用Redis做读写缓存,效率提升其实没那么难,你也能试试看

用Redis做读写缓存,效率提升其实没那么难,你也能试试看
你是不是经常觉得自己的网站或者应用打开速度有点慢?尤其是当很多人同时访问的时候,感觉服务器都快撑不住了,页面转圈圈转个没完,你可能也听说过一些提升速度的技术,缓存”,但一听“Redis”这种专业名词,就觉得那是大公司、高级工程师才能玩转的东西,自己肯定搞不定。
其实啊,这个想法是错的,用Redis来做缓存,核心思想非常简单,就像我们日常生活中用记事本一样自然,我就用最通俗的大白话,跟你讲讲怎么用Redis给你的系统“提提速”,你会发现,这事儿真的没想象中那么难。
Redis是啥?它就是个超级快的“临时记事本”
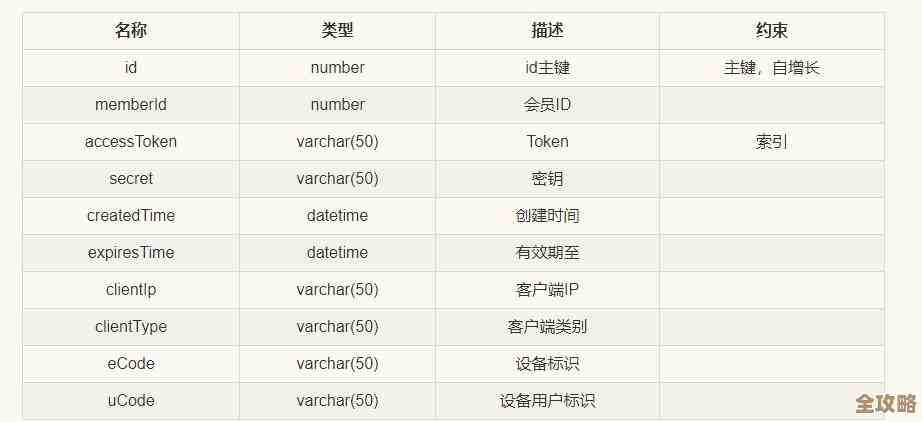
别被Redis这个英文名字吓到,你可以把它想象成一个放在你电脑内存里的、速度超级快的“临时记事本”。(来源:Redis官方介绍将其描述为内存中的数据结构存储)
为什么是“内存”里?因为从内存里读东西,比从硬盘(比如你的电脑C盘)里读东西要快成千上万倍,为什么是“临时”?因为内存一断电,里面的东西就没了,但这恰恰是它适合做缓存的优点,我们本来就是要存一些临时、常用的数据。

那这个“记事本”能记些什么呢?它能记很多种格式的信息:简单的“键值对”(用户名->用户昵称)、列表、集合等等,对我们入门来说,先知道最简单的“键值对”就够了,就像你给一条信息起个名字,然后把它存起来。
缓存是怎么工作的?就像个“贴心小助手”
现在我们来打个比方,看看这个“超级记事本”是怎么帮我们加快速度的。
假设你的应用是一个电商网站,有个页面要展示商品详情,没有缓存的时候,每次有用户点击一个商品,你的程序就要做下面这一连串“辛苦”的工作:
- 接收用户的请求,比如商品ID是123。
- 忙忙碌碌地去庞大的数据库里,翻箱倒柜地查找ID为123的商品信息。
- 从数据库里把商品的名称、价格、图片地址等信息都取出来。
- 把这些信息组装成网页,返回给用户。
这个过程,尤其是第2步“翻箱倒柜查数据库”,是非常耗时的,如果同时有1000个人查1000个不同的商品,数据库压力就非常大,速度自然就慢下来了。

我们请出Redis这个“贴心小助手”(也就是缓存),工作流程就变成了这样:
- 用户请求商品123的详情。
- 程序不是直接去吵醒忙碌的数据库,而是先扭头问身边的“小助手”Redis:“嘿,你记事本上记没记商品123的信息呀?”
- 情况一(小助手有记录):Redis飞快地回答:“有有有!名字是XX,价格是XX,给你!” 程序立刻拿到数据,返回给用户,整个过程极快,因为只是在内存里做了一次简单的查找,数据库完全没参与,这叫缓存命中。
- 情况二(小助手没记录):Redis说:“不好意思,这个我没记。” 这时,程序才不得不自己去数据库里“翻箱倒柜”,取出商品123的完整信息。
- 取出来之后,程序做两件事:一是把数据返回给用户;二是顺手把这份数据写一份到Redis这个“记事本”上,并且告诉Redis:“这个信息你先帮我记着,过10分钟再扔掉(设置过期时间)。”
- 下一个用户再来请求商品123时,程序再问Redis,就能直接拿到答案了,速度飞快。
你看,有了这个“小助手”之后,只有第一个请求某个商品的用户会感觉稍微慢一点(因为要查数据库),后面成千上万个请求同样商品的用户,体验都会是飞快的,这就大大减轻了数据库的压力,整个系统的效率自然就提升了。
你自己动手试试看,几步就能入门
听起来是不是挺简单的?那具体怎么开始呢?你不需要一开始就弄一个非常复杂的系统,可以从最简单的场景入手。
-
安装Redis:这步很简单,去Redis官网根据你的操作系统(Windows、Linux、Mac)下载并安装,或者,如果你用的是云服务器,很多云服务商都提供现成的Redis服务,开箱即用,更省心。

