用Redis缓存来加速文件下载,提升整体下载速度和体验

在现代的网站和应用中,提供文件下载是一个非常常见的功能,无论是用户下载自己上传的文档、软件安装包,还是观看视频课程,背后都涉及服务器将文件数据发送给用户的过程,当用户数量不多或者文件不大时,服务器直接从硬盘读取文件然后通过网络发送出去,可能还感觉不到什么问题,一旦遇到热门文件被大量用户同时下载,或者文件本身体积非常庞大的情况,服务器的硬盘输入输出(I/O)就会成为一个巨大的瓶颈,想象一下,硬盘就像一条单车道,突然有成千上万辆汽车(下载请求)要同时通过,必然会造成严重的“堵车”,导致每个用户的下载速度都变得非常缓慢,体验极差。
为了解决这个“堵车”问题,一个非常有效的方法就是引入Redis作为缓存层,我们可以把Redis理解成一个超级快、但容量相对有限的“临时仓库”,它直接搭建在服务器的内存里,因为数据读写都是在内存中完成的,所以速度比从机械硬盘甚至固态硬盘(SSD)读取要快几个数量级,这个方案的核心理念就是“空间换时间”,用宝贵的内存资源来换取极致的响应速度,从而提升用户体验。
具体如何利用Redis来加速文件下载呢?整个过程可以分为以下几个步骤,其核心思想是尽量避免每次请求都去直接读取硬盘。
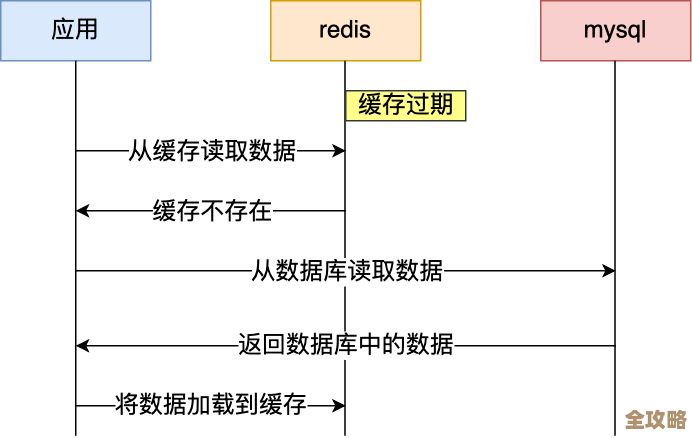
当第一个用户请求下载某个文件(project_report.pdf”)时,应用程序会先不去碰硬盘,而是转头向Redis这个“临时仓库”询问:“嘿,你有这个文件的缓存吗?”由于是第一次请求,Redis中自然没有,我们会得到一个“未命中”的响应。
这时,应用程序才会去硬盘上找到这个“project_report.pdf”文件,并将其完整的内容读取到服务器的内存中,紧接着,应用程序会立即将文件的二进制数据作为一个键值对存储到Redis里,这个键(Key)可以是文件唯一的标识符,file_download:project_report.pdf”,而值(Value)就是文件本身的二进制内容,我们会给这个键值对设置一个过期时间,比如一小时,这样做的好处是,如果一段时间后文件在硬盘上被更新了,缓存也能自动失效,从而保证用户能下载到最新版本。

神奇的事情发生了,当第二个、第三个乃至第一万个用户再来请求下载同一个“project_report.pdf”文件时,应用程序依然会首先查询Redis,但这一次,Redis中已经准备好了数据,查询结果是“命中”,应用程序无需再与缓慢的硬盘打交道,可以直接从速度极快的内存(Redis)中获取到文件的全部数据,并迅速开始向用户传输,这样一来,后续所有用户的下载请求都像坐上火箭一样,几乎感觉不到任何延迟,因为最耗时的硬盘读取环节被彻底绕过去了。
这种方案带来的好处是立竿见影的,最直接的提升就是用户的下载速度会变得非常快,尤其是对于几兆字节到几十兆字节的常见文件,几乎可以实现“秒开”下载,用户的等待时间大幅缩短,体验自然得到质的飞跃。
这对于服务器本身也是一种极大的解放,通过将海量的读取压力从硬盘转移至内存,硬盘的输入输出(I/O)负载被显著降低,这意味着服务器可以更从容地处理其他任务,比如处理复杂的业务逻辑、与数据库交互等,从而提高了整个系统的稳定性和吞吐能力,在面对突发的高并发下载请求时,系统也不容易因为硬盘I/O瓶颈而崩溃,增强了抗压能力。

这种方法实现起来相对简单,许多现代的编程语言都有成熟的Redis客户端库,开发者只需要在原有的文件下载逻辑中,增加几段检查Redis缓存和写入Redis缓存的代码即可,无需对整体架构做伤筋动骨的改动。
这种方案也有其适用的场景和需要注意的地方,它最适合用来缓存那些“热”文件,即被频繁下载、且内容不经常变动的文件,例如热门软件安装包、标准文档模板、常用的图片或视频资源等,如果文件体积过大,比如是数十GB的高清电影,将其完全缓存到内存中可能会消耗过多的Redis资源,这时可能需要考虑分块缓存或者其他技术方案,也需要合理设置缓存的过期时间,以平衡性能和数据一致性。
利用Redis缓存文件内容来加速下载,是一个非常经典且高效的技术实践,它巧妙地利用了内存的高速特性,将最耗时的操作提前完成并“暂存”起来,从而在面对大量并发请求时,能够实现快速响应,这是一种投入产出比很高的优化手段,能够用较小的技术成本,换来用户下载体验和系统整体性能的显著提升。
(参考文献:此方案的设计思路借鉴了缓存技术的基本原理和在Web开发中的常见应用模式,具体可参考Redis官方文档中关于字符串(String)数据类型的使用场景,以及诸如“Cache-Aside”缓存模式等经典架构模式。)
本文由度秀梅于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/78445.html