JAVA数据库优化那些事儿,技巧和实操经验聊聊

说到Java程序慢,十有八九问题出在数据库身上,数据量小的时候怎么跑都顺溜,一旦数据多了,用户也多了,程序就开始卡顿、超时,让人头疼,今天聊的不是那些高深莫测的理论,就是一些在实际项目中摸爬滚打总结出来的经验和技巧。
第一件事,也是最根本的事:写好SQL语句。
很多人觉得优化就是加缓存、加分库分表,但其实八成以上的性能问题,一条烂SQL就能搞出来,怎么算写好呢?
务必用上索引,这就像查字典,没有目录你得一页一页翻,有了拼音或部首目录,一下就能定位到大概位置,数据库索引也是这个道理,但是索引不是乱建的,经常用在WHERE条件、ORDER BY排序、JOIN连接上的字段,才需要考虑建索引,比如你经常按用户ID查订单,那就在订单表的用户ID字段上建个索引,效果立竿见影。
*避免`SELECT **,很多人图省事,直接写SELECT ,把整张表的所有字段都捞出来,但很多时候,你真正需要的可能就两三个字段。SELECT 会导致数据库读取大量无用数据,网络传输的负担也重,Java程序解析这些数据也更耗时,需要什么字段,就明确写出来,比如SELECT id, name, status`。

小心联表查询,特别是多表关联,联表查询很方便,但一旦表的数据量大了,联表查询的性能会急剧下降,拆成多次简单的查询,用Java程序在内存里做组合,反而比一条复杂的联表SQL更快,这需要根据实际情况权衡,联表查询时,一定要确保关联的字段上有索引,否则就是灾难。
还有,注意模糊查询的写法。LIKE '%关键字%'这种前后都有百分号的查询,是用不到索引的,会导致全表扫描,如果业务允许,尽量写成LIKE '关键字%',这样还是可以用到索引的。
第二件事,在Java代码层面下功夫。
光SQL写得好还不够,怎么执行SQL也很关键。

使用预编译语句(PreparedStatement),这不仅是防止SQL注入的安全基石,也是性能优化的关键,数据库会对预编译的SQL模板进行解析和优化,下次再执行只是参数不同时,就可以省去解析开销,直接执行,如果频繁执行一条SQL,用PreparedStatement能明显提升效率。
搞个数据库连接池,像HikariCP、Druid这些都是非常优秀的连接池,创建数据库连接是一个很耗资源的操作,连接池的作用就是预先建立好一批连接,程序用的时候直接从池子里拿,用完了还回去,避免了频繁创建和销毁连接的开销,这在高并发场景下对性能的提升是巨大的。
控制事务的范围,要及时提交,事务开启后,数据库会持有锁等资源,如果事务范围太大,执行时间过长,会导致资源被长时间占用,影响其他操作,要在完成业务操作后尽快提交事务,根据业务场景选择合适的事务隔离级别,级别越高,并发性能一般越差。
第三件事,考虑架构层面的优化。

