Redis那些算法其实没那么难,跟着我慢慢聊聊它们的原理和应用吧

Redis的万能储物柜
咱们得知道Redis本质上是一个巨大的“键值对”字典,你可以把它想象成一个超大的储物柜,你告诉管理员(Redis)一个钥匙(Key)的名字,他就能瞬间从成千上万个格子里找到对应的那个,并把里面的东西(Value)拿给你,这个“瞬间找到”的本事,靠的就是哈希表。
想象一下,如果一个储物柜没有编号,你要找一个叫“我的暑假作业”的钥匙,你得从第一个格子一直翻到最后一个,那得多慢啊!哈希表解决了这个问题,它用一个特殊的函数(哈希函数),把你的Key(我的暑假作业”)计算成一个数字,这个数字直接对应储物柜的某个编号,这样,管理员一步就能走到那个格子面前。
这里有个小问题:万一两个不同的Key(我的暑假作业”和“我的日记本”)被计算成了同一个编号怎么办?这不就冲突了吗?Redis很聪明,它用了“拉链法”来解决,就像同一个储物柜编号下,它不是一个格子,而是一个小挂钩,可以挂多个钥匙,当发生冲突时,它就把新钥匙挂在同一个编号的挂钩上,查找的时候,先找到编号,再在这个小小的挂钩上挨个对比一下具体的钥匙名就行了,因为每个挂钩上的钥匙通常很少,所以速度依然飞快。
这个哈希表是Redis存储所有数据的基础,理解了它,你就明白了Redis为什么能“快如闪电”地定位数据。
跳跃表:给有序链表装上“电梯”
Redis有一种数据类型叫“有序集合”(ZSET),比如可以用来做游戏排行榜,分数是排序的依据,那它是怎么实现快速排序和范围查找的呢?比如我想找分数在100到200之间的所有玩家,如果用一个普通的链表,我得从头走到尾,太慢了。
Redis用的是跳跃表,这个算法特别形象,想象一栋几十层高的楼,楼梯就是普通的链表,从一楼爬到顶楼很累,但如果我们给这栋楼加几部电梯呢?比如一部电梯每层都停(相当于基础链表),一部电梯隔两层停一次,一部电梯隔四层停一次,还有一部直接从一楼到顶楼。

