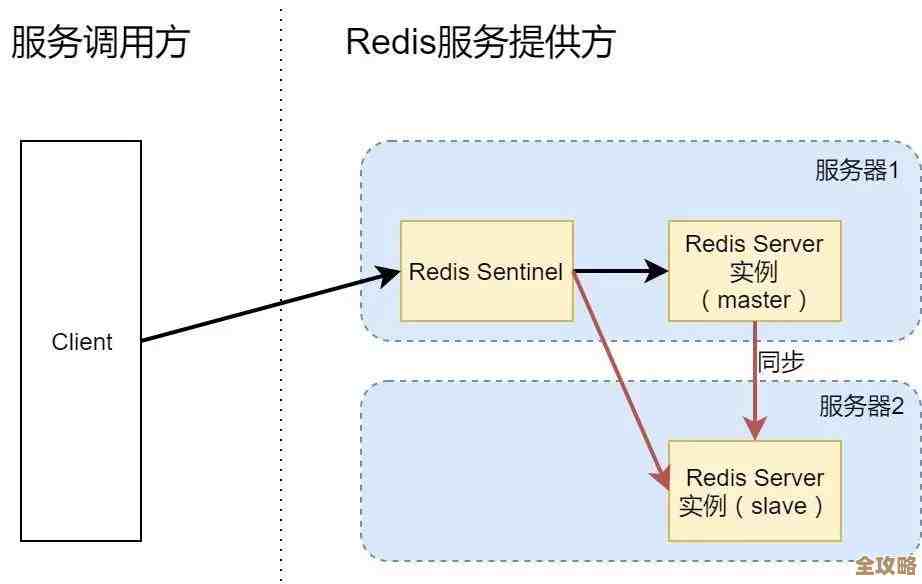
MSSQL到底是锁整张表还是只锁具体行,搞不清楚的纠结点在哪儿?

这个问题的核心纠结点在于,很多人误以为SQL Server在任何情况下都只会选择一种固定的锁策略——要么永远锁表,要么永远锁行,但实际上,SQL Server的锁机制是动态的、智能的、多层次的,它没有一个固定的答案,而是根据你执行的语句、数据库的隔离级别、表的结构以及当前的数据量等因素,由数据库引擎动态决定使用哪种粒度的锁来最优地平衡并发性(多人同时操作不阻塞)和数据一致性(保证数据准确无误)这对矛盾。
纠结点一:误以为锁的粒度是固定的,而非动态选择的。
很多人纠结的开始,是认为“行锁”比“表锁”高级,SQL Server应该总是用行锁,但数据库引擎的思考方式更像一个精明的管家,它的目标是:用尽可能小的锁范围来完成工作,但如果小锁的成本太高,它就会选择更大范围的锁来提升效率。
举个例子,你让管家去书房找一本特定的书(这相当于数据库的查询语句SELECT * FROM Books WHERE BookId = 123),管家很聪明,他直接根据书名索引找到了那本书,然后只在那个书架上做个“正在翻阅,请勿打扰”的小标记(这相当于行锁或键锁),这样,其他人仍然可以自由地去客厅、卧室或其他书架找东西,并发性很好。
如果你的命令是“把书房里所有书都重新整理一遍”(这相当于一个没有WHERE条件的全表更新UPDATE Books SET Status = 'Checked'),这时,管家如果还傻乎乎地给每一本书都单独上锁,再解锁,效率会极低,他更合理的做法是,直接关上书房的门,挂个“整理中,暂停入内”的牌子(这相当于表锁),虽然这暂时阻止了其他人进入书房,但整体工作的效率是最高的。
纠结“锁表还是锁行”的第一个误区,就是没认识到这是一个基于成本和效率的动态决策过程。
纠结点二:混淆了“锁升级”的概念,不明白为什么有时候会从行锁“变成”表锁。
这是最让人困惑的情况之一,用户可能经常遇到:在测试时,操作少量数据,明明看到的是行锁;但到了生产环境,数据量大了,同样的操作却把整张表锁住了,导致其他用户卡顿,这就是SQL Server的锁升级机制在起作用。
锁本身是需要消耗内存和CPU资源的,每一个锁都是一个需要被管理的对象,想象一下,如果有一个操作需要更新10万行数据,数据库引擎如果生成10万个行锁,管理这10万个锁的开销可能会远远超过操作数据本身的成本,为了节省系统资源,当某个单独语句在同一个表上持有的锁数量超过一定阈值(比如5000个),或者锁占用的总内存超过一定限制时,数据库引擎就会“升级”锁,将大量细粒度的行锁合并为一个粗粒度的表锁。
很多人纠结的“为什么有时候锁行,有时候锁表”,很大概率是遇到了锁升级,这解释了为什么在小数据量测试时一切正常(并发性好),一旦数据量上生产就出现严重阻塞(因为触发了锁升级)。

