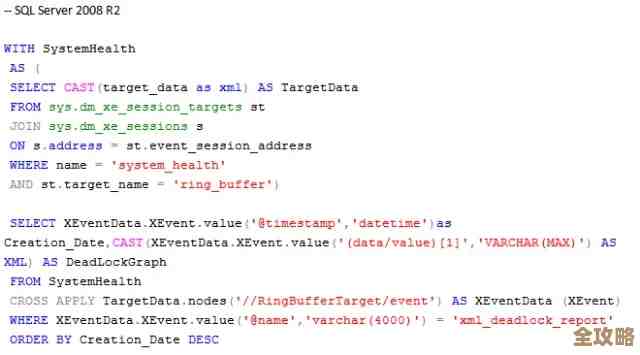
Redis查询要快点,找个代理方案试试看,别总自己瞎查了

“Redis查询要快点,找个代理方案试试看,别总自己瞎查了”这句话,听起来像是一位资深技术同事对另一位总在埋头苦干、但方法可能不太对头的伙伴的善意提醒,话糙理不糙,它点出了一个在技术团队里挺常见的现象:当系统遇到性能瓶颈,尤其是像Redis这种关键缓存层变慢时,开发者第一反应往往是深入Redis内部,去分析慢查询、优化数据结构、调整配置参数,甚至去啃源码,这些努力当然有价值,但有时候,问题可能并不出在Redis本身,或者说,有更直接、更省力的解决思路——比如引入一个“代理”。
这个“代理”指的是什么呢?在Redis的生态里,最常被提及的、能显著提升查询效率的代理方案,就是Twemproxy和Redis Cluster的官方集群方案,以及后来出现的Codis、Envoy Proxy with Redis support等,根据网上很多技术博客和社区讨论(比如一些开发者会在知乎、CSDN、开源中国等平台分享经验),Twemproxy(现在更常被称为nutcracker)和Redis Cluster是两种最经典、讨论最多的路子,咱们就主要聊聊这两种思路,为啥它们能让你“别总自己瞎查了”。
第一种路子:用Twemproxy这样的独立代理
Twemproxy是Twitter开源的一个轻量级代理,它的核心工作很简单,就是挡在你的应用程序和多个Redis服务器中间,你的应用不再直接连接后端的多个Redis实例,而是统一连到Twemproxy上,Twemproxy帮你把数据请求按照一定的规则(比如一致性哈希)转发到正确的Redis实例上。
它为啥能“快点”呢?主要体现在几个方面:
-
连接池管理:这是个大头,想象一下,如果你的应用有几百个服务实例,每个实例都直接连接Redis,Redis服务器可能得维护数万个连接,光是管理这些连接就够它喝一壶的了,Twemproxy充当了一个“连接汇聚点”,应用只需要和Twemproxy建立相对较少的连接,Twemproxy自己再用一个连接池去和后端Redis通信,这就大大减轻了Redis服务器在连接管理上的开销,让它能更专注于处理真正的数据请求,很多运维工程师在博客里都提到,这个特性对于稳定性和性能提升非常明显。
-
自动分片:当你的数据量单台Redis根本存不下时,就得做分片,如果让应用自己操心数据该存到哪台Redis、该从哪台读,代码会变得非常复杂,而且容易出错,Twemproxy帮你透明地做了这件事,应用就像操作一个巨大的Redis一样,Twemproxy在背后默默地把数据分散到不同的服务器上,这样,你就不用“瞎查”如何在自己的业务代码里实现复杂的分片逻辑了,省心省力。
-
协议兼容:Twemproxy完全理解Redis的协议,应用不需要做任何修改,就像用普通Redis一样用它,迁移成本很低。
Twemproxy也不是万能的,根据一些早期的经验分享,它有个明显的短板:它本身是个单点,虽然你可以部署多个Twemproxy实例让应用去连,但它本身不支持故障自动转移,如果后端某个Redis实例挂了,Twemproxy可能还会傻傻地往上面发请求,导致部分查询失败,这就需要额外的监控和运维手段来保证高可用。

第二种路子:直接用Redis自带的集群模式
Redis从3.0版本开始,官方就推出了Redis Cluster,这其实可以看作是一个“内置了代理逻辑”的分布式方案,它没有像Twemproxy那样一个独立的代理服务器,而是通过Redis实例之间互相通信、协作,共同组成一个集群。
Redis Cluster怎么让你“快点”别瞎查”呢?
-
数据分片内置化:分片的逻辑直接内嵌在Redis服务器端,数据被自动分布到不同的“槽”里,每个Redis实例负责一部分槽,客户端(比如Java的Jedis、Python的redis-py等主流客户端库)需要支持集群模式,它能从集群中获取一份“槽位映射表”,当你要查询一个key时,支持集群的客户端会自己先算出这个key属于哪个槽,然后直接连接负责这个槽的Redis实例,这相当于把代理的部分逻辑挪到了客户端,减少了中间跳转,理论上延迟会更低,很多性能测试报告都显示,在网络状况良好时,Redis Cluster的直连模式延迟表现优异。
-
高可用原生支持:这是Redis Cluster比Twemproxy强的地方,它内部通过主从复制来实现故障转移,每个分片都有一个主节点和若干个从节点,主节点挂了,从节点会自动选举出新的主节点顶上去,对于应用来说,整个过程几乎是透明的(客户端需要能正确处理重定向),这意味着你不需要额外搭建一套Sentinel之类的监控系统,也不用太担心单点故障问题,这帮你省去了很多自己“瞎查”如何搭建高可用架构的麻烦。

-
官方维护,生态完善:作为官方方案,它与Redis新特性的同步最好,社区支持也最有力,你不用太担心项目后续无人维护的问题。
Redis Cluster也有它的“脾气”,根据不少开发者的踩坑记录,它对多key操作有限制(要求所有key必须在同一个槽位),对事务的支持也有限制,迁移数据时也可能比通过代理方案更复杂一些,选择它的前提是你的业务场景要能适应它的这些规则。
总结一下
“找个代理方案试试看”这个建议,精髓在于“换个思路”,当直接优化Redis本身遇到瓶颈时,把目光从单机性能扩展到架构层面,无论是用Twemproxy这样的外部代理,还是采用Redis Cluster这种内置集群,核心思想都是:通过架构的调整,将压力分散、将连接管理优化、让数据分布更合理,从而在整体上获得性能提升和高可用性。
Twemproxy更像一个老练的“管家”,帮你打理好一切杂事(连接、分片),让你(应用)专心业务,但管家自己可能需要你多照顾(解决单点问题),Redis Cluster则像一个自组织的“团队”,每个成员(Redis实例)都知道自己该干什么,团队有自己的一套协作和容错机制,但你需要遵守团队的规矩(比如key的分布规则)。
下次再觉得Redis查询慢,别光顾着埋头查慢日志、调redis.conf了,抬起头想想,是不是数据量太大了?连接数是不是爆了?是不是该用个“代理”方案,把架构升级一下了?这可能比你在代码和配置里抠那几毫秒的优化,来得更根本、更有效,这大概就是那句话背后的智慧所在。
本文由盘雅霜于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77645.html