Redis写入性能怎么测?有哪些策略能让写入更快更稳的测试方法

要测试Redis的写入性能并找到让写入更快更稳的方法,我们可以从两个主要方面入手:一是如何进行有效的性能测试,二是在测试过程中或实际应用中可以采用哪些策略来提升表现。
第一部分:Redis写入性能怎么测?
测试Redis的写入性能,核心目标是模拟真实场景的压力,找出系统的瓶颈和极限,不能简单地只关心一个最大数字,而要关注其在持续、并发压力下的行为,主要方法和工具有以下几种:
-
使用redis-benchmark工具进行基础测试 这是Redis官方自带的最简单、最直接的性能测试工具,它不需要编写任何代码,通过命令行即可执行,一个最基础的写入测试命令可能是:
redis-benchmark -t set -n 100000,这表示测试10万次的SET命令操作。 为了获得更全面的视图,可以调整多个参数:- -c (客户端并发数):模拟多个客户端同时连接,
-c 50表示50个并发连接,这是测试并发处理能力的关键,单线程测试没有意义。 - -d (数据大小):设置写入的value值的大小,
-d 100表示每个value是100字节,不同数据大小对网络和内存的影响巨大。 - -p (管道操作):使用管道技术(pipeline),
-p 16表示将16个命令打包一次性发送,极大减少网络往返开销,能测出Redis服务端处理的极限吞吐量。 - -k:是否使用长连接(keep-alive)。 通过组合这些参数,可以大致了解在不同压力和数据模型下Redis的写入性能(通常以QPS,即每秒查询次数来衡量),但redis-benchmark过于简单,无法模拟复杂的业务逻辑。
- -c (客户端并发数):模拟多个客户端同时连接,
-
使用memtier_benchmark进行高级测试 这是Redis Labs推荐的一款更强大的基准测试工具,被认为是进行专业基准测试的行业标准之一,它提供了比redis-benchmark更精细的控制和更丰富的输出报告,memtier_benchmark可以设置读写比例、使用更复杂的随机键名模式、生成更详细的延迟分布报告(如百分比延迟P99),这对于评估“稳定性”和“尾部延迟”至关重要,一个稳定的系统,不仅平均延迟要低,99%的请求延迟也应该在一个可接受的范围内。
-
编写自定义脚本模拟真实场景 这是最接近实际业务情况的测试方法,使用如Python(配合redis-py库)、Java(配合Jedis或Lettuce)等语言,编写脚本模拟你业务中的真实数据模型和访问模式。

- 数据模型:写入的是不是简单的键值对?还是Hash、List等复杂结构?value的大小分布是怎样的?
- 写入模式:是持续均匀写入,还是有突发的高峰?键名的生成是否有热点(某些键被频繁更新)? 这种测试虽然开发成本较高,但结果最具参考价值,能发现特定业务场景下的独特问题。
在进行任何测试时,必须明确测试目标环境,包括Redis是运行在单机、虚拟机、容器还是云服务上?硬件配置(CPU、内存、磁盘类型SSD/HDD)如何?网络带宽和延迟怎样?测试客户端最好与Redis服务器分离,避免客户端成为瓶颈。
第二部分:有哪些策略能让写入更快更稳?
测试本身是为了发现问题和验证优化效果,以下策略可以帮助提升写入性能和稳定性:

