那些你总忘记的SQL知识点,整理好了别错过收藏

整理自知乎、CSDN、博客园等技术社区常见讨论帖及个人经验总结)
你是不是有时候写SQL,突然就卡壳了,某个语法怎么都想不起来,或者写出来的结果总是不对?别担心,这太正常了,SQL看似简单,但总有一些细节像“小妖精”一样,在你最需要的时候溜走,我把这些容易忘记的点给你整理了一下,希望能帮你省下反复查文档的时间。
JOIN 连接那些事儿:ON 和 WHERE 的位置陷阱
我们都知道 JOIN 用来连接表,但过滤条件放在 ON 后面还是 WHERE 后面,效果可能天差地别。
- 对于 INNER JOIN(内连接):你把条件放在 ON 后面还是 WHERE 后面,最终结果是一样的,数据库会先根据 ON 条件连接表,再用 WHERE 过滤,但因为内连接只返回匹配的行,所以最终效果没区别,很多人就因此以为所有 JOIN 都一样。
- 对于 LEFT/RIGHT JOIN(左/右外连接):这里就是关键了!条件放的位置不同,结果完全不同。
- 条件在 ON 后面:这个条件是连接条件,它决定了右表(对于 LEFT JOIN)哪些行会被匹配进来,即使右表没有匹配的行,左表的所有行依然会被保留,右表部分以 NULL 填充。
- 条件在 WHERE 后面:这个条件是结果集过滤条件,它是在连接操作完成之后才应用的,这意味着,如果你在 WHERE 子句中对来自右表的字段进行过滤(
WHERE table_b.column IS NOT NULL),它会将那些因为左连接而产生的 NULL 行也过滤掉,这样一来,LEFT JOIN 的效果就瞬间变成了和 INNER JOIN 一样,因为你把左表独有的那些行都删掉了。
简单记:ON 是决定“怎么连”,WHERE 是决定“连完之后留哪些”,搞混了,左连接就白写了。
* COUNT() 和 COUNT(列名) 的区别,不是你想的那样**
你以为 COUNT(column_name) 是统计该列不为 NULL 的行数,而 COUNT(*) 是统计所有行数,这没错,但陷阱在于:
COUNT(*)是 SQL 标准中规定的统计行数的方法,数据库会对它进行优化,速度通常很快。COUNT(1)和COUNT(*)在绝大多数现代数据库管理系统(如 MySQL, PostgreSQL)中,性能几乎没有区别,数据库优化器很聪明,知道你的意图,所以不必纠结用哪个。- 真正的区别在于
COUNT(column_name),它会先取出该列所有的值,然后判断每个值是否为 NULL,再计数,如果该列上有索引,数据库可能会选择扫描更小的索引来计数,这会比COUNT(*)快,但如果该列允许 NULL 值,且 NULL 值很多,或者没有索引,那性能可能就不如COUNT(*)了。
*如果你只是想统计表里有多少条记录,放心大胆地用 `COUNT()`。**
GROUP BY 分组后的筛选:HAVING 和 WHERE 的“职权范围”
这个点初学时分不清,老手偶尔也会糊涂。
- WHERE:在 GROUP BY 分组之前 进行过滤,它用来排除那些你根本不想参与分组计算的个体记录,它后面不能跟聚合函数(如 SUM, AVG),你想计算每个部门工资超过5000元的员工的平均工资,工资>5000”这个条件就要放在 WHERE 里。
- HAVING:在 GROUP BY 分组之后 进行过滤,它用来过滤分组后的结果集,是针对“一组数据”的过滤。HAVING 后面可以跟聚合函数,你想找出平均工资大于10000元的部门,“AVG(工资) > 10000”这个条件就必须放在 HAVING 里。
口诀:WHERE 管“个体”,HAVING 管“团体”,先 WHERE 过滤,再 GROUP BY 分组,HAVING 筛选团体。
查询语句的执行顺序,和你的书写顺序不一样
我们习惯按 SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... 的顺序写,但数据库执行时可不是这个顺序!
大致的执行顺序是:
- FROM 和 JOIN:先确定数据来源,把表连接起来。
- WHERE:对连接后的原始数据行进行过滤。
- GROUP BY:对过滤后的数据进行分组。
- HAVING:对分组后的数据集合进行过滤。
- SELECT:选择要输出的列,并计算 SELECT 中的表达式(如聚合函数、字段运算)。
- DISTINCT:去除重复行。
- ORDER BY:对最终结果进行排序。
- LIMIT/OFFSET:截取部分结果。
理解这个顺序非常重要!它能解释为什么你不能在 WHERE 子句中使用 SELECT 里定义的别名(因为 WHERE 执行时,SELECT 还没执行),而可以在 ORDER BY 里使用(因为 ORDER BY 在 SELECT 之后执行)。
NULL 值带来的“坑”
NULL 表示“未知”或“不存在”,它和任何值(包括它自己)比较,结果都不是 TRUE,而是 NULL(在条件判断中被视为 FALSE)。
= NULL是错误的写法,永远返回 NULL(假),判断是否为 NULL,必须用IS NULL或IS NOT NULL。- 当 NULL 参与到算术运算(如 )或逻辑运算时,结果通常是 NULL。
SELECT NULL + 5的结果是 NULL。 - 在使用
DISTINCT、GROUP BY或UNION时,多个 NULL 值会被视为相同的值,只保留一个。
索引失效的常见小动作
你知道加了索引会快,但有时候感觉没效果?可能是你无意中让索引失效了。
- 在索引列上使用函数或表达式:
WHERE YEAR(create_time) = 2023会导致create_time上的索引失效,应该写成WHERE create_time >= '2023-01-01' AND create_time < '2024-01-01'。 - 使用左模糊或全模糊查询:
WHERE name LIKE '%张'或WHERE name LIKE '%张%'会导致索引失效,只有右模糊'张%'可能用到索引。 - 对索引列进行运算:
WHERE salary * 10 > 10000会导致salary索引失效,应改为WHERE salary > 10000 / 10。 - 使用 OR 连接条件:OR 连接的条件中有一个列没有索引,那么整个查询可能都无法使用索引。
这些点看似零碎,但在实际查询和性能优化中至关重要,希望这份整理能像一个随时可查的备忘录,帮你稳住SQL的“基本盘”。