-
选择一个简单的编程语言客户端:Redis本身是个服务,你的程序要通过代码和它“对话”,几乎所有流行的编程语言(比如Java、Python、PHP、Go)都有非常简单的Redis客户端库,以Python为例,你只需要安装一个叫
redis-py的库,几行代码就能连接上Redis。 -
实现一个最简单的缓存逻辑:我们就用上面商品详情的例子。
- 在查询数据库之前,先写一段代码,用商品的ID作为“键”(key),去Redis里查一下。
- 如果查到了(缓存命中),直接使用这个数据。
- 如果没查到(缓存未命中),就去数据库查,然后把结果用同样的商品ID作为“键”存到Redis里,同时记得设置一个过期时间(比如
setex key 600 value,表示600秒后自动删除)。设置过期时间非常重要,这能防止数据在Redis里躺一辈子,当真实数据在数据库里变化了,缓存也能自动失效更新。
-
先从“读缓存”开始:刚开始,你完全可以只给那些“读多写少”的数据加缓存,比如商品信息、文章内容、用户的基本信息等,这些数据不怎么变,但被读取的次数非常多,加缓存的效果立竿见影,至于那些频繁更新的数据,可以稍后再考虑更复杂的策略。
需要注意的几个小坑
世界上没有完美的技术,用Redis缓存也要注意几点,但别怕,都不复杂:
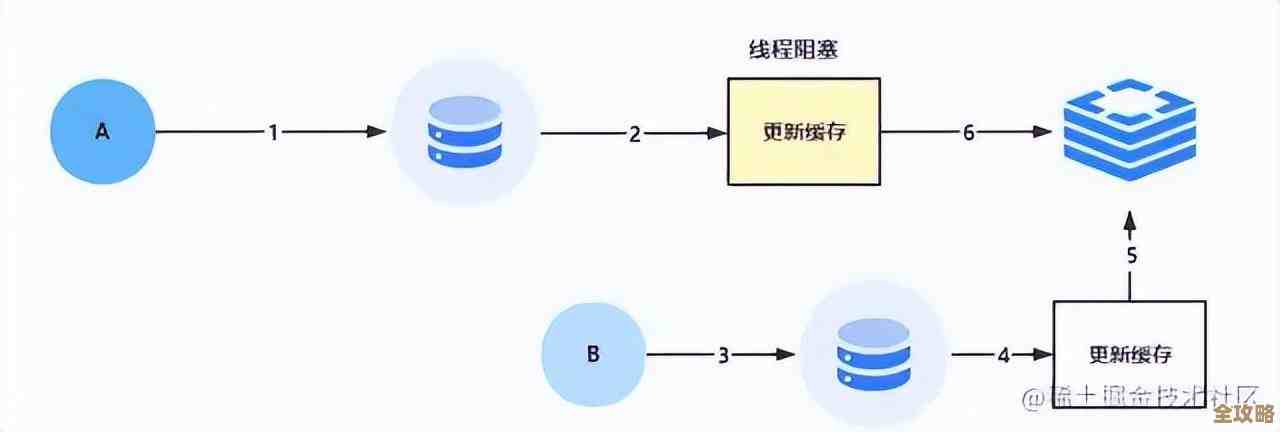
- 数据不一致:因为缓存里的数据是“临时”的,可能数据库里的真实数据已经变了(比如管理员修改了商品价格),但缓存里的还是旧数据,解决方法就是合理设置过期时间,让缓存定期自动失效;或者在更新数据库的时候,顺手把对应的缓存也删掉(下次请求时自然会重新加载最新数据)。
- 缓存穿透:如果有人一直请求一个数据库中根本不存在的数据ID,每次请求都查不到缓存,都会去查数据库,数据库压力还是会很大,解决方法很简单,即使从数据库没查到,也可以在Redis里存一个“空值”并设置短一点的过期时间,短时间内再请求这个不存在的数据,就直接返回空值了。
- 别把缓存当数据库:一定要记住Redis是“临时记事本”,重要数据必须在数据库里有完整的备份,不能因为用了Redis,就只往Redis里存数据。
用Redis提升系统效率,核心就是“用空间换时间”,我们分出一点服务器的内存资源(空间),来换取惊人的响应速度(时间),它并不是什么高深莫测的黑科技,其背后的思想和我们日常生活中用记事本、备忘录来提醒自己,避免重复思考和查询,是完全相通的。
别再犹豫了,找个周末下午,按照我说的简单步骤,在你的个人项目或者测试环境里动手试一试,当你看到加上缓存后,页面加载速度那肉眼可见的提升时,你一定会感叹:“原来这么简单,我早就该用了!”
本文由盘雅霜于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77705.html