Redis集群怎么搭建啊,有哪些方式能用,简单说说吧

(主要参考Redis官方文档和一些常见的运维实践)
你想搭建Redis集群,说白了就是觉得一个Redis实例不够用了,可能是怕它万一坏了整个服务就停了,也可能是数据太多一个机器存不下了,或者读写请求太多一个实例忙不过来,搭建集群就是为了解决这些问题,让几个Redis实例一起干活,分担压力,提高可靠性。
有哪些方式能用呢?
其实有好几种路子,但咱们可以把它们归为两大类:官方的办法和第三方工具的办法,它们各有各的适用场景和优缺点。
官方的办法:Redis Cluster
这是Redis官方自己推出的集群方案,也是最“正宗”的一种,它设计出来就是为了解决上面说的所有问题:高可用、大数据量、高并发。
它是怎么干的? 它用的是“分片”(Sharding)加“主从复制”(Replication)的组合拳。
-
分片(数据分家): 想象一下,你有一个超大的柜子,有很多抽屉,与其把所有的东西都塞进一个抽屉,不如把东西分门别类,放到不同的抽屉里,Redis Cluster也是这个道理,它会把所有的数据分成16384个“槽位”(slot),你可以理解为16384个小抽屉,集群里的每个主节点(Master)负责管理其中一部分抽屉,节点A管0-5000号抽屉,节点B管5001-10000号抽屉,节点C管10001-16383号抽屉,当你存一个数据时,Redis会根据key的名字算一个值,决定它应该放进哪个抽屉,然后就知道该去找哪个节点了,这样,数据就被分摊到了不同的机器上。

-
主从复制(找个备胎): 光分片还不够,万一某个主节点宕机了,它管的那些抽屉不就访问不了了吗?Redis Cluster要求每个主节点至少有一个从节点(Slave),从节点就像主节点的“备胎”或者“跟班”,实时同步主节点的数据,当主节点挂掉时,集群会自动检测到,然后从它的从节点中选举出一个新的主节点来顶替,继续为客户端服务,这个过程是自动的,所以服务基本不会中断。
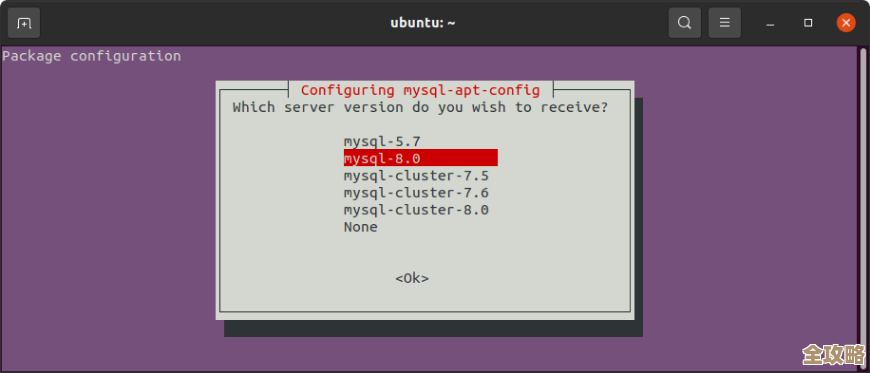
搭建起来麻烦吗? 官方的Redis Cluster需要至少三个主节点才能保证集群的健壮性,为了高可用,每个主节点至少配一个从节点,所以最少需要6个Redis实例,你可以把这6个实例放在3台、4台或者6台物理机器上,看你的资源情况。
搭建过程大概分几步:先把这6个Redis实例都以集群模式启动起来(配置文件中设置 cluster-enabled yes);然后使用Redis自带的命令行工具 redis-cli,执行一条命令,把这些实例串联起来,告诉它们谁是谁的主,谁是谁的从,并分配好槽位,现在也有更简单的命令,可以自动帮你分配槽位和主从关系。
优点: 官方支持,功能完整,无需额外组件,能自动进行故障转移和数据分片。 缺点: 客户端需要支持集群协议(现在大多数语言的客户端都支持了),架构相对复杂一些,管理和维护需要学习成本,它不支持同时操作多个key的命令(除非这些key在同一个节点上),这是它的一个限制。

第三方工具的办法
在Redis Cluster成熟之前,很多人都是用第三方工具来搭建集群的,现在也有一些场景下会用到,主要有两种思路:
-
代理模式(Proxy) 这种模式很好理解,你在多个独立的Redis实例前面,放一个“代理”服务器,你的应用程序不再直接连接Redis实例,而是连接这个代理,你告诉代理你要存什么数据,代理根据预设的规则(比如也是计算key的哈希值),帮你把请求转发到后面正确的Redis实例上,对于你的程序来说,它只觉得在跟一个Redis打交道,非常简单。 代表工具: Twemproxy(也叫nutcracker),Codis(豌豆荚开源的,功能更强大一些)。 优点: 对客户端透明,客户端不需要做任何修改,像用单机Redis一样用集群。 缺点: 多了一层代理,性能上会有一些损耗,而且代理本身可能成为单点故障(需要做代理的高可用)。
-
客户端分片模式 这种方式把“分片”这个麻烦事交给了客户端来做,你需要使用一个支持分片的Redis客户端库,这个客户端库知道所有Redis节点的地址和分片规则,当你的程序要读写数据时,客户端库自己会计算key应该落到哪个节点,然后直接和对应的节点通信。 优点: 没有代理层,性能较好。 缺点: 严重依赖客户端的实现,不同语言的客户端可能不一样,如果集群节点有变化(比如增加或减少节点),需要客户端支持动态扩容,否则会比较麻烦,扩容、缩容通常没有Redis Cluster那么自动化。
- 如果你想用Redis最新的、功能最全的集群方案,不怕稍微复杂一点的配置,并且能接受它对多key操作的限制,那么Redis Cluster是首选。
- 如果你的应用场景很简单,或者你的客户端语言没有好的Cluster支持,又或者你只是想快速搭建一个分片的缓存层,那么可以考虑用代理模式,比如Twemproxy。
- 客户端分片现在用得相对少了,因为Redis Cluster已经很成熟,但在一些老系统或特定环境下可能还会见到。
具体选哪个,就看你的实际需求、技术储备和运维能力了,对于新项目,直接从官方的Redis Cluster开始会是比较稳妥的选择。
本文由盘雅霜于2026-01-08发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/76686.html