怎么才能靠谱地知道Redis到底还在不在线,别光看表面状态就完事了

想知道Redis是不是真的在线,光靠眼睛瞄一眼进程在不在,或者敲个ping命令看到个PONG回应,很多时候是远远不够的,这就好比你去检查一个人的健康状况,不能只看到他还在喘气就断定他身体没问题,你得让他走两步、跑一跑,看看心脏、血压是不是都正常,对于Redis这个关键的“数据心脏”,我们需要更深入、更靠谱的检查方法。
第一层检查:别被“僵尸”进程骗了
最基础的,你可能会用ps或者systemctl status redis这样的命令(来源:Linux系统管理常识),这确实能告诉你Redis的进程有没有在运行,但这里有个大坑:万一Redis进程虽然还在,但它已经“卡死”了,不响应任何请求了呢?这就成了一个“僵尸”进程,进程存在只是最最底线的条件,连及格线都算不上。

第二层检查:动口问问,看它答不答应
大家最常用的就是通过Redis客户端发送一个命令,比如PING,如果Redis回复PONG,说明它能接收并处理命令,这比只看进程进了一步,但这个方法依然比较表面,因为它只测试了最基本的通信和响应能力,也许Redis此时正承受着巨大的内部压力,比如正在做持久化(把数据写到磁盘上)、或者有超级耗时的命令在执行,导致它虽然能回应简单的PING,但已经快撑不住你真正的业务请求了。
第三层检查(关键一步):让它干点“轻活儿”,看表现

要想更靠谱,就不能只问“在吗?”,而得让它实际做点小事,同时观察它的表现,这里有几个实用的方法:
- 测一下延迟(Latency):Redis自带了一个非常好的诊断工具叫
redis-cli --latency(来源:Redis官方文档),你运行这个命令,它会持续向Redis发送PING命令,并精确计算出每次往返所花的时间,你不仅能看出平均延迟,还能看到最差情况下的延迟,如果延迟变得很高,或者波动非常剧烈,即使Redis没有宕机,对你的应用来说,它也已经处于一个“不健康”的状态了,因为响应太慢了。 - 执行一个无害的读写命令:你可以定期执行一个
SET check_health "test" EX 1这样的命令(来源:Redis命令参考),这个命令的意思是,设置一个叫check_health的键,值为"test",并且让它1秒后自动过期,这样做的好处是:- 测试了写能力:确认Redis能正常接收并执行写入操作。
- 测试了过期键处理能力:Redis需要正常处理过期逻辑。
- 避免了垃圾数据:由于设置了很短的过期时间,这个测试键会自动消失,不会污染你的数据。
- 然后你再立刻跟着一个
GET check_health命令,确认能正确读到刚写入的值,这就测试了读能力,这一套小连招,比单纯的PING有说服力得多。
第四层检查(贴近实战):模拟真实用户的行为
最靠谱的方法,是尽可能模拟你的应用程序真实使用Redis的方式,这需要你对自己业务如何使用Redis有了解。

- 检查关键数据:如果你的应用严重依赖某个特定的键(比如一个全局配置、一个计数器),你可以写一个监控脚本,定期去读取这个键的值,确保不仅能读到,而且值是正确的、最新的,如果这个关键数据读不到或者异常,哪怕Redis本身
PING是通的,对你的业务来说也是故障。 - 模拟核心操作:假如你的应用核心是使用Redis的
LPUSH和BRPOP命令实现一个任务队列,那么你的健康检查脚本就应该实际执行一次LPUSH(插入一个测试任务)和BRPOP(弹出这个任务),并验证任务内容,这个过程完整测试了你的业务逻辑所依赖的Redis功能是否完好。 - 检查从库(如果有的话):如果你用了主从复制,光检查主库是不够的,你还得检查从库是否在线(
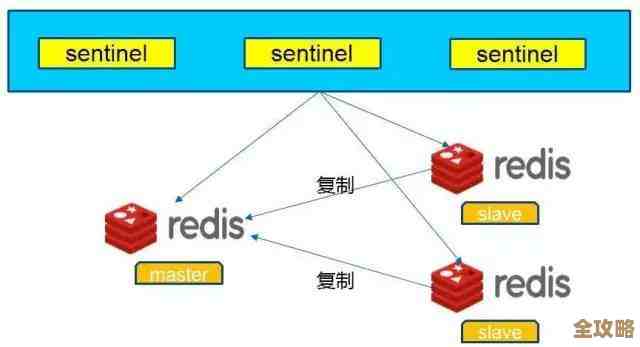
INFO replication命令,来源:Redis命令参考),以及它和主库的复制延迟有多大,万一主库挂了,你需要切换到一个数据最新的从库,如果从库本身数据落后太多,切换过去也会出问题。
第五层检查:看看它的“体检报告”
Redis提供了一个强大的INFO命令(来源:Redis官方文档),它能返回一个包含海量内部信息的报告,对于健康检查,我们可以重点关注这几项:
connected_clients:当前有多少个客户端连着,如果这个数异常的高,可能意味着有连接泄漏,或者正在被攻击。used_memory:Redis已经使用了多少内存,如果这个值接近你设置的最大内存限制(maxmemory),Redis可能会开始根据策略删除数据,或者拒绝写入请求,这非常危险。rdb_last_bgsave_status和aof_last_bgrewrite_status:如果开启了持久化,这两项告诉你上一次后台保存数据(快照)或重写日志文件是否成功,如果状态是err,说明持久化失败了,这意味着你的数据有丢失的风险,即使服务在线,也是不健康的。keyspace_hits和keyspace_misses:这可以计算出缓存命中率,如果命中率突然暴跌,可能意味着缓存出现了大规模失效或被误清,会导致大量请求直接压到后端数据库上。
想知道Redis是否真的靠谱在线,需要一个由浅入深的检查清单:
- 基础:进程是否存在。
- 入门:能否响应
PING。 - 进阶:测量延迟、执行简单的读写和过期测试。
- 专业:模拟业务核心逻辑进行端到端检查。
- 全面:结合
INFO命令,查看内存、持久化、复制等内部关键指标。
最有效的监控,往往是结合多个层面的检查,一个完整的健康检查脚本可以:1) 通过TCP端口检测进程可连接性;2) 发送PING;3) 执行一个带过期的设置和读取操作;4) 检查INFO命令输出中的内存和持久化状态,只有当所有这些检查都通过时,你才能比较有把握地说:“嗯,Redis现在很健康,很靠谱。”
本文由盈壮于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79040.html
相关文章
-

MySQL报错MY-010143,ER_THE_USER_ABIDES到底啥意思,远程帮忙修复下吧
-

ORA-07271报错搞不定?spwat进程号出错,远程帮你快速修复问题
-

Redis里给值定时不拖延,超时设置马上生效的那些事儿
-
Redis 持久化怎么清理掉,数据存储方式改了之后还得注意啥问题
-
MySQL报错ER_GRP_RPL_FAILOVER_CONF_CHANNEL_DOES_NOT_EXIST,远程故障处理和修复方法分享
-

怎么快速知道你SQL Server到底用的是哪个版本和具体信息
-
Redis默认缓冲区大小其实不一定最合适,调整下可能更好用
-
ORA-41005报错导致会话ID缺失,远程指导快速定位修复方法分享