Redis出错那些坑和解法,聊聊解决难题背后的小窍门

说到用Redis,它确实快得像闪电,能帮我们解决很多性能瓶颈,但俗话说得好,“天下没有免费的午餐”,用Redis省了事,就得在别的地方多操心,很多新手甚至老手,都可能在几个常见的坑里栽跟头,今天咱们就聊聊这些坑,以及怎么从坑里爬出来的小窍门,这些经验很多都是从社区里大家血与泪的教训,比如一些技术博客像“阿里云开发者社区”、“掘金”上不少高手分享,还有官方文档的提醒里总结出来的。
第一个大坑:缓存穿透——疯狂查询一个根本不存在的数据。
这场景就像是你去一个巨大的图书馆,反复问管理员要一本根本不存在的书,管理员每次都得翻遍整个目录,累个半死,却永远找不到,对应到Redis,就是客户端疯狂请求一个在数据库里根本不存在的数据,这个数据在Redis里自然没有(缓存未命中),于是请求就直接打到后端的数据库上了,如果这种恶意攻击或者业务bug导致的无效请求量非常大,数据库可能就直接被压垮了。
小窍门和解法:
- 缓存空对象: 这是最直接的办法,就算在数据库没查到,我们也把这个不存在的Key写进Redis,给它赋一个空值(比如
null)并设置一个较短的过期时间(比如1-5分钟),这样,在过期时间之内,同样的无效请求再来,Redis就能直接返回空值,保护了数据库,但缺点是会占用一点内存,而且可能有一段时间的数据不一致(如果这个数据后来被真实创建了)。 - 使用布隆过滤器: 这是个更高级也更省内存的武器,布隆过滤器可以高效地判断一个元素“一定不存在”或“可能存在”于一个集合中,我们在系统启动时,把所有合法的、可能被查询的Key预先加载到布隆过滤器中,当请求来时,先让布隆过滤器检查一下:如果它说“肯定不存在”,那就直接返回空,连Redis都不用查了;如果它说“可能存在”,再继续走正常的缓存查询流程,这就像在图书馆门口放一个智能门禁,它一眼就知道你要的书大概率没有,直接把你劝退了,根本不用麻烦管理员,很多公司像微博就用这个方法来应对热点事件中海量的用户查询。
第二个大坑:缓存雪崩——大量缓存数据在同一时刻集体失效。
想象一下,Redis里有一大批Key,好巧不巧,都把过期时间设置成了相同的值,结果在某个午夜钟声敲响的时刻,这些Key集体“死亡”了,瞬间,所有请求这些数据的流量,像雪崩一样毫无遮挡地砸向数据库,数据库根本扛不住这种压力,直接宕机。
小窍门和解法:
- 给过期时间加随机值: 这是避免雪崩最经典也最有效的办法,不要把所有Key的过期时间都设为一样的5分钟,我们可以采用“基础过期时间 + 随机秒数”的策略,比如基础是5分钟,再加上一个0到60秒的随机数,这样就能保证Key是均匀地、分散地失效,把对数据库的冲击分摊到不同的时间点上,化整为零。
- 设置永不过期的热点数据: 对于一些极其关键、访问频率极高的热点数据,可以考虑设置为永不过期,然后通过后台任务或者程序逻辑,在数据更新时主动去更新Redis里的缓存,这种做法牺牲了一定的灵活性,但换来了核心服务的极致稳定性。
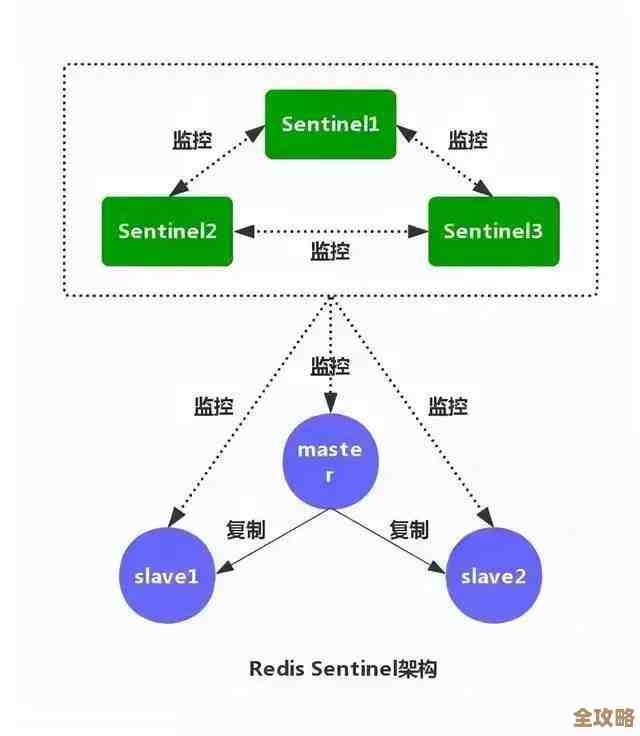