纠结点三:不理解“意向锁”的存在,误以为表上一有锁就是锁全表。
这是另一个非常关键的纠结点,当你查看数据库的锁信息时,可能会看到表上有一个叫“意向锁”的东西,很多人一看到表上有锁,就惊慌地认为“完了,表被锁住了!”,其实不然。
意向锁是一种信号灯或预告机制,它本身并不锁定表里的任何数据,它的作用是表明在表的某个更低层次上已经存在或即将请求锁。
继续用书房的例子:假设管家正在书架的第三层整理书籍(他在第三层上了锁),这时,你想知道整个书房是否需要打扫(相当于你想对整张表进行一个操作),如果没有意向锁,你需要逐个书架去检查是否有人在使用,非常麻烦,而有了意向锁,管家在锁第三层的时候,会先在书房门口挂一个“内部整理中”的牌子(这就是表级的意向锁),你看到这个牌子,就知道虽然书房门开着,但里面已经有人在干活了,你需要等待或询问。
当你看到表上有“意向共享锁(IS)”、“意向排他锁(IX)”时,这并不意味着整张表被锁住了,它仅仅是一个提示,告诉你表里的某些行已经被加锁了,真正的行级锁依然存在,其他用户仍然可以访问那些没有被锁定的行,混淆“意向锁”和真正的“表锁”,是导致人们认为SQL Server动不动就锁表的另一个重要原因。
纠结点四:忽视了“隔离级别”对锁行为的决定性影响。

SQL Server有不同的隔离级别,比如默认的READ COMMITTED,还有REPEATABLE READ、SERIALIZABLE等,隔离级别直接定义了数据库在并发环境下,应该在多大程度上保证数据读写的“隔离性”,而实现不同隔离级别的手段,主要就是通过不同的锁策略。
在默认的READ COMMITTED级别下,一个普通的SELECT查询通常不会加任何锁(或者只加瞬间的锁),它读取的是语句开始时已经提交的数据,所以这种查询基本不会阻塞别人。
如果你将隔离级别设置为SERIALIZABLE(可序列化),为了保证极高的隔离性,防止“幻读”(两次查询中间插入了新数据),数据库引擎可能会在查询时对一个大范围的数据,甚至整个表,加上锁以防止其他事务插入数据,这时,即使你只是查询,也可能导致严重的阻塞。
不考虑当前会话或数据库的隔离级别,孤立地讨论锁行为,是无法得到正确答案的,同样的SELECT语句,在不同的隔离级别下,加的锁可能天差地别。
纠结于“MSSQL锁表还是锁行”这个问题,根本原因在于没有将其视为一个多变量影响的动态系统,主要的纠结点包括:
- 误以为策略固定:实则是引擎基于操作成本动态选择。
- 不理解锁升级:资源消耗过大时,行锁会合并为表锁。
- 混淆意向锁与表锁:意向锁只是信号,不代表表被锁死。
- 忽视隔离级别:不同的隔离级别要求决定了完全不同的锁行为。
要真正理解并解决数据库的锁问题,需要从这些具体的场景和原理入手,而不是寻求一个简单的“是”或“否”的答案。
本文由酒紫萱于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/81249.html