用Redis做分页,速度快了但细节还得注意点儿

基于常见的Redis使用经验和开发者社区讨论中的要点提炼)
直接用Redis搞分页,这事儿听起来挺美,毕竟它速度快嘛,但真用起来,你会发现光快还不够,好些细节要是没处理好,分分钟掉坑里,这就像你买了辆跑车,发动机是猛,但要是轮胎没装好或者刹车不灵,上路照样得出事儿。
第一点,数据变了怎么办?这是最头疼的。 你可能会把一堆数据,比如文章ID列表或者用户信息,预先按顺序塞进一个Redis的List或者Sorted Set里,分页的时候,直接用LRANGE或者ZRANGE命令一截取,确实比去数据库里LIMIT快多了,但你想过没有,万一在你分页展示的这段时间里,后台有人新增了一篇文章,或者删掉了一条评论,你缓存里的这个列表不就过时了吗?显示给用户的就是错误的信息,比如用户在第一页看到一篇文章,翻到第二页再翻回第一页,发现那篇文章不见了(因为被删了),这体验就很差,或者新文章已经发表了,但在列表里迟迟看不到。
你得想好数据的更新策略,比较粗暴的办法是,一旦有数据增删改,就直接把对应的那个Redis列表整个删掉(删除这个key),下次请求时再重新从数据库加载生成,但这招在数据更新很频繁的时候,缓存基本就废了,反而增加了数据库压力,另一个办法是,如果顺序要求不那么严格,可以把新内容直接追加到List头部(用LPUSH),这样最新内容总能先看到,但分页顺序可能就会变,如果用Sorted Set,可以通过分数(score)来排序,更新时调整对应成员的分数,你得根据业务对“实时性”和“一致性”的要求,选个合适的更新法子,没有一劳永逸的。
第二点,用List还是用Sorted Set?这得看你怎么排序。 List的好处是简单,按插入顺序排,用LRANGE按索引取数据,非常直接,但如果你需要按时间倒序、按热度分数之类的来分页,List就有点力不从心了,总不能每次分页前都先重新排序整个List吧,那还不如直接用数据库。
这时候Sorted Set就派上用场了,你可以把排序依据(比如发布时间戳、点赞数)作为分数(score),把数据ID作为成员(member)存进去,分页时用ZREVRANGE(如果要倒序)就能按分数高低漂亮地把数据取出来,但要注意,Sorted Set占的内存通常比List大,因为它要存额外的分数信息,如果排序字段本身会频繁变化(比如点赞数一直在涨),你就得不停地更新对应成员的分数,这也会带来一定的开销。
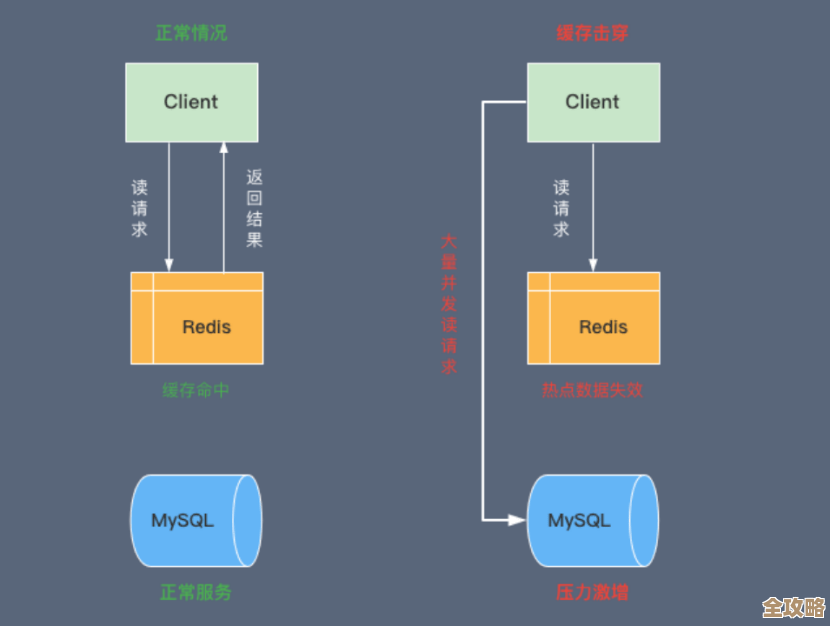
第三点,小心“空洞”和重复数据。 这个坑特别容易在Sorted Set里踩到,想象一个场景:你按点赞数分页,第一页是点赞最多的10条内容,正当用户在看第一页的时候,其中一条内容突然被点了很多赞,它的分数暴增,可能就从第一页“跳”到了更前面(如果分数高到足以进入Top 10并且排名变化),原本在第十一名的内容就补位进了第一页,但问题是,用户接下来翻到第二页时,可能会看到刚才已经从第一页“消失”的那条内容(因为它排名下降后落到了第二页),这就造成了重复显示,更糟的是,如果同时有内容被删除,排名靠后的内容会依次递补,可能导致用户翻页时感觉内容“跳”了一下,有些内容好像莫名其妙就错过了,这种现象在动态变化的排序分页里很难完全避免,需要在前端或交互设计上做一些提示,或者考虑使用更稳定的锚点分页方式(比如记录上一页最后一条的分数和ID)。
第四点,别光存ID,想想要不要缓存完整数据。 通常为了节省内存,我们只在Redis的列表或集合里存数据的ID,真正分页拿到ID列表后,还得再去查询一遍数据库或者另一个缓存(比如用Redis Hash存储的完整对象)来获取每条数据的详细信息(标题、作者等),这会产生多次网络请求,虽然Redis本身快,但如果每页10条内容就要发起10次查询,累积起来延迟也可能上去。
一个优化办法是做“二级缓存”,如果单条数据不大,且访问频繁,可以在存ID列表的同时,用Redis的Hash结构把对应的完整数据也缓存起来,这样,分页时先拿到ID列表,再用HMGET这样的命令一次性批量获取所有ID对应的详细数据,减少网络往返次数,这又带来了数据一致性的新问题:如果某条数据的详情更新了,你除了要更新Hash里的数据,可能还得考虑列表里的排序依据是否发生了变化,要不要调整。
第五点,内存是个宝,乱用很快就爆。 Redis的数据是放在内存里的,比硬盘贵,如果你把成千上万条数据的全文都塞进Redis做分页,用不了多久内存就可能告急,一定要评估好数据量,只缓存最需要、最热的那部分数据,可以考虑设置过期时间(TTL),让不常用的缓存自动失效,对于海量历史数据的分页,可能最终还是得结合数据库,Redis只作为热门数据的加速手段。
别忘了极端情况。 请求一个超大页码怎么办?比如总共就100条数据,用户直接请求第1000页,如果用LRANGE去取一个不存在的范围,Redis会返回空列表,这没问题,但如果你没有在应用层判断页码的有效性,可能就会做一些无谓的操作,又或者,缓存万一挂了(比如Redis服务重启),你的分页功能能不能自动降级到直接查数据库?要有兜底方案,不能因为缓存挂了整个页面就崩了。
用Redis分页,速度快是最大的诱惑,但背后的数据一致性、结构选择、更新策略、内存管理和异常处理,这些细节才是决定它能不能在实际项目中稳稳跑起来的关键,图快之前,先得把这些细节琢磨透。
(完)

本文由盘雅霜于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/76311.html