学会这些Kubernetes Pod的小窍门,企业里才算真有竞争力的人了

(根据微信公众号“运维开发故事”的文章《学会这些Kubernetes Pod的小窍门,企业里才算真有竞争力的人了》整理)
在企业里真正玩转Kubernetes,光会基本的创建和删除Pod是远远不够的,那些能让你的应用跑得更稳、更省资源、排查问题更快的Pod小窍门,才是体现你核心竞争力的地方,这些东西,文档上可能不会重点讲,但却是日常工作中一定会遇到的实战经验。
第一,给你的Pod加上“身份证”和“说明书”。 很多人部署Pod,YAML文件里只写个名字和镜像就完事了,这在测试环境可能没问题,但一到生产环境,问题就来了,当你的Pod成百上千的时候,你怎么快速知道哪个Pod是干什么的?出了问题该找哪个团队?
这里的关键就是用好标签(Labels)和注解(Annotations),标签就像是Pod的“身份证”,是用来识别和分组Pod的,你可以给前端业务的Pod打上app: frontend、tier: ui的标签,给后端服务的Pod打上app: backend、tier: api的标签,这样,当你用kubectl get pods -l app=frontend命令时,就能一下子把所有前端Pod都筛出来,一目了然,Service和Deployment这些资源也是通过标签来选择和管理Pod的,标签打得好,整个服务的管理和发现就顺畅了。

注解(Annotations)则更像是Pod的“说明书”,用来记录一些非识别性的、额外的信息,你可以把构建这个Pod镜像的Git提交哈希(Commit Hash)写在注解里,方便出问题时追溯代码版本,或者,记录一下这个Pod最后一次更新的原因,比如kubernetes.io/change-cause: "Deploy hotfix for user login issue",这些信息在排查复杂问题时非常有用,能让你的运维工作有据可查。
第二,让Pod在“闹脾气”和“挂掉”时给你明确的信号。 Pod的生命周期里有两种非常重要的“探头”(Probe):存活探针(Liveness Probe)和就绪探针(Readiness Probe),用好它们,应用的稳定性能提升一个大档次。
存活探针就像是Pod的“心跳检测”,Kubernetes会定期检查你的应用是否还“活着”,如果检查失败,kubelet就会认为这个Pod“死”了,然后把它重启,这个机制能自动修复一些程序卡死但进程还在的尴尬情况,你的应用是一个Web服务,你可以设置一个HTTP GET存活探针,指向/health这个健康检查接口,一旦这个接口连续几次返回错误状态码(比如500),Kubernetes就会自动重启Pod,不需要你半夜爬起来手动操作。

就绪探针则更像是Pod的“上岗检查”,它判断Pod是否已经准备好了,可以开始接收外部的流量,这一点在应用启动时尤其重要,有些应用启动后,可能需要加载大量数据或者初始化连接池,这个过程可能要几十秒,如果没有就绪探针,Pod的状态一变成Running,Service就会立刻把流量导过来,这时候应用还没准备好,就会导致请求失败,通过配置就绪探针,只有当你的应用初始化完成,就绪探针检查通过后,Pod才会被加入到Service的负载均衡池里,从而实现平滑上线,避免上线期间的业务抖动。
第三,管好Pod的“口粮”和“家当”。 这里指的是资源请求(Requests)和资源限制(Limits),不设置资源需求,就像让一群人在一个房间里随便用电,迟早会跳闸。
资源请求(Requests)是Pod向集群声明的“基本保障”,你给一个Pod申请了0.5核CPU和512Mi内存,Kubernetes调度器就会保证把这个Pod安排到一个有足够空闲资源的节点上,这能避免节点因为资源过度使用而导致“邻居”应用互相挤占,影响性能。

