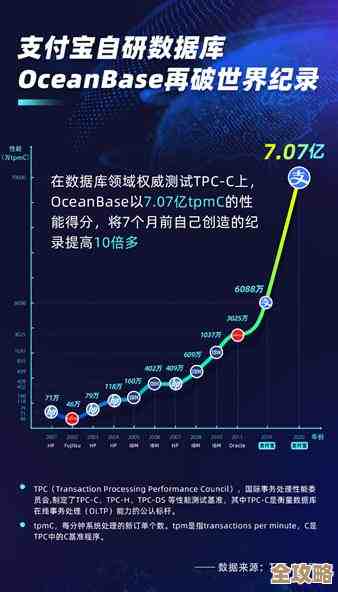
高级数据库系统的深入理解和实际操作探索,结合阶段性学习心得分享

最开始接触数据库,我以为它就是个大表格软件,比如Excel,只不过能存更多数据,学习MySQL这类关系型数据库后,我明白了“表”、“行”、“列”、“主键”、“外键”这些基础概念,也学会了用SQL语句进行增删改查,这就像学会了开车的基本操作:点火、挂挡、踩油门、打方向盘,你能上路了,但仅限于平坦的铺装路面。
所谓“高级数据库系统”,在我看来,就是让你能应对各种复杂路况的“特种车辆”和“驾驶技术”,我的探索是从意识到关系型数据库的局限性开始的,我记得当时做一个个人项目,想存储用户的动态信息,比如一条朋友圈,里面可能包含文字、图片、多个点赞用户、一堆评论,如果硬用关系型数据库来设计,我得拆分成“文章表”、“图片表”、“点赞表”、“评论表”好几张表,每次查询都要进行复杂的多表连接(JOIN),尤其当数据量变大后,速度慢得让人难以忍受。
这时,我接触到了NoSQL数据库,比如MongoDB,这对我来说是第一个“高级”的冲击,它用类似JSON的文档格式来存储数据,上面说的那条朋友圈,完全可以直接存成一个文档,所有相关信息都嵌套在里面,一次查询就能拿到全部数据,太方便了,我实际操作了一下,那种灵活性和读取速度的提升是立竿见影的,我意识到,数据库的世界远不止一种解决方案,选择哪种数据库,取决于你的数据结构和应用场景,这就是从“一招鲜”到“看菜吃饭”的思维转变。
但很快,新的问题又来了,NoSQL虽然灵活快速,但在需要跨多个文档进行复杂查询、特别是需要严格的数据一致性和事务支持(比如银行转账,必须保证一个账户扣款成功的同时另一个账户入账成功)的场景下,就显得力不从心,这让我陷入了困惑:难道鱼和熊掌真的不可兼得吗?
带着这个问题,我进入了更深入的探索阶段,了解了NewSQL数据库(如TiDB)和一些分布式数据库的理念,这些系统试图兼顾关系型数据库的强一致性和NoSQL的可扩展性,它们通过将数据分片(Sharding)存储在多台机器上,并通过复杂的协调机制来保证数据的一致性,虽然这部分的理论非常深奥,但我通过搭建简单的TiDB集群实验,直观地感受到了它的能力,我可以像使用MySQL一样写SQL语句,但随着数据增长,可以通过增加机器来线性提升性能,这简直太酷了,这个过程让我明白,高级数据库系统的核心挑战之一,就是在“一致性”、“可用性”和“分区容错性”之间做权衡(这也就是著名的CAP理论,虽然我不想用术语,但这是理解这个问题的关键基石)。
另一个让我大开眼界的“高级”概念是列式存储数据库,比如Apache Cassandra和ClickHouse,传统的行式数据库是按行存储的,读一条记录会把它所有列的数据都读出来,而列式存储是把每一列的数据单独存放,这对于需要进行大规模数据分析(OLAP)的场景是革命性的,我想分析一亿用户中有多少人年龄大于30岁,在行式数据库中需要读取一亿行数据,而在列式数据库中,只需要读取“年龄”这一列,速度天差地别,我尝试用ClickHouse处理了一个几GB的日志文件,进行聚合查询的速度比MySQL快了上百倍,这让我深刻体会到,数据的“存法”直接决定了它的“用法”。
回顾我的学习历程,心得如下:
-
从工具使用者到架构思考者: 初级阶段是学习如何使用一个工具,高级阶段则是学习如何为不同的问题选择甚至组合不同的工具,现在面对一个项目,我会先分析它的数据模型、读写比例、一致性要求、扩展性需求,再决定数据库选型,甚至采用多类型数据库共存的“多模”架构。
-
理论结合实践是关键: 光看CAP理论、ACID属性这些概念是空洞的,只有当你真正在MongoDB中遇到数据不一致的坑,或者在MySQL分库分表时感受到复杂性,你才能真正理解这些理论的价值,动手搭建环境,用真实的数据集进行测试,是理解高级数据库最有效的途径。
-
没有银弹: 这是我最大的收获,没有任何一种数据库是完美的,能解决所有问题,所谓的高级,不是找到了一个终极答案,而是拥有了分析问题、权衡利弊、并选择最适合技术方案的能力,关系型、文档型、键值型、列式、图数据库……它们就像工具箱里的不同工具,高手不是只会用锤子,而是知道什么时候用螺丝刀,什么时候用扳手。
对高级数据库系统的探索,是一个不断打破认知、又重建认知的过程,它让我不再局限于单一的数据库产品,而是从一个更宏观的视角去理解数据流动、存储和计算的哲学,这条路还很长,但每解决一个实际问题,每理解一个新的概念,都让人感到兴奋。

本文由雪和泽于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79738.html