选分布式任务调度框架其实没那么简单,得考虑好多因素和场景适配问题

(来源:知乎专栏《架构师成长笔记》)
选分布式任务调度框架这件事,听起来好像就是找个能定时跑脚本的工具,但真做起来,会发现里面门道很深,根本不是简单对比几个功能列表就能拍板的,这就像给一个复杂的大家庭请管家,不是会做饭、会打扫就行,还得摸清这家人的脾气、家里的规矩,以及未来可能添丁进口的变化,你得考虑好多实实在在的因素,得和你自己的业务场景严丝合缝地对上才行。
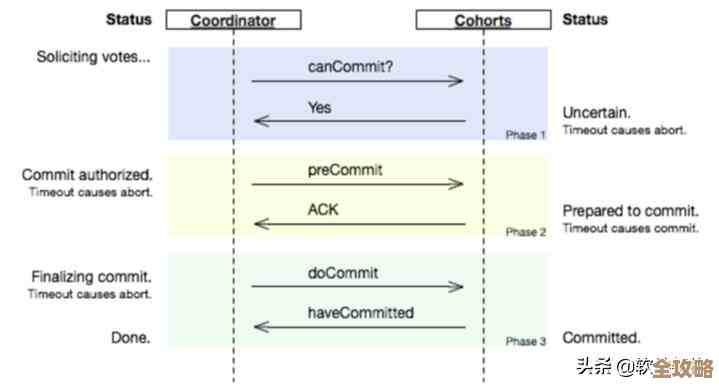
最基础但也最要命的一点,就是任务到底可不可靠。(来源:某技术团队博客分享的线上故障复盘)你说你设了个半夜两点清理日志的任务,结果因为调度器所在的机器宕机了,或者网络抽风了一下,任务根本没执行,第二天早上磁盘就被撑爆了,服务全挂,这种事儿在线上是灾难性的,你得看这个调度框架能不能做到高可用,是不是有主备机制,一台机器挂了另一台能立刻顶上,还有就是任务执行失败了会不会有重试机制,重试的策略灵不灵活,比如是立即重试还是等几分钟再试,最多试几次,更关键的是,任务执行到一半,因为服务器重启之类的缘故中断了,下次调度是重新开始还是能从断点继续?这些细节直接关系到你晚上能不能睡个安稳觉。

得想想任务怎么管理,出了问题怎么排查。(来源:InfoQ某次架构峰会上的演讲)如果你的系统里就十几个定时任务,那用个简单的界面,甚至看日志都还行,但当成百上千个任务在集群里跑的时候,没有一个清晰的管理控制台就简直是一场噩梦,你需要在界面上清楚地看到:哪些任务正在跑,哪些在排队,哪些失败了,失败的具体错误日志是什么,能不能方便地手动触发一次任务,或者立即停止一个跑偏了的任务,有没有报警功能,任务失败后能第一时间发通知到钉钉、企业微信或者短信,这些运维上的便利性,会极大影响开发和运维团队的工作效率。
再来,任务之间的时间和依赖关系也是个大学问。(来源:Github上某知名开源调度框架的Issue讨论)现实中的任务很少是孤立的,你必须等每天的订单数据同步任务跑完了,才能开始跑数据分析报表任务;或者每个月的1号凌晨,要同时触发几十个结算任务,但它们不能把数据库拖垮,得一个个按顺序来,这时候,框架是否支持基于Cron表达式的复杂定时,是否能配置任务间的依赖关系(比如A成功后才触发B),是否支持分片广播(把一个大数据处理任务拆成很多小片,分给不同的机器同时执行),就变得至关重要,处理不好,整个数据流就乱套了。

还得掂量一下和现有技术栈的融合成本。(来源:CSDN开发者调查报告)你的团队主要用Java还是Go?框架提供的API是否简单易用?跟Spring Cloud、Dubbo这类微服务框架整合起来顺不顺手?需不需要为了接入它而大幅度修改现有代码?任务执行器是嵌入到业务应用里,还是可以独立部署?这些技术细节决定了开发的难度和后期维护的成本,选择一个和团队技术口味相差太远的框架,会让大家用起来非常别扭。
但绝非不重要的是,开源社区的活力和商业支持。(来源:多位技术选型专家的经验总结)你选了一个看起来很美的开源框架,结果发现项目已经两年没更新了,文档残缺不全,提个问题半年没人回,或者遇到一个紧急的Bug,只能自己吭哧吭哧去读源码解决,这风险就太大了,一个活跃的社区意味着持续的迭代、快速的Bug修复和丰富的实践经验分享,如果你的业务非常核心,可能还需要考虑是否有商业公司提供付费支持,能在关键时刻帮你兜底。
所以说,选型真不是个简单活儿,它不是一个纯技术问题,而是一个结合了业务可靠性要求、团队运维习惯、技术栈匹配度和社区生态的综合决策,在没有彻底搞清楚自己的场景和需求之前,盲目跟风选择最火的框架,很可能在后期会付出巨大的代价,最好的办法是,先把自己团队的任务类型、量级、可靠性要求、运维能力等方方面面都列出来,然后拿着这份“需求清单”去逐个对照候选框架,才能找到那个最适合你的“管家”。
本文由盈壮于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79961.html