用Redis难免遇坑,别说我没提醒你,这些坑真不少也挺折腾

说起用Redis,那可真是让人又爱又恨,这东西快是真快,用起来也感觉挺爽,但你要是觉得随便部署一个就能高枕无忧,那可就大错特错了,我见过太多团队兴冲冲地上了Redis,结果被各种意想不到的“坑”折腾得够呛,今天就直接把这些常见的坑摆出来,都是前人踩过的雷,你可得留神了。

第一个大坑,内存不足直接崩盘。 这是最要命的一个,很多人把Redis当个万能缓存,数据只管往里塞,心里可能还想着:“反正内存那么大,怕啥?” 结果呢,数据量不知不觉就上来了,直到某一天,运维突然收到报警,服务大面积不可用,一查,Redis宕机了,为啥?内存爆了,Redis默认的配置是,当内存用满时,它会直接拒绝新的写入请求,或者更狠的,直接把自己给关掉了(crash),这可不是闹着玩的,你的应用可能会因为缓存雪崩,导致数据库压力激增,整个系统都可能跟着瘫痪,你从一开始就得对数据量有个预估,设置好内存上限(maxmemory),并且选择一个合适的淘汰策略(比如LRU,淘汰最近最少使用的键),让旧数据自动被删掉,给新数据腾地方,千万别等到火烧眉毛了才想起来管理内存。
第二个坑,持久化没弄好,数据说没就没。 Redis虽然快,但它主要是把数据放在内存里的,万一服务器突然断电或者进程崩溃,你内存里的所有数据可就全丢了,为了解决这个问题,Redis提供了两种持久化方式:RDB和AOF,但这里面的坑也不少,你要是只用RDB,它相当于定期给数据拍个快照,如果两次快照之间服务器挂了,那这段时间的数据就找不回来了,你要是用AOF,它会把每个写命令都记下来,数据更安全,但AOF文件会越来越大,重启恢复的时候慢得能让你怀疑人生,更麻烦的是,很多人压根就没仔细配置持久化,用的都是默认值,结果就是数据丢了都不知道怎么丢的,你得根据业务对数据安全性的要求,做好权衡,可以两者结合使用,同时设置合理的RDB快照频率和AOF重写策略。

