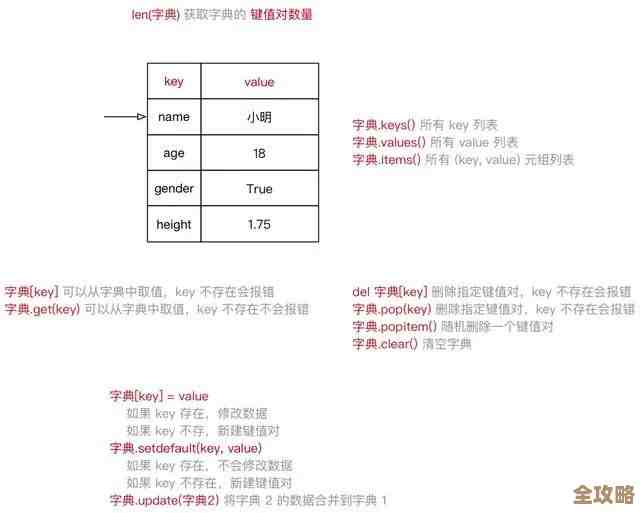
ORA-01555报错怎么破?回滚段太小导致快照旧了,远程帮你修复故障

ORA-01555错误,它的全名是“ORA-01555: snapshot too old: rollback segment number with name \"\" too small”,中文通常翻译为“快照过旧”,这个错误本身不是一个数据损坏的错误,而是一个系统资源配置或应用程序逻辑问题导致的并发性错误,它最常发生在执行长时间查询的过程中。
要理解这个错误,我们可以用一个简单的比喻来说明,想象一下,你正在图书馆里阅读一本非常厚的书(这相当于一个需要长时间运行的查询),在你阅读的过程中,图书馆的管理员(相当于Oracle数据库)为了节省空间,会把一些很久没人看、并且已经被人借阅后归还的书页(相当于已经提交的旧数据)清理掉,放回书架或者存档,假设你读到一个章节,它告诉你:“关于这个问题的详细解释,请参考第50页。”于是你翻回第50页,但如果在你阅读当前章节的这段时间里,管理员恰好认为第50页已经没人需要,把它清理掉了,那么你就找不到那页纸了,这时,你就会遇到一个信息中断的问题,类似于ORA-01555错误。
在Oracle数据库中的具体过程是这样的:
- 查询开始:当一个查询(比如一个复杂的报表查询需要跑几分钟甚至更久)开始时,数据库会为这个查询建立一个“读一致性”的视图,这意味着,无论查询运行多久,它看到的数据都应该是查询开始那个时间点的数据状态,这是为了保证数据在查询期间不会因为其他用户的修改而变得不一致。
- 数据被修改:在查询运行的同时,数据库的其他会话(用户或应用程序)正在不断地修改数据(进行INSERT、UPDATE、DELETE操作),这些修改一旦被提交(COMMIT),新数据就成为当前数据,而旧版本的数据就被保存在一个叫做“回滚段”(或UNDO表空间)的区域里。
- 回滚段的作用:回滚段就像是一个“历史数据档案馆”,当你的长时间查询需要读取一个已经被修改过的数据块时,它不能直接读当前的新数据(因为新数据是查询开始后产生的),它必须去回滚段里找到查询开始时刻的那个旧版本数据,这样才能保证它看到的是一致性的快照。
- 错误的发生:如果系统非常繁忙,回滚段(档案馆)的空间是有限的,当新的数据修改不断产生,旧的撤销信息就会挤占空间,为了给新来的撤销信息腾地方,数据库会覆盖掉那些最早期的、已经不再被任何查询需要的旧撤销数据(就像图书馆管理员清理旧书页)。问题就在于,如果你的长时间查询运行得太久,它所需要的某些旧版本数据可能还未来得及被读取,就已经从回滚段中被覆盖清理掉了,这时,数据库就无法为你的查询提供那个一致性的数据视图了,于是就会抛出ORA-01555错误,告诉你:“你要看的那个历史快照数据已经被覆盖了,我找不到了。”
根据上述原理,解决ORA-01555错误的思路就清晰了,核心就是确保长时间查询在执行期间,所需要的旧版本数据不会被过早地从回滚段中覆盖掉,解决方法可以从数据库系统配置和应用程序优化两方面入手。
数据库系统层面调整(扩大“档案馆”或改善“管理规则”)
- 增大UNDO表空间大小:这是最直接的方法,如果回滚段空间太小,很容易就被填满并开始覆盖旧数据,通过增加UNDO表空间的数据文件大小,相当于给档案馆扩建,能保存更长时间的历史数据,从而降低报错概率,参考Oracle官方文档中的存储管理部分,可以通过
