Redis消息队列延迟真是个头疼的问题,怎么应对才好呢?

“Redis消息队列延迟真是个头疼的问题,怎么应对才好呢?”这个问题,确实是很多使用Redis做消息队列的开发者会遇到的一个坎儿,Redis因为它超高的性能和简洁的数据结构,经常被拿来当轻量级的消息队列使用,比如用List做FIFO队列,或者用Pub/Sub做发布订阅,但用着用着就会发现,当消息量大了,或者有什么突发情况时,延迟就蹭蹭往上涨,消息堵在那里发不出去,或者消费者处理不过来,真的很让人焦虑。
要应对这个问题,我们得先搞清楚延迟可能出在哪个环节,是消息生产得太快了?还是Redis本身处理不过来了?或者是消费者消费得太慢了?就像堵车一样,你得先找到是哪个路口出了问题。
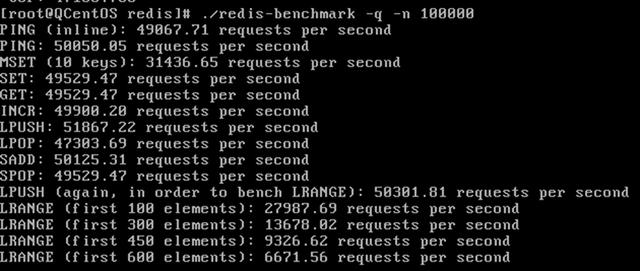
最容易想到的一点是,检查Redis实例本身的健康状况。 这是基础中的基础,如果Redis自己都快跑不动了,那消息队列肯定快不起来,你可以看看Redis的监控指标,比如CPU使用率是不是长期很高,内存使用情况怎么样,会不会因为内存不足触发了Swap(交换),一旦用了Swap,速度就会急剧下降,还有,如果网络带宽打满了,数据传不进去也取不出来,自然就延迟了,升级硬件配置、优化Redis的配置参数(比如合理设置最大内存和淘汰策略)、保证网络畅通,这些都是治本的方法,如果用的是云服务,可以考虑升级到更高规格的实例。
看看是不是生产者的“火力”太猛了。 有时候业务高峰期,生产者瞬间产生海量消息,像洪水一样涌向Redis,Redis虽然是内存操作,但处理命令也是有上限的,如果生产者的发送速率持续超过Redis的处理能力,消息就会在Redis内部排队,导致延迟升高,对于这种情况,可以考虑在生产者端做一些限流控制,避免无节制地发送,或者,引入一个缓冲层,比如先用本地队列暂存一下,再以平稳的速率发送到Redis,起到一个“削峰填谷”的作用。
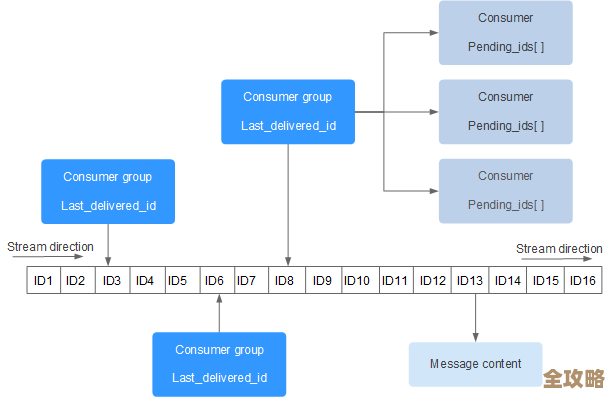
最关键的可能还是消费者的消费能力。 很多时候延迟的罪魁祸首不是Redis,而是消费者,如果消费者处理一条消息需要执行复杂的业务逻辑,比如操作数据库、调用外部接口,耗时很长,那它消费的速度就远远跟不上生产的速度,消息就会在队列里堆积起来,延迟越来越高,应对方法有几个思路:一是增加消费者的数量,一个消费者忙不过来,那就多开几个实例,大家一起消费,这就是水平扩展,使用Redis的LIST结构时,多个消费者可以通过RPOP或BRPOP命令来争抢任务;如果使用更高级的Stream结构,可以利用消费者组(Consumer Group)的功能,让消息能均衡地分发给组内的多个消费者并行处理,这是更现代、更推荐的做法,二是优化消费者本身的处理逻辑,看看能不能优化代码、优化数据库查询、或者把一些非核心操作异步化,缩短处理单条消息的时间。
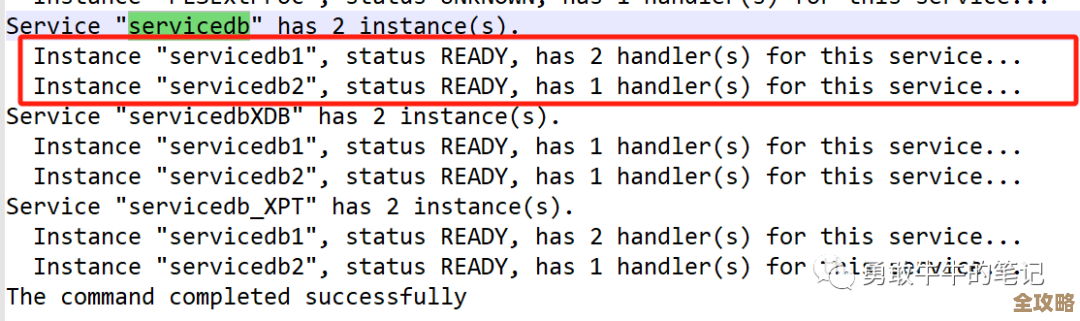
消息队列的数据结构选择也很重要。 很多人一开始图简单就用List的LPUSH/BRPOP来做队列,这在简单场景下没问题,但Redis 5.0引入的Stream数据结构,是专门为消息流场景设计的,功能强大很多,它支持消息的持久化,支持消费者组,可以精确地追踪每个消费者的处理进度(ACK机制),避免消息丢失,特别是在多消费者和需要可靠消息处理的场景下,使用Stream能更有效地管理消息流,减少因为数据结构本身限制带来的潜在延迟问题。
别忘了处理“慢查询”。 如果Redis正在执行一些非常耗时的命令,比如KEYS *这种会阻塞其他命令的操作,那么整个消息队列的读写都会被卡住,务必避免在生产环境使用阻塞性的命令,对于需要扫描键的操作,可以使用SCAN命令来非阻塞地迭代。
如果单台Redis实例的性能真的到了瓶颈,就要考虑架构上的扩展了。 可以对消息队列进行分片(Sharding),根据业务逻辑,将不同的消息类型发送到不同的Redis实例的不同队列中,把压力分散开,这样,一个队列的拥堵不会影响到其他队列,这增加了系统的复杂性,需要根据实际情况权衡。
应对Redis消息队列延迟,不是一个单点问题,需要一个系统的视角:从资源层(Redis本身)确保性能充足,从生产端控制流量洪峰,从消费端提升处理能力和扩展性,并选择更合适的数据结构(如Stream),持续的监控和告警是必不可少的,只有实时掌握队列长度、消费延迟等关键指标,才能在问题刚冒头的时候就及时发现并处理。
(参考资料:主要思想来源于常见的Redis消息队列最佳实践,以及如《Redis实战》等技术书籍中关于构建消息队列的章节,同时结合了Redis官方文档中关于Stream数据结构的说明。)

本文由歧云亭于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/81312.html