Redis源码文件结构大揭秘,带你看看它到底是怎么组织和实现的

Redis的源码就像一座设计精巧的建筑,虽然功能强大,但它的代码组织得非常清晰,即使不是C语言专家,也能大致看懂它的脉络,咱们就从一个新手打开源码文件夹的视角,来逛逛这座“大楼”。
第一层:进门的大厅(根目录)
刚解压Redis源码包,你会看到一堆文件和文件夹,别慌,最重要的就是那个叫 src 的文件夹,Redis所有的核心源代码都放在这里面,除此之外,根目录下还有一些非常关键的文件,它们是这座建筑的“设计图纸”和“施工手册”:

README.md:这是必读的入门指南,告诉你Redis是什么,怎么编译,怎么运行。Makefile:这是编译的“自动化脚本”,你输入make命令,它就指挥编译器如何把一个个.c文件变成可执行的redis-server。redis.conf:这是Redis服务器的“总控台”和“配置手册”,所有设置,比如端口号、持久化方式、内存大小限制都在这里调整。
第二层:核心功能区(src目录)
走进 src 目录,这才是真正的宝藏之地,里面的文件虽然多,但可以分成几大功能区块,我们一个个看:
服务器的“心脏”和“大脑”(启动与核心逻辑)

server.h和server.c:这是Redis最核心的两个文件,堪称“大脑中枢”。server.h定义了绝大多数重要的数据结构(比如表示整个Redis服务器的redisServer结构,表示每个客户端的redisClient结构)和函数声明。server.c则包含了main函数,也就是程序启动的入口,它实现了事件循环(Event Loop),这是Redis高性能的关键,负责不停地监听网络连接、处理命令。networking.c:专门负责处理网络通信的“神经末梢”,客户端连接、断开、读取命令请求、发送回复数据,这些底层的网络操作都在这里完成。
数据类型的“家园”(数据结构实现) Redis的快,很大程度上得益于其高效的数据结构,每种数据类型都有对应的实现文件:
t_string.c:实现最简单的字符串(String)类型。t_list.c:实现列表(List),底层用了双向链表和压缩列表(现在叫listpack)。t_hash.c:实现哈希表(Hash)。t_set.c:实现集合(Set)。t_zset.c:实现有序集合(Sorted Set),这是最复杂的数据结构之一,内部同时使用了跳跃表(skiplist)和哈希表来保证效率和有序性。- 这些文件里包含了所有命令的实现,比如当你执行
SET key value时,最终就会调用t_string.c里的setCommand函数。
内存的“管家”(底层数据结构和内存管理) 上面提到的数据类型,其底层依赖于更基础的数据结构,这些是Redis自己实现的“轮子”,为了极致优化:
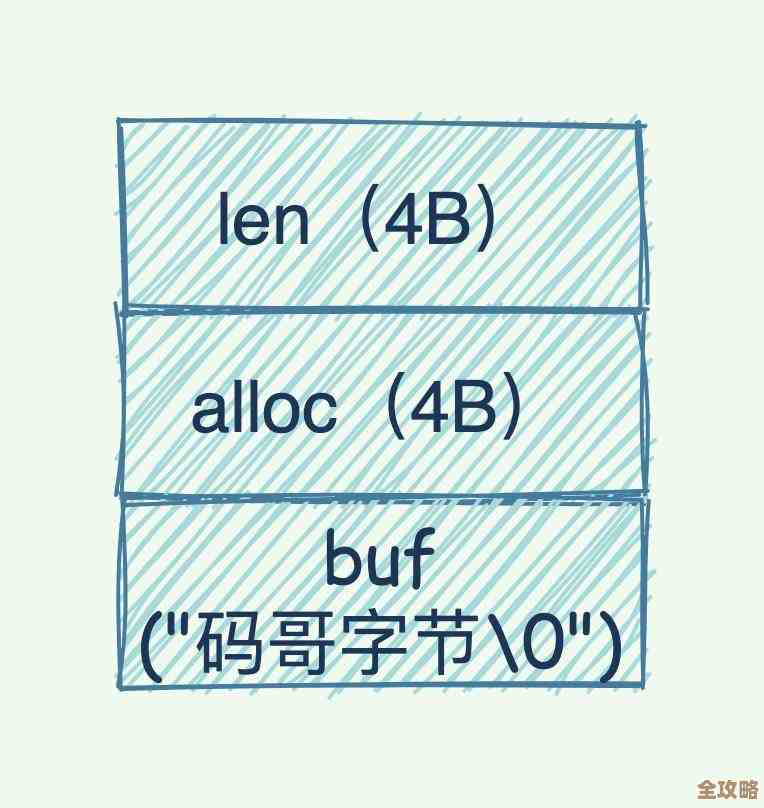
dict.c:实现哈希表,这不仅是Hash类型的基础,Redis整个数据库的键值对存储也是用一个巨大的哈希表来管理的。sds.c:实现简单动态字符串(Simple Dynamic String),这是Redis对C语言原生字符串的封装,解决了长度计算、缓冲区溢出等问题,并且能高效地追加操作。adlist.c:实现双向链表。ziplist.c,listpack.c:实现两种紧凑的列表结构,为了节省内存,常用于小数据量的List、Hash、ZSet的底层实现。zmalloc.c:Redis自定义的内存分配器,它对标准库的malloc/free进行了封装,方便统计内存使用量、发现内存泄漏等。
持久化的“记忆系统”(数据落地到磁盘) 为了保证数据安全,Redis需要把内存数据写入硬盘:

rdb.c:实现RDB持久化,也就是生成数据快照,它负责在特定时间点将整个数据库压缩后保存到一个.rdb文件中。aof.c:实现AOF持久化,类似于写日志,它把每一个写命令记录到一个追加的文件中,重启时重新执行这些命令来恢复数据。
其他重要“器官”
ae.c:实现了抽象的事件驱动器(Apache Event/Libev等库的封装),是事件循环的基础。db.c:实现了数据库相关的核心操作,比如键的增删改查、过期时间设置等。object.c:创建和管理Redis对象(redisObject),Redis的所有数据在内部都被封装成redisObject,里面包含了数据类型、编码方式、引用计数等信息。
总结一下
当你输入 SET name "Redis" 这个命令时,请求的“旅程”大致是这样的:
networking.c接收到来自客户端的命令数据。- 事件循环(
server.c)将这个请求分配给对应的命令处理器。 - 命令处理器(在
t_string.c中)被调用。 - 处理器会调用
db.c中的函数,在数据库(一个存在server.h中定义的redisDb结构里的大哈希表dict)中查找或设置键name。 - 设置值时,可能会用到
sds来存储字符串"Redis",并用object.c创建Redis对象。 - 如果开启了AOF,
aof.c还会把这个命令写入日志文件。 - 通过
networking.c将操作成功的回复发送回客户端。
通过这样的文件结构,Redis将不同的功能模块化,使得代码易于维护和扩展,下次你想了解某个特定功能,比如哈希表是如何扩容的,就可以直接去读 dict.c;想了解持久化细节,就重点看 rdb.c 和 aof.c,这座“大楼”的门牌号,已经非常清晰了。
本文由帖慧艳于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/80578.html