Redis Stream真挺强的,拿它来做数据流处理系统其实还蛮有意思的,redis的stream到底能怎么玩呢?

最近我在网上瞎逛,看到有人在讨论Redis,说“Redis Stream真挺强的,拿它来做数据流处理系统还蛮有意思的”,这话一下就勾起了我的好奇心,因为我一直觉得Redis就是个缓存数据库,顶多玩玩数据结构,怎么突然就跟“数据流处理”这种听起来高大上的词扯上关系了?于是我就去研究了一下,发现这个Stream功能确实有点东西,玩法比我想象的要丰富得多。
那,Redis Stream到底是个啥?
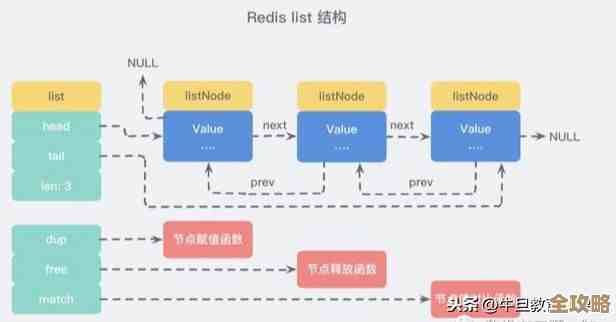
你可以把它想象成一个超级加强版的消息队列,或者更形象地说,它就像一个永远不会断的、只许追加的日志文件,想象一下工厂的流水线,产品(数据)一个接一个地放上去,排着队等着被处理,Redis Stream就是那条流水线,每条消息都有一个唯一的、基于时间排序的ID,这就保证了消息的顺序性。
它为啥适合做数据流处理?
它快!这是Redis的老本行了,数据都在内存里,读写速度没得说,对于需要快速响应的数据流场景,比如实时监控用户点击行为、处理物联网传感器上报的数据,速度是硬道理。
它支持“消费者组”,这是关键,好比一个流水线旁边站了多个工人(消费者),他们从一个队伍里轮流领取任务去处理,这样就能轻松实现负载均衡:活太多一个人干不完?那就多叫几个工人来一起干嘛!Stream会记录每个工人处理到哪个位置了,就算某个工人中途掉线了,等他回来还能从上次没干完的地方继续干,不会漏掉任务,这就保证了数据的可靠性。

那具体能怎么玩呢?我来举几个接地气的例子:
-
网站实时动态流(比如简易版微博feed): 用户A发了一条新状态,我们不是立刻推送给所有粉丝,那样服务器压力太大,而是把这条状态当作一条消息,丢进一个叫“全局动态流”的Stream里,每个粉丝都有一个独立的读取位置,他们上线刷新时,就根据自己的位置去这个Stream里拉取自己还没看过的新动态,这样既实时又高效。
-
物联网数据收集与分发: 假设你有成千上万个温度传感器,每秒钟都在上报数据,你可以让所有传感器都把数据发到同一个叫“传感器数据流”的Stream里,后台可以部署多个不同的“消费者组”来同时处理这些数据:
- 告警组: 专门盯着每条数据,一旦温度超过阈值,立刻触发告警,发邮件或短信。
- 存储组: 负责把数据从Stream里读出来,然后规整一下,存到像MySQL这样的持久化数据库里,供以后分析用。
- 实时大屏组: 专门读取数据,推送到前端的实时监控大屏幕上展示。 你看,一份数据进来,被多个不同的“小组”同时处理,各司其职,互不干扰,架构一下子就清晰简单了。
-
异步任务队列: 用户上传一个视频,转码很耗时,不能让他干等着,我们就把“需要给视频A做转码”这个任务封装成一条消息,扔进一个叫“视频转码任务流”的Stream里,后台有一群转码 worker(消费者)在不停地从这个流里取任务来处理,处理完了,再把结果写到别的地方,这样就把耗时的操作异步化了,网站响应速度飞快。

-
事件溯源(这个听起来高级,但其实不难理解): 比如做一个游戏,要记录玩家所有的金币变化记录(充值100金币、购买道具消耗50金币、完成任务奖励20金币……),我们可以把每一次变化都当作一个不可更改的“事件”,按顺序记录到一个叫“玩家金币流水”的Stream里,那么玩家当前有多少金币呢?不用单独存一个数字,只需要把这个流里所有事件从头到尾算一遍加加减减就行了,这样你就得到了一个非常可靠、可以追溯的完整账本,任何时候都能清楚地知道每一分钱的来龙去脉。
它也不是万能的。
Stream里的消息默认是堆积在内存里的,虽然可以设置最大长度或者定时清理,但如果你要处理海量历史数据且需要长期保存,可能还是需要像Kafka这样专精于磁盘存储的巨无霸消息队列,但对于很多数据量不是天量、但要求极低延迟和简单易用的实时场景来说,Redis Stream无疑是一个非常轻量、灵活且强大的瑞士军刀。
所以回过头看,说“Redis Stream拿来做数据流处理系统蛮有意思的”,确实没说错,它把复杂的概念用很简单的方式实现了出来,让我们能用很低的成本就搭建起一个高效、可靠的实时数据处理管道,如果你正在做一个需要处理连续不断的数据的小项目,别再只把它当缓存了,不妨试试它的Stream功能,可能会给你带来惊喜。
(注:以上理解和例子参考了网络上多位开发者在技术社区如知乎、掘金、CSDN等平台分享的关于Redis Stream的应用实践和讨论,并结合个人理解进行了解释。)
本文由度秀梅于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/76154.html