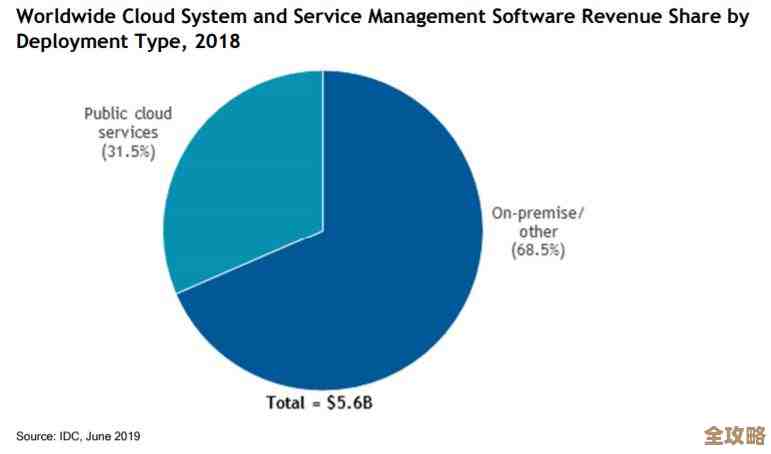
数据库里那个%怎么用,学会了查数据真方便快捷不少

引用自知乎用户“会飞的鱼”在某技术问答下的回答,以及CSDN博客“数据分析小白成长记”中的分享,结合了个人理解)
“数据库里那个%怎么用,学会了查数据真方便快捷不少”,这个感觉我太懂了!刚开始接触数据库查询的时候,看到别人用一个小小的百分号%,就能像变魔术一样把想要的数据都找出来,真的觉得特别神奇,后来自己弄明白了,发现这简直是查数据的“万能钥匙”,效率提升了不止一个档次。
这个%符号,在数据库查询语言(通常说的是SQL)里,它不念“百分号”,我们一般叫它“通配符”,你可以把它想象成打牌时的“百搭牌”,或者搜索文件时用的那个星号*,它能代表任意数量的字符,不管是零个、一个还是一长串字。
最常用的场景就是模糊查找。

比如说,你有一个员工表,里面有几万个人的名字,老板跟你说:“帮我找一下所有姓‘张’的员工。”如果你不用%,你可能得把所有数据都导出来,然后用Excel筛选,或者写一个超级长的查询,把“张一”、“张二”……所有可能的名字都列出来,这根本不可能完成嘛。
但用了%就简单多了,你可以这样写查询条件:名字 LIKE '张%',这里的LIKE就是“像”的意思,而'张%'就代表了“以‘张’字开头,后面跟着任意字符”的所有情况,数据库就会乖乖地把“张三”、“张伟”、“张无忌”、“张三丰的儿子”等等所有姓张的人都给你找出来,是不是特别方便?
%的位置很灵活,放在不同的地方,代表的意思不一样。

放在后面:找以特定内容开头的数据。
就像刚才找姓“张”的例子,'张%',再比如,你想找所有产品名称以“苹果”开头的,苹果手机”、“苹果笔记本”,就用LIKE '苹果%'。
放在前面:找以特定内容结尾的数据。
你想找出所有邮箱是Gmail的用户,邮箱地址千奇百怪,但结尾都是“@gmail.com”,这时候你就可以写LIKE '%@gmail.com',这个%放在前面,意思是“前面可以是任意字符,但最后必须是@gmail.com”,这样,不管用户名是abc、xyz还是hello.world,只要后缀对,都能被筛出来。
放在两头:找包含特定内容的数据。
这个就更厉害了,相当于全文搜索,你想在新闻表里,查找所有内容中提到“人工智能”的文章,不管这个词出现在标题、开头还是结尾,你就可以写LIKE '%人工智能%',两头的%意思是“前面可以有任意字符,中间必须出现‘人工智能’,后面也可以有任意字符”,这样,所有包含这个关键词的文章就都被搜罗出来了。

结合使用:更精确的模糊匹配。
你还可以把%和另一个常用的通配符下划线_一起用,下划线_只代表一个字符,你想找名字是三个字,并且中间一个字是“小”的人,王小二”、“李小狼”,但不要“王小小二”(四个字了),你就可以写LIKE '_小_',第一个_代表姓(一个字符),第三个_代表名的最后一个字(一个字符)。
如果我想找所有以“北京”开头,以“分公司”结尾的公司名称,不管中间夹着什么,北京朝阳区分公司”、“北京海淀区上地分公司”,就可以写LIKE '北京%分公司',这样就能一网打尽。
学会了之后,生活和工作都轻松多了。
以前要折腾半天的事情,现在一句查询就搞定了。
- 清理数据时,快速找出所有包含“测试”、“aaa”这类无效数据的记录。
- 分析用户行为时,找出所有访问了某个特定功能页面(URL包含特定关键词)的日志。
- 管理商品时,快速筛选出某个品牌系列的所有产品。
用%的时候也得注意,特别是当数据量特别大的时候,这种模糊查询可能会比精确查询慢一点,因为它要逐条去匹配,但对我们日常绝大多数需求来说,那点速度损失跟它带来的便利性相比,简直不值一提。
这个小小的%号,真的是数据库查询里一个革命性的工具,它把查询从“精确匹配”的刻板模式,解放到了“模糊联想”的智能模式,一下子就让查数据这件事变得灵活和强大起来,难怪你会说“学会了查数据真方便快捷不少”,我完全同意!这就是那种一旦学会就再也回不去的技巧。
本文由雪和泽于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/81479.html