-
使用管道(Pipeline)技术 这是提升写入吞吐量最有效的方法之一,如之前所述,管道将多个命令打包成一个请求发送,服务器处理后再一次性返回结果,这极大地减少了网络往返次数(RTT),在批量化数据导入或允许少量延迟的场景下,开启管道可以将性能提升数倍甚至数十倍,根据Redis官方文档《Using pipelining to speedup Redis queries》中的说明,管道能显著提升协议效率。
-
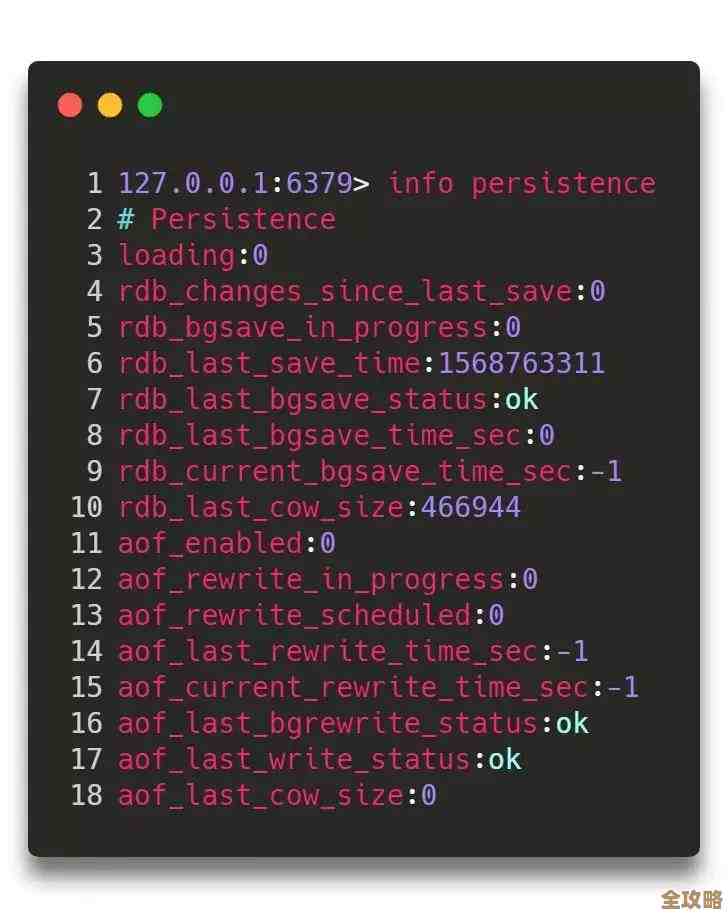
谨慎选择持久化策略,并做好配置 Redis的持久化(数据落盘)是影响写入性能和外网稳定性的最关键因素,主要有两种方式:
- RDB(快照):在指定时间间隔生成数据集的二进制快照,写入性能较好,因为fork子进程进行持久化,主进程继续服务,但可能会丢失最后一次快照后的数据。
- AOF(追加日志):记录每一个写操作命令,重启时重新执行以恢复数据,数据安全性高,但写入频率设置不当会严重影响性能。
优化策略:对于追求极致写入速度且允许分钟级数据丢失的场景,可以仅使用RDB,或完全禁用持久化(纯内存缓存),对于需要高数据安全性的场景,使用AOF,但建议将
appendfsync配置设置为everysec(每秒同步一次,是性能和安全性的较好折衷),避免使用always(每个写命令都同步,会严重拖慢速度),确保运行Redis的服务器使用SSD硬盘,可以大幅提升AOF日志写入和重写时的磁盘I/O性能。
-
优化操作系统和Redis配置
- Overcommit Memory:在Linux系统中,设置
vm.overcommit_memory=1,可以避免在Redis做持久化(如BGSAVE)fork子进程时因申请大量内存而失败的问题,增加稳定性,这在Redis官方文档《Redis Administration》的“Memory Management”部分有明确建议。 - Transparent Huge Pages (THP):建议禁用THP,因为它可能导致Redis延迟飙升,同样在Redis官方文档中有提及。
- maxmemory策略:务必设置
maxmemory并配置合理的淘汰策略(如allkeys-lru或volatile-lru),防止内存耗尽导致写入失败或服务器崩溃。
- Overcommit Memory:在Linux系统中,设置
-
采用分布式架构 当单实例Redis无法满足写入需求时,唯一的出路是走向分布式。
- Redis Cluster(集群):将数据自动分片到多个主节点上,写入压力可以分散到不同节点,从而实现水平扩展,提升整体写入吞吐量,这是应对超大规模写入的终极方案。
- 主从复制:通过主从复制,可以将写操作集中在主节点,读操作分散到从节点,虽然不直接提升写入性能,但通过分担读压力,间接保证了主节点能更“专心地”处理写入请求,提升了整个系统的稳定性和读扩展性。
总结一下,测试Redis写入性能需要一个从简单到复杂、从通用到定制的系统化方法,而提升性能则是一个系统工程,需要从网络(管道)、持久化配置、操作系统调优和架构设计(集群)等多个层面综合考虑,通过持续的测试、监控和调整,才能让Redis的写入既快又稳。
本文由凤伟才于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/81607.html