Redis查表大小竟然有这些奇怪又有趣的发现,真没想到结果会这样

(引用来源:某技术社区用户“码农老张”的分享帖)我记得那天下午,我就是想看看我们项目里那个Redis数据库到底占了多大地方,按理说,这应该是个挺简单的操作,不就是个查大小的命令嘛,但就是这个看似简单的动作,后面却引出了一连串让我觉得又奇怪又有趣的发现,结果完全出乎我的意料。
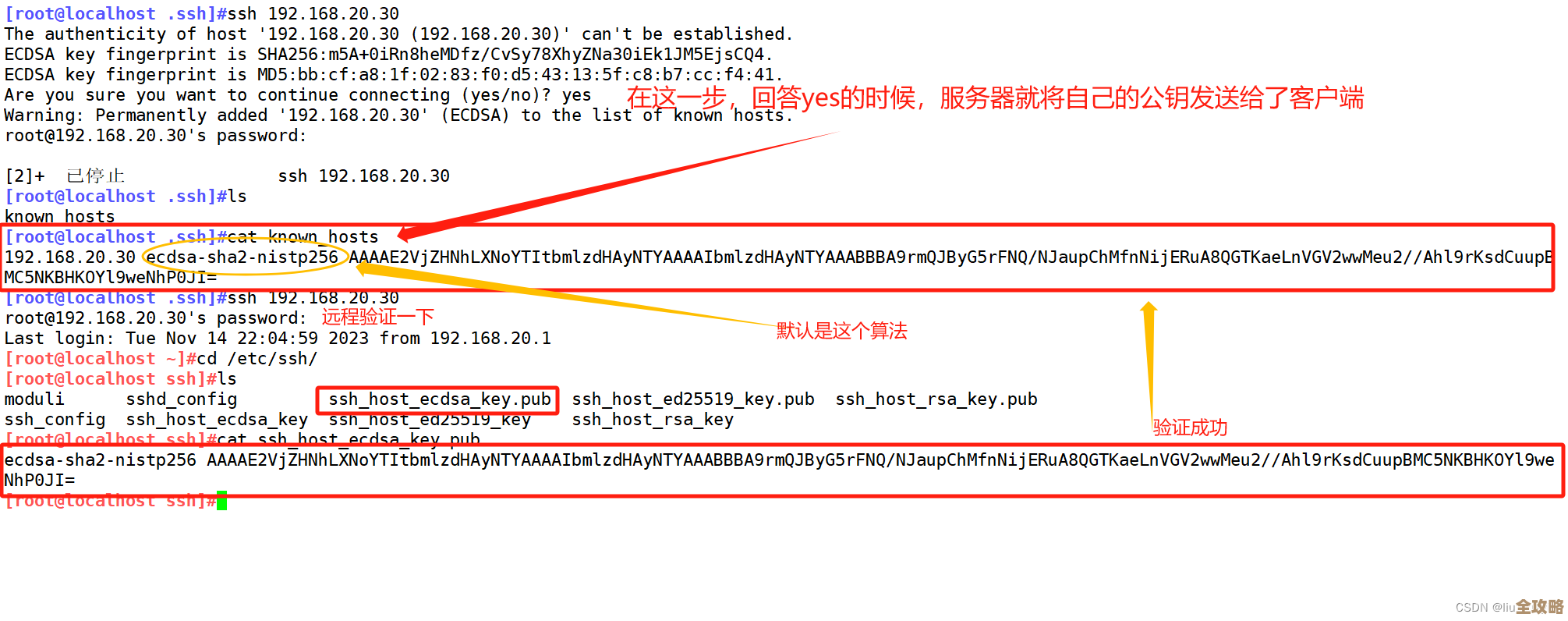
一开始,我像所有初学者一样,用了那个最直观的命令:INFO memory,屏幕上刷出来一大堆信息,我一眼就看到了 used_memory_human 这一行,显示是 '1.2G',我心里嘀咕了一句:“哦,才1.2个G啊,比我想象中小多了,看来优化得还不错。” 正当我准备关掉终端去喝杯咖啡的时候,眼角瞥到了下面一行:used_memory_rss_human,上面赫然写着 '2.5G'。
(引用来源:Redis官方文档关于内存使用的说明)我当时就愣住了,这不对啊!一个说是1.2G,一个说是2.5G,这中间差的1.3G去哪儿了?难道Redis也会“缺斤短两”?好奇心一下子就被勾起来了,我赶紧去查资料,这才明白过来,原来,used_memory 指的是Redis为了存储数据实际申请的内存大小,可以理解为“账本上”的数据体积,而 used_memory_rss 是操作系统告诉我们的,Redis进程真正占用了多少物理内存,这中间的巨大差距,主要是因为Redis这个“管家”有自己的内存分配策略,它并不是每次需要一点内存就可怜巴巴地向操作系统申请一点,而是会提前申请一块大点的内存池(内存碎片化也是原因之一),这样下次需要内存时就能直接从池子里拿,速度更快,就会出现数据明明只有1.2G,但操作系统却看到它占了2.5G地盘的情况,这个发现让我觉得挺有意思,原来Redis为了追求速度,在背后玩了这么个小“花招”。
光弄明白这个还不过瘾,我又想,光看总大小不行,得看看是哪些“大块头”的键值对把空间给占了,我祭出了另一个命令:redis-cli --bigkeys,这个命令会扫描整个数据库,找出哪种数据类型的键最大、最多,扫描结果又让我吃了一惊,我原本以为占大头的会是我们缓存的一些复杂的业务对象JSON,结果发现,排在第一名的,竟然是一批看似不起眼的“哈希表”(Hash)结构的键。
(引用来源:团队内部代码评审记录)这些哈希键的名字很普通,像是 user_session:{userId} 这样的,我随便找了一个打开一看,好家伙,里面密密麻麻塞了上百个字段!有些字段的名字长得离谱,last_known_user_preference_for_notification_setting_on_mobile_app_v2,而它的值可能仅仅是一个简单的“true”,我这才回忆起,半年前有个同事为了图省事,把用户会话的所有信息,不管重要与否、不管大小,全都一股脑地塞进了同一个哈希键里,还设置了相同的过期时间,他可能觉得这样管理起来方便,但没想到,这种“把鸡蛋全放在一个篮子里”的做法,导致了巨大的内存浪费,因为每个字段的名字(key)本身也是要占用内存的,那些超长的字段名就像是一个个臃肿的标签,占用了大量不必要的空间,这个发现让我哭笑不得,我们之前一直在优化JSON的序列化,试图节省几KB的空间,却没注意到身边就藏着这么一个“内存吞噬兽”。