第三个坑,毫无防备的缓存穿透。 这个听起来就有点吓人,什么意思呢?就是有人(可能是恶意攻击,也可能是正常业务)频繁请求一个根本不存在的数据,请求一个不存在的用户ID,这个请求每次都会穿过Redis缓存,直接打到后端的数据库上,如果这种请求量非常大,数据库可就压力山大了,很容易就被拖垮,解决的办法其实也不难,对于这种明确不存在的数据,你也可以在Redis里缓存一个空值,并设置一个很短的过期时间,这样下次再有同样的请求过来,Redis就能直接返回空值,保护了数据库,或者,在业务层面先做一层校验,过滤掉一些明显非法的请求。
第四个坑,更隐蔽的缓存雪崩。 这个和穿透不一样,雪崩指的是,Redis中大量的缓存在同一时间集体失效了,你有一批缓存键都设置了相同的过期时间,比如都是凌晨2点过期,那么到了2点,这批缓存瞬间全部失效,所有请求一下子全都涌向数据库,数据库根本扛不住这么大的瞬时压力,结果就是又一个连锁故障,避免雪崩的关键在于,让缓存的失效时间变得均匀一些,可以在设置过期时间时,不要都用固定的10分钟,而是用一个基础时间加上一个随机的偏移量,10分钟 + 随机0-5分钟”,这样就能错开失效的高峰。
第五个坑,网络延迟和慢查询带来的性能陷阱。 你以为Redis快就万事大吉了?如果你的应用服务器和Redis服务器之间的网络状况不好,延迟很高,那么再快的Redis也发挥不出优势,一次读写可能要花几十毫秒,这在高并发场景下是不可接受的,Redis是单线程处理命令的,这意味着它非常怕“慢查询”,如果你不小心执行了一个复杂度是O(N)的命令,比如在没有索引的大的集合上做查询,或者用了KEYS *这种命令(生产环境绝对禁用!),这个慢查询就会阻塞住后续所有的命令,整个Redis的服务就跟卡住了一样,务必监控慢查询日志,避免使用那些可能拖慢性能的命令。
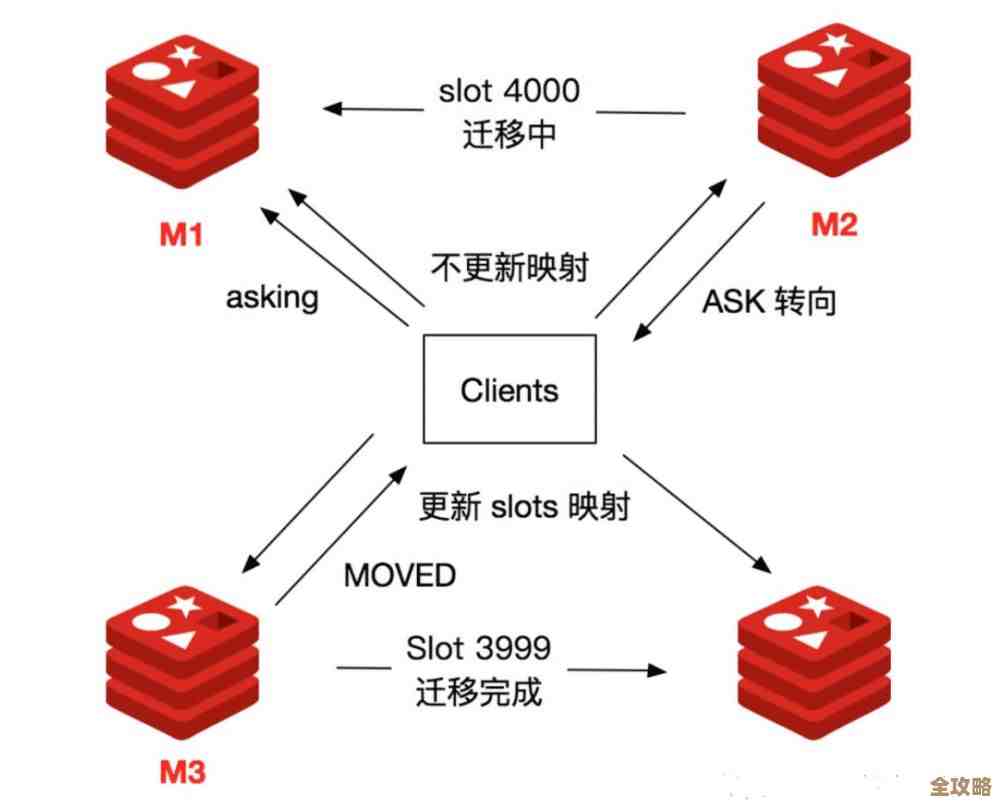
第六个坑,主从复制和集群的运维复杂度。 当单机Redis撑不住的时候,你就要考虑搭建主从复制或者集群了,但这又引入了新的复杂度,主从复制有延迟,你刚在主库上写完,可能立马去从库读,会读不到最新数据(这就是脏读),集群模式虽然能扩展,但涉及到数据分片,key的分布规则、节点的扩缩容都是麻烦事,搞不好就会丢数据或者服务中断,这些高级功能用好了是利器,用不好就是给自己挖坑。
Redis确实是个好东西,但它绝不是个“开箱即用”、零维护的玩具,上面这些坑,从内存管理、数据持久化,到缓存策略、性能调优,再到集群运维,每一个都可能让你栽跟头,在用之前,一定要把这些潜在的问题都想清楚,做好监控和预案,不然等出了问题再补救,那可就太折腾了。

本文由革姣丽于2026-01-08发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/76672.html