本文由钊智敏于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/80058.html
相关文章
-

Redis终端里怎么快速搞定任务,别光看界面说复杂了
-

Redis里那些用户名单,可能比你想象的还重要,别忽视了用户列表管理
-
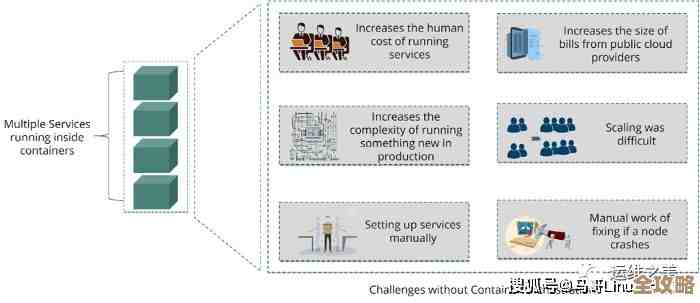
企业在扩展容器和Kubernetes应用时常遇到的那些棘手又现实的问题,真不是说说那么简单
-

PostgreSQL遇到transaction_integrity_constraint_violation错误,远程怎么快速修复故障分享
-
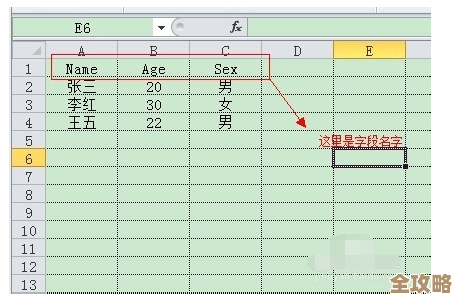
用Excel表格来管数据库其实没那么难,轻松上手就能搞定数据管理的那些事儿
-

ORA-12200内存分配失败,远程帮忙修复ORACLE连接问题
-
用Redis做签到那些事儿,踩过的坑和没想到的问题分享
-
MySQL报错MY-013952,缓冲池调整失败,远程帮忙修复问题