Redis过滤器那些你得知道的实用操作技巧,快速上手不踩坑

咱们得搞清楚Redis过滤器是干嘛的,简单说,它就像一个超级高效的“点名册”或者“检查员”,帮你快速判断一个东西“可能存在”或者“肯定不存在”于一个超级大的集合里,你有上亿个用户名,来了一个新用户注册,你想看看这个用户名有没有被用过,用Redis过滤器来查,速度飞快,而且非常节省内存,但要注意,它有个特点:如果它说“不存在”,那这个元素肯定不在集合里,100%准确;但如果它说“存在”,这个元素有极小的概率其实并不在(这叫误判),不过你可以控制这个误判率。
知道了它能干啥,我们来看看怎么用才顺手不踩坑。
第一招:初始化的时候,别抠门,把容量设大点。
(根据《Redis深度探险》中的建议)这可能是新手最容易栽跟头的地方,你创建过滤器的时候,需要告诉它你大概要存多少元素,比如你估计你的用户最多有100万,那你最好设成120万甚至150万,为什么?因为如果你实际存储的元素超过了最初设定的容量,那么误判率就会急剧上升,这个过滤器就几乎失效了,就像你买了个能装10件衣服的行李箱,硬塞进去20件,结果就是箱子可能爆开,或者衣服皱得没法看,宁可一开始多预估一点,留出余量。
第二招:根据你的“容忍度”来调整精确度。
创建过滤器时,除了容量,你还能设置一个叫“误判率”的参数,默认值一般是0.01,也就是1%,意思是,你查100个不存在的元素,它可能会把其中1个误判成存在,如果你对这个精确度要求很高,比如是做金融风控,一点差错都不能有,那你可以把这个值设得更小,比如0.001(0.1%),但要注意,误判率设得越小,过滤器需要的内存就越大,这就是一个用空间换精度的权衡,对于大多数场景,比如新闻去重、缓存穿透防护,1%的误判率已经完全够用了,别盲目追求极限精度,适合自己的才是最好的。
第三招:一定要知道,标准的Bloom过滤器“只能加不能查”,更不能删!
这是个关键点。(参考了多位技术博客作者如“程序员小灰”的常见问题总结)标准的Bloom过滤器一旦把一个元素加进去,你就只能查询它,你不能把它单独删掉!因为删除一个元素可能会影响到其他也被映射到同一位上的元素,导致其他元素被误判为不存在,如果你需要有删除功能的场景,比如统计一段时间内的独立用户但又要过时剔除,那你应该使用Bloom过滤器的一个变种,叫做布谷鸟过滤器(Cuckoo Filter),它在设计上就支持了删除操作,虽然原理更复杂一些,但Redis企业版或某些模块是支持的,所以在技术选型时,一定要想清楚自己的需求。
第四招:巧用多个过滤器组合,应对复杂场景。
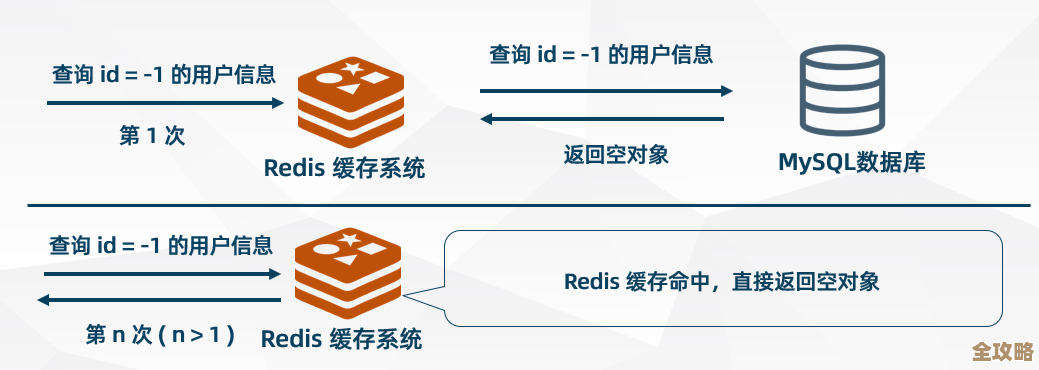
你不要指望一个过滤器解决所有问题,组合拳更好用,经典的“缓存穿透”问题:有人恶意查询一个数据库中根本不存在的数据,导致请求直接打到数据库上,造成压力,这时候,你可以用Bloom过滤器来解决,把数据库里已有的键都放到过滤器里,查询前来过滤器看一眼,如果过滤器说“不存在”,那这个键肯定没有,直接返回,别去查数据库了,这样就保护了数据库。
再比如,(借鉴了开源项目中的设计思路)你可以用多个过滤器来做分层校验,第一层,一个非常宽松的、内存很小的过滤器,快速过滤掉绝大部分明显不合法的请求(比如黑名单IP段),剩下的可疑请求,再送到第二层更精确的过滤器或者数据库里去详细检查,这种“漏斗型”的设计,能极大提高系统的整体效率。
第五招:别忘了它只是个“过滤器”,不是存储!
Redis过滤器非常擅长回答“在不在”这个问题,但它不能告诉你这个元素本身附带的其他信息,你不能用它来存用户的详细信息(姓名、年龄等),它里面存的不是原始数据,而是数据经过计算后的一组“指纹”(位图),它通常是和你真正的数据存储(比如MySQL、Redis的String/Hash类型)配合使用的,先过过滤器这关,如果存在,再去真正的数据库里把完整数据取出来。
实战小贴士:
- 键名规划好:给你的过滤器起个清晰易懂的键名,
bf:users表示用户名的布隆过滤器,方便管理。 - 考虑数据预热:如果系统启动时就知道一批基础数据(比如所有商品ID),最好在服务上线前就批量把这些数据导入过滤器,避免刚开始时大量误判。
- 监控误判率:虽然理论上误判率是可控的,但在生产环境中,还是建议通过监控看看实际的误判情况是否在预期之内。
Redis过滤器是个神器,用对了能极大提升系统性能,核心就是记住它的特性:空间换时间、有微小误判、查询结果绝对正确与否的不对称性,避开容量设小、误删数据这些坑,你就能把它玩得很溜了。

本文由瞿欣合于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/80276.html