MVVM模式里到底怎么搞数据库连接,感觉步骤有点绕但又必须弄明白

你感觉MVVM里搞数据库连接“绕”,这个感觉非常对,因为它确实不是直接了当的,核心原因在于MVVM模式强调“解耦”,而直接操作数据库是典型的“数据操作”,两者之间需要一座设计精良的桥梁,你不是一个人在绕,几乎所有初学者都会在这里卡一下,我们一步步把它捋直。
核心矛盾:ViewModel不应该知道数据库的具体细节
我们必须明确一个MVVM的基本原则:ViewModel的职责是准备和管理View所需要的数据和命令,它不应该关心数据是从哪里来的——是本地数据库、网络请求、还是一个文本文件,一旦ViewModel直接写了SQL语句或者调用了某个数据库框架的具体方法,它就与这个具体的数据库实现“耦合”了,将来如果你想换数据库(比如从SQLite换成Realm),或者增加网络数据源,就得修改所有ViewModel,这是灾难性的。
那个“绕”的步骤,其实就是引入一个中间层来解耦,这个中间层通常被称为Repository(仓库模式)。
“绕”的步骤分解:三层结构
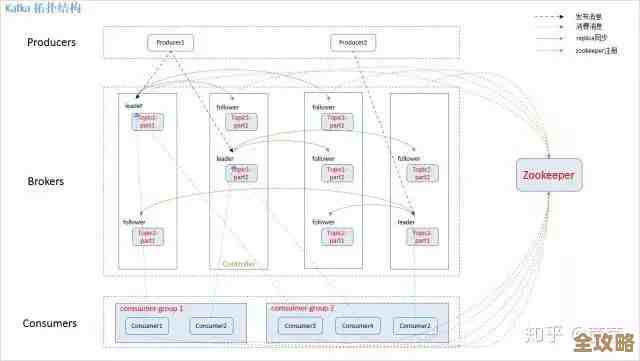
整个流程就变成了:View -> ViewModel -> Repository -> 数据库,我们倒着讲,从最底层开始。
第一层:数据库和数据实体(Model层的一部分) 这里就是你实际操作数据库的地方,你会使用像Room(Android)、Core Data(iOS)或者SQLite.NET等ORM框架,你定义数据表结构,通常就是一个普通的类,叫Entity(实体),比如一个用户实体:
public class UserEntity {
public int Id { get; set; }
public string Name { get; set; }
}然后你创建一个DAO(数据访问对象),里面全是抽象的操作方法,InsertUser(UserEntity user), GetAllUsers(), DeleteUserById(int id),DAO就是一个接口,它定义了“能做什么”,但不关心“谁来做”、“什么时候做”。
第二层:Repository(仓库)- 关键的中间人 这是解开你疑惑的关键,Repository的职责是:
- 数据源调度:决定数据从哪里来,先看缓存有没有,没有再去数据库查,数据库没有再去网络请求,ViewModel完全不用管这些。
- 数据转换:将底层的数据实体(Entity)转换成上层业务需要的“模型”(Model 或 Domain Model),这个模型可能和Entity基本一样,但允许你做一些调整,比如把名字和姓氏拼接成完整姓名,更重要的是,这进一步隔离了数据库变化对上层的影响。
- 提供干净的API:它向ViewModel暴露非常简洁的方法,
Task<List<User>> GetUsersAsync(),ViewModel只需要调用这个简单的方法,而不需要传递复杂的查询条件或处理数据库连接异常。
Repository会持有你第一层创建的DAO接口实例,通过依赖注入的方式传入,这样,Repository具体操作哪个数据库,ViewModel是无感的。
第三层:ViewModel - 真正的指挥家 ViewModel变得很清爽,它只需要做几件事:
- 持有Repository的引用(同样通过依赖注入)。
- 暴露属性给View进行绑定,这些属性通常是可观察的(如
ObservableCollection<T>或StateFlow),这样数据一变,UI自动更新。 - 暴露命令(如
ICommand)来响应用户操作。 - 调用Repository的方法,当用户点击“加载用户”按钮时,ViewModel就执行
await _repository.GetUsersAsync(),然后将返回的结果赋值给自己暴露的那个可观察属性,View就自动显示出用户列表了。
为什么说“绕”但有价值?
你看,为了从数据库取点数据,要经过DAO -> Repository -> ViewModel -> View 这么多步,确实比直接在按钮点击事件里写SQL查询要“绕”得多。
但它的巨大价值在于:
- 可测试性:你想测试ViewModel的业务逻辑(只有VIP用户才能执行某个操作”),你根本不需要一个真实的数据库!你可以创建一个“假的”Repository(Mock Repository),让它返回你预设的测试数据,测试变得极其简单和快速。
- 维护性:数据库逻辑变化(比如表结构改了),你只需要修改Entity和DAO,最多再改一下Repository的数据转换逻辑,ViewModel和View的代码纹丝不动,同样,如果你想加一个缓存层,也只在Repository内部动手术就行了。
- 职责清晰:每一层干什么活都非常明确,符合“单一职责原则”,代码看起来舒服,团队协作也更顺畅。
一个简单的比喻
你可以把整个过程想象成去高级餐厅吃饭:
- 你(View):顾客,只管点菜(触发命令)和吃菜(显示数据)。
- 服务员(ViewModel):理解你的需求,给你菜单(暴露数据),把你点的菜名告诉后厨,然后把做好的菜端给你,他不需要知道菜是怎么做的。
- 厨师长(Repository):接收服务员送来的订单,他决定是直接用冰箱里的食材(本地数据库),还是打电话让供应商送新鲜货(网络请求),他把原始的食材(Entity)加工成美味的菜肴(Model)。
- 后厨小工和冰箱(DAO/数据库):负责最底层的食材存储和初步处理。
你不会想直接跑到后厨的冰箱里自己拿东西吃吧?那样虽然直接,但会一团糟,MVVM里的这个“绕”的流程,就是为了建立一个清晰、高效且易于扩展的“服务流程”。
弄明白MVVM中数据库连接的关键,就是接受并理解 Repository这个中间层的存在和价值,它不是故意把事情复杂化,而是为了长远的简单和灵活,一旦你习惯了这种数据流动的方式,你就会发现它非常自然和强大。

本文由符海莹于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/78738.html