ALTER DATABASE命令来增加数据文件。 - 调整UNDO_RETENTION参数:这个参数告诉数据库:提交后的旧数据(撤销信息)至少要在回滚段中保留多长时间(单位是秒),默认值可能比较小,将其设置为一个更大的值(设置为比你的最长查询时间再长一些的数值,如1800秒或3600秒),可以指示数据库尽量长时间保留这些数据,避免被过早覆盖,命令类似:
ALTER SYSTEM SET UNDO_RETENTION=1800 SCOPE=BOTH;,但需要注意的是,这只是个“目标”值,如果回滚段空间不足,即使未达到保留时间,数据仍然可能被覆盖。 - 启用UNDO表空间的RETENTION GUARANTEE:这是一个更强有力的保证,在UNDO表空间空间充足的情况下,即使设置了
UNDO_RETENTION,为了给新事务腾空间,Oracle可能还是会覆盖那些未到保留时间的数据,如果对某个特别重要的数据库(如数据仓库),可以为UNDO表空间设置RETENTION GUARANTEE(保留担保),这样,数据库会保证所有未过保留期的撤销数据绝对不被覆盖,宁可让新的事务因空间不足而失败,也要确保现有查询不出现ORA-01555,这是一个重要的权衡决策,需要谨慎使用,可以通过ALTER TABLESPACE undotbs1 RETENTION GUARANTEE;来设置。
应用程序和SQL语句优化(减少“阅读时间”和“打扰”)
- 优化长时间查询:这是从根本上解决问题的方法,检查那个跑出错误的SQL语句,看是否能进行优化,缩短其执行时间,查询跑得越快,需要“占用”历史数据的时间就越短,就越不容易遇到数据被覆盖的情况,优化手段包括:
- 添加合适的索引,避免全表扫描。
- 重写SQL,避免复杂的笛卡尔积和低效的连接方式。
- 减少一次性处理的数据量,考虑分批次处理。
- 避免在查询高峰期运行大量批处理任务:批处理任务(如大量数据更新)会产生巨量的撤销数据,迅速填满回滚段并冲刷掉旧数据,尽量将这类任务安排在业务低峰期执行,减少对并发查询的干扰。
- 提交频繁的事务:在应用程序设计中,如果有一段逻辑需要更新很多数据,不要在一个大事务中完成,而是分成若干个小事务并及时提交,这样可以及时释放回滚段的空间,避免单个事务占用过多撤销资源。
远程帮你修复故障”这一点,通常的流程是:作为DBA(数据库管理员),在接到开发人员报告ORA-01555错误后,会通过远程连接工具登录到数据库服务器,首先会查询当前UNDO表空间的使用情况、UNDO_RETENTION参数设置,并分析导致错误的SQL语句的执行时间,会根据实际情况,优先尝试优化SQL语句,如果SQL已经无法优化,则会采取调整数据库参数(如增大UNDO表空间、调整UNDO_RETENTION)的措施,所有这些操作都可以在远程通过SQL*Plus、SQL Developer等工具完成,在极少数对数据一致性要求极高的场景下,才会考虑使用RETENTION GUARANTEE选项。
解决ORA-01555错误是一个综合性的工作,需要DBA和开发人员协作,从“给历史数据留足空间和时间”和“让查询跑得更快”两个方向共同努力。

本文由寇乐童于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77688.html