你想从1楼去20楼,最优的策略是什么?你先坐那部直达顶楼的电梯,它可能停在16楼(因为20楼没到顶楼),然后你换乘那部隔四层停的电梯,它可能停在20楼,你就到了,这个过程你只经过了16楼和20楼两个节点,而不是爬20层楼梯。
跳跃表就是这个原理,它在普通链表的基础上,建立了多级“索引”(就是那些隔层停的电梯),这样在查找时,可以从最高层的索引开始,大步跳跃,逐步缩小范围,最终精确定位,这使得在有序集合里,无论是查找单个元素还是查询一个分数区间,效率都非常高,它比一些复杂的平衡树实现起来简单,但效果却出奇的好。
渐进式Rehash:给飞行中的飞机换引擎
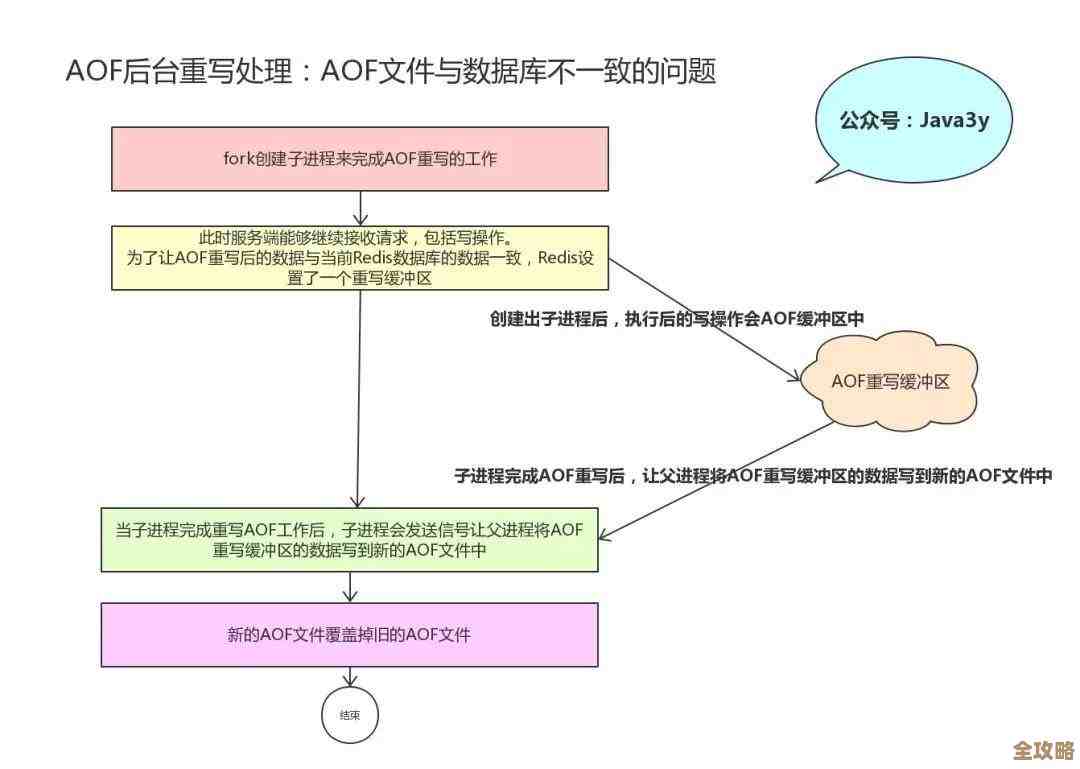
Redis的哈希表虽然快,但当储物柜快满的时候,查找效率会下降(因为挂钩上的钥匙会变多),这时候就需要扩容,也就是换一个更大的储物柜,但Redis是单线程的,如果它停下来,把旧柜子里成千上万的钥匙一口气全部搬到新柜子,那在这段时间内,所有来找它存取东西的用户都得干等着,服务就中断了。
这就像给一架正在飞行的飞机换引擎,不能让它先降落,Redis的解决办法是渐进式Rehash。

它这样做:首先准备好一个新的大储物柜(新哈希表),它并不一次性搬完,而是“挤时间”慢慢搬,每当有用户来请求一个操作(比如读取、写入“我的暑假作业”),Redis在完成这个操作的同时,会“顺便”把旧柜子里这个钥匙对应的格子,以及它旁边的几个格子里的东西,搬到新柜子里去,这样,每次请求只带来一点点额外的搬运工作量,用户几乎感觉不到延迟。
在这段搬迁期间,数据会存在于两个柜子里,查找的时候,Redis会同时查两个柜子,新增的数据则会直接放进新柜子,随着时间的推移,旧柜子里的东西被一点点搬空,直到某个时刻,Redis就会把旧柜子扔掉,完全使用新柜子。
这个设计非常精妙,它保证了Redis在应对数据增长时,能够平滑地过渡,维持高性能服务,不会出现卡顿。
简单总结一下
你看,我们聊了三个核心点:用哈希表实现快速定位,用跳跃表实现高效的范围查询和排序,用渐进式Rehash来实现平滑扩容,这些算法背后的思想并不神秘,都是为了解决非常实际的问题:如何更快、更稳定。
Redis的聪明之处就在于,它没有一味追求最复杂的算法,而是选择了在简单和高效之间取得最佳平衡的方案,理解了这些,你再看Redis,它就不再是一个黑盒子,而是一个设计巧妙的精密仪器了,希望这次的闲聊,能让你对Redis有更亲切的认识。
本文由瞿欣合于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/80986.html