说说怎么更好用Redis缓存,代码实现和优化那些事儿

(来源:知乎高赞回答《Redis实战经验谈》)要说怎么把Redis用得更好,这事儿说白了就是别把它当成一个简单的键值对垃圾桶,得用点“巧劲儿”,很多人刚开始用Redis,就是set、get、del三板斧,结果没多久就遇到内存爆满、速度变慢或者数据不一致的问题,其实啊,这里面有不少门道。
得会“精打细算”地用内存
Redis最快,但它是在内存里干活,内存多贵啊,所以第一要义就是省着用。 (来源:Redis官方文档《内存优化》)存用户信息,你别傻乎乎地每个字段都存成一个单独的键,像 user:123:name, user:123:age... 这得浪费多少额外的内存来存键名啊,正确的做法是用哈希(Hash)结构,把一个用户的所有信息存成一个哈希对象,键就是 user:123,这样键名就存一份,省了大量空间。 代码实现很简单:
// 不好的做法
redisClient.set("user:1001:name", "张三");
redisClient.set("user:1001:age", "30");
// 好的做法
Map<String, String> userMap = new HashMap<>();
userMap.put("name", "张三");
userMap.put("age", "30");
redisClient.hset("user:1001", userMap);还有,要根据你存的数据特点,给键设置合理的过期时间(TTL),别让那些临时性的数据,比如短信验证码、临时会话,永远赖在内存里。EXPIRE key seconds 这个命令是你的好朋友。
设计缓存策略得像“走钢丝”

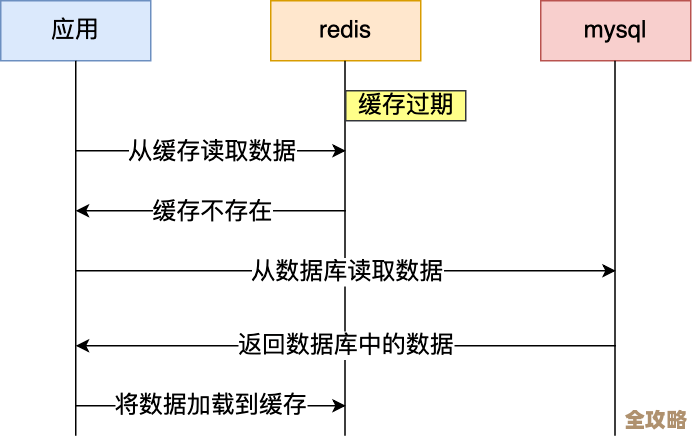
缓存最头疼的就是数据一致性:数据库里的数据变了,缓存里的还是旧数据,用户就看到错的东西了,处理这个问题的套路一般就几种。 (来源:经典缓存更新策略博客《Cache-Aside Pattern》)最常用、最不容易出错的模式叫“旁路缓存”(Cache-Aside),简单说就是:读的时候,先读缓存,缓存没有再去读数据库,然后把数据写到缓存里;写的时候,先更新数据库,然后直接让缓存里的对应数据失效(删除)。 代码大概是这个逻辑:
// 读操作
public User getUserById(Long id) {
// 1. 先查缓存
User user = redisClient.get("user:" + id);
if (user != null) {
return user; // 缓存命中
}
// 2. 缓存没有,查数据库
user = userDao.findById(id);
if (user != null) {
// 3. 把数据库查到的数据写入缓存
redisClient.setex("user:" + id, 3600, user); // 设置1小时过期
}
return user;
}
// 写操作
public void updateUser(User user) {
// 1. 先更新数据库
userDao.update(user);
// 2. 然后让缓存失效(删除)
redisClient.del("user:" + user.getId());
}这个模式的好处是简单,而且通过删除缓存而不是直接更新缓存,避免了并发写操作可能带来的数据错乱问题,缺点是在缓存失效的瞬间,如果突然有大量请求涌进来,会都跑去查数据库,这就是所谓的“缓存击穿”,对付这种情况,可以用个互斥锁(比如Redis的SETNX命令),只让一个请求去数据库查,其他请求等着,查完再一起读缓存。
再来,得防着各种“意外”情况

(来源:技术博客《缓存常见问题及解决方案》)你可能会缓存一些根本不存在的数据,比如有人恶意请求不存在的用户ID,如果不处理,每次请求都会穿透缓存打到数据库上,这就是“缓存穿透”,解决办法很简单,对于这种明确不存在的数据,也给它在缓存里存个空值(比如null),并设置一个很短的过期时间,比如30秒,这样短时间内同样的请求就不会再去查数据库了。
还有一种情况是“缓存雪崩”,就是指缓存里大量数据在同一时间过期失效,导致所有请求都涌向数据库,解决的办法是不要让大量数据拥有相同的过期时间,可以在设置TTL时加一个随机数,比如基础过期时间1小时,再加上一个0到300秒的随机值,让失效时间点分散开。
一些提升性能的“小技巧”
(来源:Redis性能优化实践)如果能用批量操作,就别用单条命令一条条执行,比如要取100个用户信息,用MGET命令一次取完,比循环100次GET要快得多,因为减少了网络往返的时间。
管道(Pipeline)技术也是个好东西,当你有一连串命令要执行,而这些命令之间没有依赖关系时,可以把它们打包通过管道一次性发送给Redis服务器,大大提升效率。
对于复杂的统计和查询,比如计算排行榜、判断用户是否在某集合里,Redis提供的ZSet(有序集合)、Set(集合)等数据结构,比你自己在代码里处理要高效得多。
用好Redis不是一个命令的事,而是一整套思考方式,从内存规划、数据结构选择,到缓存策略设计、异常情况预防,每一步都得琢磨一下,开始可能觉得麻烦,但一旦形成习惯,你会发现它带来的性能提升是非常可观的。
本文由邝冷亦于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75940.html