资源限制(Limits)是Pod能使用的资源“天花板”,这可以防止某个应用出现Bug导致内存泄漏或者CPU爆满,进而拖垮整个节点上的其他所有Pod,设定了内存限制后,如果Pod使用内存超过限制,它就会被系统强制杀掉,设定了CPU限制,则能保证它不会无休止地抢占CPU。
在实际操作中,Requests和Limits的设置需要结合监控数据不断调整,设置得太保守,会造成资源浪费;设置得太激进,又容易导致应用不稳定,能根据业务特点合理设置这两项,是优化集群资源利用率、降低成本的关键。
第四,做好应用日志的“排水渠”。 在容器里,应用日志默认是输出到标准输出(stdout)和标准错误(stderr)的,这看起来是个小细节,但却是最佳实践,因为Kubernetes的日志收集工具(比如Fluentd、Filebeat)天生就会收集每个容器标准输出的日志,如果你把日志写到容器内的文件里,反而增加了收集和管理的复杂度,Pod一旦被删除,日志文件也就没了,养成习惯,让你的应用日志直接打到标准输出,这样无论Pod飘到哪里,日志都能被统一收集、存储和查询,排查问题效率极高。
第五,让Pod的启动和关闭变得“优雅”。 粗暴地停止一个Pod可能会导致正在处理的请求中断,数据不一致,Kubernetes提供了生命周期钩子(Lifecycle Hooks),让你有机会在Pod被杀死前做一些清理工作,这就是“终止宽限期”(Termination Grace Period),你可以在Pod的配置里定义一个“停止前钩子”(preStop Hook),让它执行一段命令或者发送一个HTTP请求,通知应用“准备下线了”,让应用完成手头的工作再退出,同样,在启动时也可以定义“启动后钩子”(postStart Hook)来执行一些初始化命令,这些小操作能极大地提升应用发布和缩容时的用户体验。
在企业级Kubernetes环境中,竞争力就体现在对这些Pod细节的把握上,从用标签和注解做好管理,到用探针保障稳定性,再到合理分配资源、规范日志输出、实现优雅启停,这些看似不起眼的小窍门串联起来,就能让你部署的应用比别人更可靠、更高效、更易于维护,掌握了这些,你才算是真正从“会用Kubernetes”升级到了“能用Kubernetes解决实际问题”。
本文由黎家于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79031.html
相关文章
-

MySQL报错MY-010143,ER_THE_USER_ABIDES到底啥意思,远程帮忙修复下吧
-

ORA-07271报错搞不定?spwat进程号出错,远程帮你快速修复问题
-

Redis里给值定时不拖延,超时设置马上生效的那些事儿
-
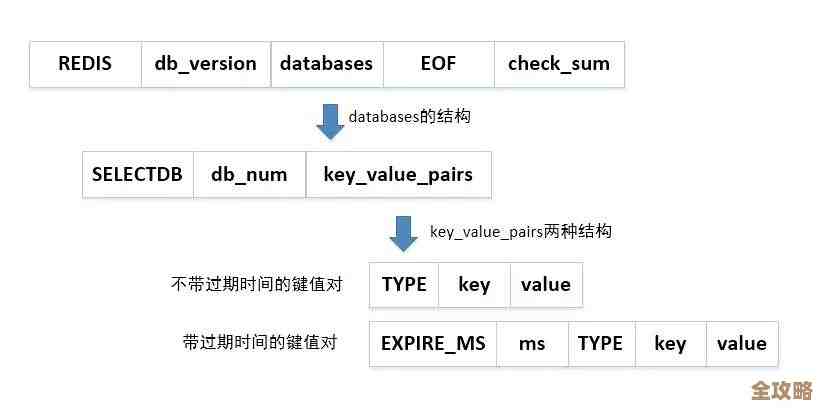
Redis 持久化怎么清理掉,数据存储方式改了之后还得注意啥问题
-
MySQL报错ER_GRP_RPL_FAILOVER_CONF_CHANNEL_DOES_NOT_EXIST,远程故障处理和修复方法分享
-

怎么快速知道你SQL Server到底用的是哪个版本和具体信息
-
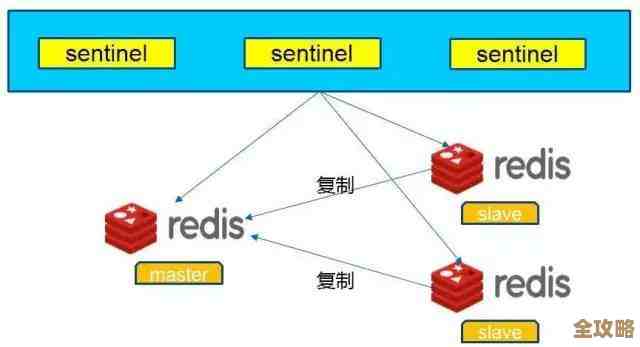
Redis默认缓冲区大小其实不一定最合适,调整下可能更好用
-
ORA-41005报错导致会话ID缺失,远程指导快速定位修复方法分享