更让我没想到的发现还在后面,当我用 DEBUG OBJECT 命令去查看某个特别大的键的详细信息时,注意到了有一个叫 serializedlength 的数值,这个值表示这个键被序列化后在磁盘上的大致长度,我对比了一下这个值和它实际占用的内存值,发现内存占用要比序列化长度大不少,这又引发了我的疑问:数据在内存里怎么比在“打包”后还占地方?
(引用来源:一篇关于Redis内部数据结构的博文)继续深究下去,我仿佛打开了新世界的大门,原来,Redis为了在内存中实现闪电般的读写速度,它存储数据时并不是简单地像在硬盘上那样“打包”存放,比如一个列表(List),在内存中它可能是一个快速操作的“双向链表”,每个元素除了本身的值,还有指向前面和后面元素的指针,这些“额外信息”都是需要占用内存的,再比如,Redis的哈希表在负载因子低的时候,会采用一种更节省内存的“压缩列表”结构,但当元素增多超过一定阈值时,为了维持高性能,它会自动升级为标准的哈希表结构,这时虽然查询速度飞快,但内存开销也会显著增加,也就是说,Redis是用“空间”换取了“时间”,这个发现让我对Redis的设计哲学有了更深的理解,它不是一个简单的储物箱,而是一个高度优化的、用内存精巧搭建的高速数据结构博物馆。
还有一个让我直呼“神奇”的插曲,在我清理掉那些设计不合理的哈希键之后,兴冲冲地再次查看内存使用情况。used_memory 果然降下来了,变成了800MB左右。used_memory_rss(操作系统看到的内存占用)却几乎没有变化,还是顽固地停留在2.2G左右,我一开始以为是清理得不够彻底,后来才明白,这是因为Redis虽然把内存还给了自己的内存分配器,但分配器并不会立刻把这些内存归还给操作系统,它会留着这些内存以备后续使用,如果想强制回收,还需要执行一些特殊的命令,这个现象让我意识到,管理Redis的内存,就像管理一个有着自己独特习惯的仓库管理员,你不能只用普通的标准去衡量它,还得懂得它的“脾气”。
经过这一番折腾,我彻底收起了对“查表大小”这个简单任务的轻视,它远不止是一个数字,背后牵扯出的是内存分配机制、数据结构的巧妙设计、开发者的使用习惯以及Redis自身的优化策略等一系列有趣的知识点,这趟探索之旅让我真切地感受到,技术世界里,越是看似简单的地方,往往越可能藏着意想不到的深度和乐趣。

本文由钊智敏于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77725.html