Redis实现高效自增ID生成,快速驱动分布式系统里的唯一标识怎么搞

主要综合了网络上的技术博客和实践分享,例如来自CSDN、博客园、开发者社区等平台多位技术专家的常见方案,以下是对这些常见思路和方法的直接汇总)
在分布式系统里,给每一条数据、每一个订单或者每一次请求打上一个独一无二的标识符,是个挺常见但又很关键的需求,这个标识符不能重复,最好还能大概看出生成的顺序,像数据库的自增ID在自己家里挺好用,但一到分布式环境,多个应用实例各有各的数据库,自己增自己的,很容易就冲突了,这时候,Redis因为它速度极快、单线程操作保证原子性的特点,就成了一个实现分布式ID生成器的好帮手,它的核心原理就是利用一个简单的INCR命令。
最基础的办法就是直接用INCR命令,你在Redis里设置一个键,比如叫global:unique_id,然后每次需要新ID的时候,就让一个应用实例去Redis那里执行一下INCR global:unique_id,这个命令很棒的一点是,它是原子性的,意思是就算成千上万个请求同时过来,Redis也会排着队一个一个处理,绝对不会返回重复的值,第一次执行返回1,第二次返回2,就这么一直递增下去,这种方法实现起来超级简单,几行代码就能搞定,性能也非常高,因为Redis处理这种简单命令的速度是极快的。
这个最简单的方案有个明显的缺点:生成的ID是连续的纯数字,这在有些场景下可能不太合适,比如你不想让外界轻易猜到你的订单总量或者用户增长量,如果Redis需要重启,虽然可以通过持久化机制(RDB或AOF)恢复数据,但如果没来得及持久化,可能会有ID重复的风险(虽然概率低,但需要考虑),这个ID除了递增,没有包含其他任何信息。

为了应对这些不足,人们想出了改进的方案,一个很常见的模式是“前缀 + 时间戳 + 自增序列”的组合方式,举个例子,我们可以生成一个像20240524000001这样的ID,这里的20240524是今天的日期,000001是当天的自增序号,实现起来也不复杂:键名要能体现日期,比如order_id:20240524,每天第一次生成ID时,这个键可能不存在,所以可以先执行INCR order_id:20240524,Redis会自动从1开始,这样,同一天内的ID是连续的,但到了第二天,键名变了(变成order_id:20240525),序号又会从1开始,这种方案的好处是ID里带上了时间信息,方便按时间范围进行查询;而且每天的ID是独立的,不像纯自增那样容易被推测总体规模。
还有一种更精细的优化,是结合机器标识或业务标识来生成ID,在庞大的分布式系统中,可能部署了成千上万台服务器,如果所有服务器都去操作Redis中央节点的一个键,虽然Redis能扛住,但网络延迟可能会成为瓶颈,为了减轻中央节点的压力,可以采取一种“分段”的思路,可以给每台应用服务器分配一个唯一的机器ID(比如从0到1023),生成的ID结构可以是这样的:时间戳(毫秒级) + 机器ID + 自增序列,这里的自增序列部分,每台机器可以自己维护一个本地的计数器(比如从0到999),这样在一毫秒内,一台机器最多可以生成1000个不重复的ID,只有当本地序列用尽时,才需要等待到下一毫秒,或者去Redis申请一个新的序列号段,这种方案大幅减少了对Redis的请求频率,性能更高,扩展性更好,像Twitter的Snowflake算法就是这种思想的经典体现,而Redis可以用来辅助分配和管理这些机器ID,或者作为序列号的“发号器”。

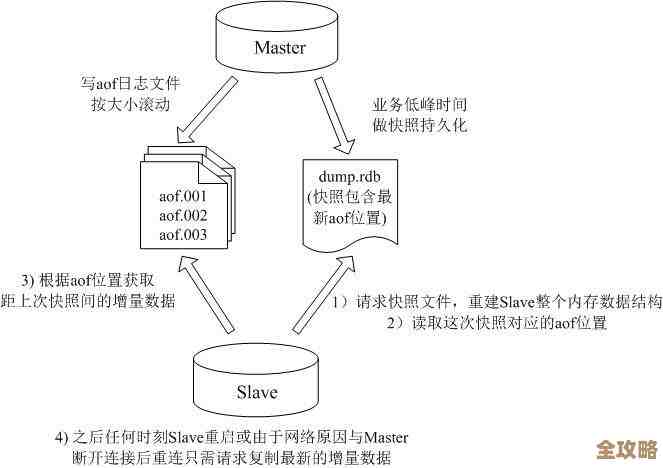
在实际用Redis做自增ID生成时,需要注意哪些问题呢?首先是Redis的持久化,为了避免重启导致ID重复或跳变,一定要配置合适的持久化策略,AOF持久化可以保证每条INCR命令都记录日志,数据安全性最高,但可能会对性能有轻微影响,RDB是定时快照,在两次快照之间如果宕机,会丢失一部分最新的ID增长记录,导致重启后ID不连续(可能会出现跳号),但一般不会重复,根据业务对ID连续性和重复性的容忍度来选择合适的策略。
高可用性,如果整个系统只依赖一个Redis实例,一旦这个实例宕机,整个系统的ID生成服务就中断了,这是单点故障风险,为了解决这个问题,必须搭建Redis高可用架构,最常见的是Redis主从复制(Replication)配合哨兵(Sentinel)机制,主从复制是指设置一个主节点(Master)负责写操作(如INCR),一个或多个从节点(Slave)同步主节点的数据,哨兵则是一个监控系统,它持续监控主节点是否健康,一旦发现主节点宕机,它会自动从从节点中选举出一个新的主节点,并将客户端连接切换到新主节点上,从而保证服务不间断,这样,ID生成器就具备了故障自动恢复的能力。
键的设计也要有讲究,如果是按天生成的ID,那么旧的键(比如几天前、几月前的)会一直留在Redis里占用内存,需要定期清理这些过期的键,或者给它们设置过期时间(TTL),但设置过期时间要小心,确保在过期之前不会再有用到它的业务逻辑。
用Redis实现分布式自增ID生成,核心就是发挥其INCR命令的原子性和高性能优势,从最简单的连续自增,到结合时间戳、业务前缀的复合ID,再到借鉴Snowflake思想的分段优化,方案可以根据业务的复杂度、数据量和性能要求灵活选择,通过配置持久化和搭建主从哨兵集群,可以确保ID生成服务的可靠性和高可用性,从而快速、稳定地为分布式系统提供全局唯一的标识符。
本文由酒紫萱于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79145.html