),物理距离的缩短能直接降低网络延迟,如果业务是跨地域的,可以考虑搭建异地多活架构,让用户就近读取本地数据中心的Redis,但这属于更复杂的架构设计。
- 使用长连接和连接池:绝对避免每次操作都建立新的TCP连接,建立连接的三次握手过程非常耗时,必须使用连接池来维护一组活跃的长连接,需要时直接从池中取用,用完后归还,几乎所有语言的Redis客户端都支持连接池,务必正确配置连接池的大小,避免连接数过多或过少导致的问题。
- 警惕网络带宽打满:虽然Redis通常处理的是小数据,但如果存在大Key(例如一个Hash里存了几十万个字段)或者并发量极高,累积的网络流量可能会占满网卡带宽,这时,延迟会急剧上升,监控服务器的网络流量至关重要。
第二,核心技巧:优化数据结构和命令。
你用什么样的方式把数据存进去,决定了你用什么样的方式读出来,错误的数据结构和命令是性能的隐形杀手。

- 坚决避免大Key:这是Redis性能的“头号公敌”,一个Value的大小达到MB级别甚至更大,就是大Key,读取它时,不仅耗时长、阻塞其他请求(Redis是单线程),还可能拖垮网络,解决方案是拆分,比如一个巨大的用户信息Hash,可以按字段前缀拆分成多个小的Hash;一个巨大的List可以拆分成多个List。
- 选择高效的数据类型:使用合适的数据结构能减少数据量,读取自然更快,存储真假值用
SETBIT,存储小型非负整数用INCR,而不是用String,Redis官方文档详细介绍了每种数据结构的适用场景。 - 多用批量操作(Pipeline):如果需要连续读取多个Key,不要用for循环一个个发
GET命令,这样会产生“次次往返”(Round-Trip Time, RTT)延迟,应该使用Pipeline(管道)技术,将多个命令一次性打包发送给Redis,Redis依次执行后再一次性返回结果,这能将N次网络延迟降低为1次,提升效果立竿见影,但要注意,Pipeline中的命令数量也不宜过多,避免单次传输数据量太大。 - 慎用模糊查询:
KEYS命令会遍历所有键,在生产环境是禁用的,它的替代方案是SCAN命令,SCAN是游标式的迭代查询,不会阻塞服务,但读取速度本身并不快,因为它需要扫描,所有模糊查询都应被视为不得已而为之的操作,最好的设计是通过精确的Key来读取。
第三,架构层面的突破点:利用复制和分片。
当单个Redis实例的性能达到上限时,就要从架构上想办法。
- 读写分离:这是提升读性能最经典的架构,通过Redis的主从复制(Replication)功能,配置一个主节点(Master)负责写,多个从节点(Slave)负责读,应用程序将读请求分发到多个从节点上,极大地扩展了读吞吐量,需要注意的是,从节点的数据同步有毫秒级的延迟,对于强一致性要求的场景需要评估。
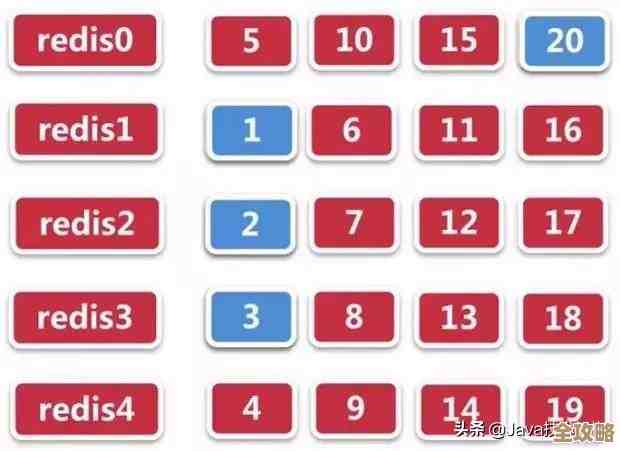
- 数据分片(Sharding):当数据量巨大,单个实例内存不足时,就必须进行分片,将数据分布到多个Redis实例上,每个实例只负责一部分数据,这样,读请求也被分摊到不同机器上,客户端分片(如Twemproxy)或服务端分片(Redis Cluster)都可以实现这一目标,分片解决了容量和性能的双重问题,但增加了架构的复杂性。
第四,容易被忽略的细节:系统与配置。
- 绑定CPU(CPU亲和性):在多核服务器上,可以将Redis进程绑定到特定的CPU核心上,这能利用CPU缓存,减少进程在不同核心间切换带来的性能损耗,通过
taskset命令可以轻松实现。 - 优化内存管理:确保操作系统有足够的空闲内存,避免Redis的内存被交换(Swap)到硬盘上,一旦发生交换,性能会断崖式下跌,根据数据特点选择合理的
maxmemory-policy(内存淘汰策略)。 - 使用更快的硬件:虽然听起来简单,但有时升级硬件是最直接的方法,使用性能更好的CPU、更快的网卡(如万兆网卡),甚至将Redis数据放在内存中(禁用持久化),都能带来直接的性能提升。
总结一下,提升Redis同步读取性能是一个系统工程,它要求我们从“网络传输”、“数据命令”和“系统架构”这三个维度去审视和优化,没有一劳永逸的银弹,但通过排查网络延迟、消灭大Key、善用Pipeline、实施读写分离等具体措施,我们完全可以让Redis的读取速度达到一个新的高度,预防远胜于治疗,在设计和开发阶段就养成良好的使用习惯,是保证高性能的根本。
本文由革姣丽于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82119.html