当单表数据量真的大到千万级别甚至更多时,上面的技巧可能就不太够用了,得动大手术。
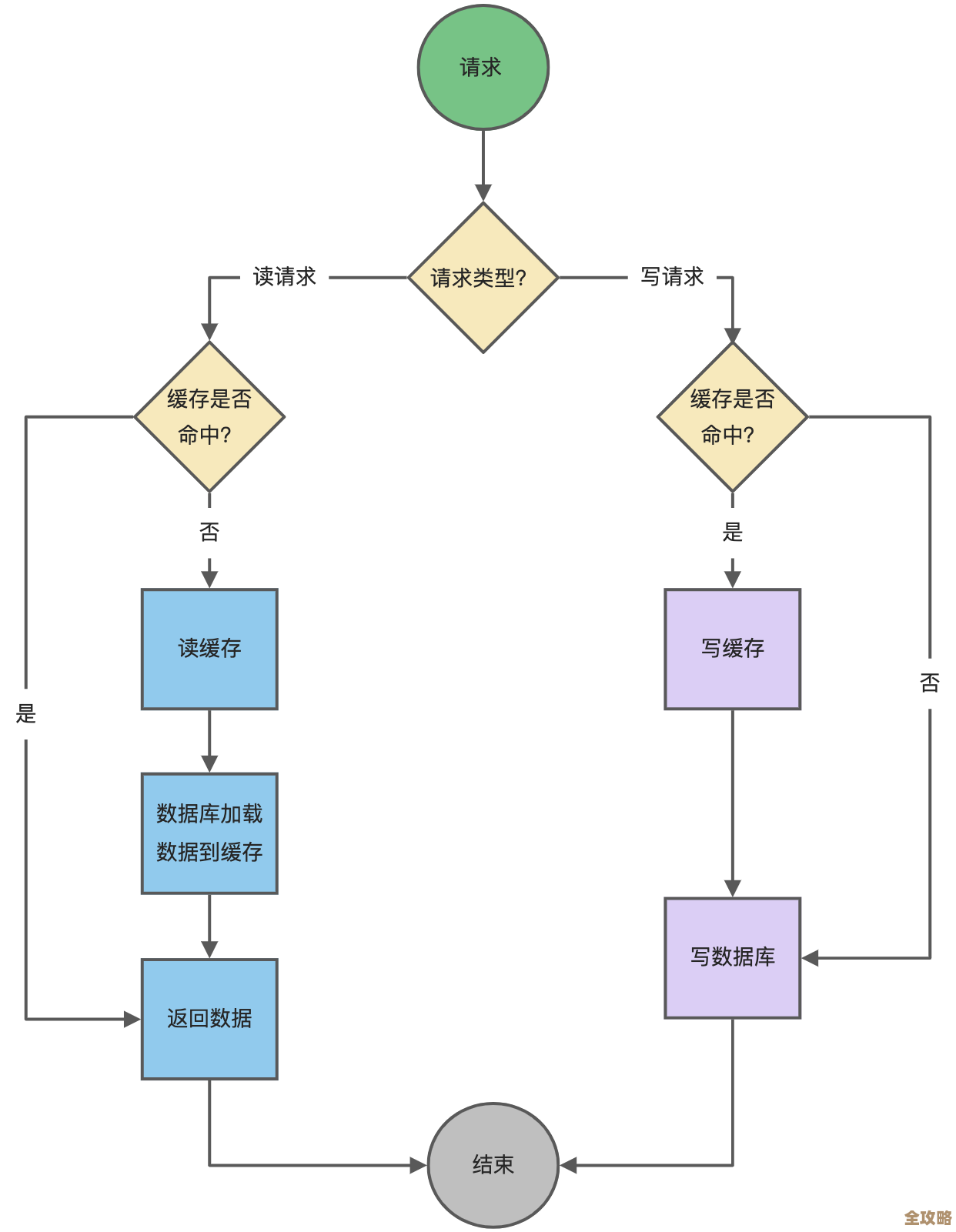
引入缓存,这是最有效的办法之一,把经常读取但又很少变动的数据,比如商品分类、用户基本信息、热点文章等,放到Redis或Memcached这样的缓存里,Java程序读数据时,先查缓存,缓存没有再查数据库,并回写到缓存,这样绝大部分读请求都打不到数据库上,数据库压力骤减,但要注意缓存和数据库的数据一致性问题。
读写分离,如果读多写少,可以考虑搭建主从复制集群,主库负责写,多个从库负责读,Java程序在写入时操作主库,读取时根据策略访问不同的从库,把读压力分摊出去。
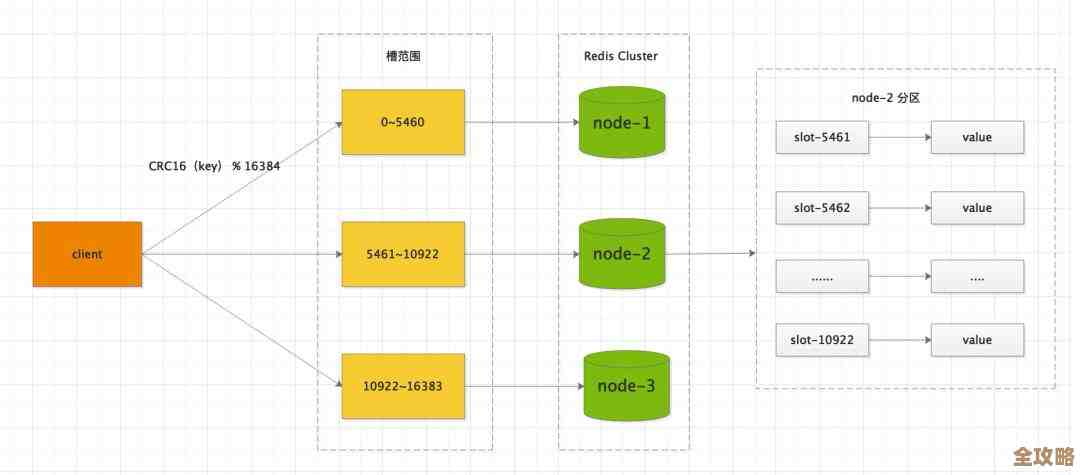
终极手段:分库分表,当单库单表实在撑不住时,就只能拆了,可以按业务模块分库(比如订单库、用户库),也可以按某种规则把一张大表的数据拆分到多个物理表里(比如按用户ID取模分表),但这属于重量级方案,会带来跨库事务、跨表查询等复杂问题,技术复杂度和成本都很高,不到万不得已不要用。
也是最重要的一点:别瞎优化。
优化要有依据,不能凭感觉,要善用工具,比如数据库自带的慢查询日志功能,把执行时间长的SQL都记录下来,然后针对这些“慢SQL”进行重点分析和优化,可以用EXPLAIN命令查看SQL的执行计划,看看它有没有用上索引,是不是全表扫描了。
数据库优化是一个持续的过程,需要从最简单的SQL语句编写习惯做起,逐步深入到架构层面,先找到瓶颈所在,再对症下药,才能事半功倍。 参考了常见的Java开发实践、数据库优化指南以及如《阿里巴巴Java开发手册》等社区规范中的普遍性建议)
本文由颜泰平于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77517.html