- 构建高可用的Redis架构: 单节点的Redis一旦挂掉,那就不只是雪崩,简直是“冰川世纪”了,所以生产环境一定要用主从复制(Replication)加哨兵(Sentinel)模式,或者直接用Redis Cluster集群模式,这样即使一个节点挂了,其他节点还能继续提供服务,系统整体不至于瘫痪。
第三个大坑:缓存击穿——一个热点Key过期,瞬间海量请求压垮数据库。
这个坑和雪崩有点像,但破坏力更集中,它指的是某一个热点Key(比如某个顶流明星的微博)在失效的瞬间,持续有大量的并发请求过来,这个Key一失效,所有请求发现缓存没了,于是齐刷刷地去数据库查询,并且同时去重建缓存,这个瞬间的并发压力非常可怕。
小窍门和解法:
- 热点Key永不过期: 和应对雪崩的策略一样,对于明确的顶级热点数据,这是最稳妥的办法。
- 加互斥锁: 这是解决击穿问题的核心思想,当第一个发现缓存失效的请求到来时,它先去获得一个分布式锁(可以用Redis的
SETNX命令实现),然后由这个请求去数据库查询数据并重建缓存,在这个过程中,其他并发请求发现缓存失效且抢锁失败后,不是傻等着去查数据库,而是可以选择短暂休眠一下,然后重试查询缓存,这样,大量请求中只有一个“幸运儿”会去访问数据库,其他请求最终都能从新构建的缓存中拿到数据,这就像一群人在一扇门前等着,只让第一个人进去修门,其他人在外面等着修好再进,而不是一窝蜂把门挤垮。
第四个大坑:数据不一致——数据库改了,缓存还是老样子。
这是业务逻辑上的一个经典难题,当我们更新了数据库的数据后,是应该先更新缓存还是先删除缓存?顺序不一样,在高并发下可能带来截然不同的结果,先删缓存再更新数据库,可能在删除后、更新前的极短间隙里,另一个请求发现缓存没了,就去数据库读了旧数据并塞回了缓存,导致脏数据残留,反之,先更新数据库再删缓存,也可能在删除缓存前有请求读到旧数据。
小窍门和解法:
- 简单策略:先更新数据库,再删除缓存。 这是业界更推荐的一种方式,出现脏数据的概率相对较低,虽然不保证100%强一致,但保证了最终一致,对于绝大多数业务场景来说已经足够。
- 复杂策略:延迟双删。 为了应对上面提到的极短时间窗口问题,可以在“先更新数据库,再删除缓存”之后,再启动一个延迟任务(比如几百毫秒后),再次删除一次缓存,这样能尽可能地清除掉在间隙中可能被写入的脏数据。
- 接受最终一致性: 首先要明确,引入缓存本身就是为了性能牺牲强一致性,所以要跟业务方沟通好,是否可以接受秒级的数据延迟,如果能接受,很多问题就简单多了。
用Redis就像开车,车性能再好,也得懂交规、会保养,不然迟早出事故,核心思路就是:防患于未然(合理设置过期时间、用布隆过滤器)、构建冗余(搭建高可用集群)、控制并发(用锁保护关键资源)、明确预期(接受最终一致性),把这些小窍门记在心里,就能让Redis真正成为你得心应手的利器,而不是系统里的一颗定时炸弹。

本文由钊智敏于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79593.html