ORA-16419错误导致快照备用库需转成物理备用,远程故障修复思路分享

ORA-16419错误导致快照备用库需转成物理备用,远程故障修复思路分享
最近在处理一个客户的数据库问题时,遇到了一个典型的由ORA-16419错误引发的故障,最终需要通过将快照备用数据库转换回物理备用数据库来解决,整个过程是通过远程操作完成的,现将当时的排查思路和解决步骤记录下来,希望能为遇到类似情况的朋友提供一些参考,这个案例的记录主要参考了当时的工作日志和与客户的技术沟通记录。
问题背景与现象
客户的核心生产系统采用Oracle Data Guard架构,有一个物理主库和一个快照备用库,这个快照备用库平时处于“快照”模式,可以打开进行读写操作,主要用于报表查询和业务测试,以减轻主库的压力,根据计划,客户需要将这个快照备用库暂时恢复为物理备用模式,以便进行一些数据同步维护。
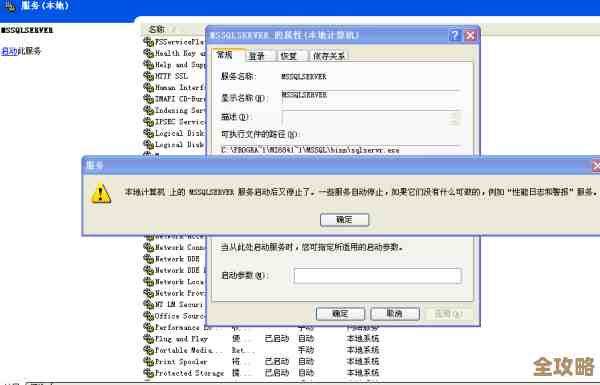
在执行转换命令 ALTER DATABASE CONVERT TO PHYSICAL STANDBY; 之后,进程并没有顺利完成,而是中断并报告了错误,告警日志中明确记录了ORA-16419错误,根据Oracle官方文档对Data Guard错误代码的描述,ORA-16419通常意味着“操作需要启用日志传输服务,但该服务当前未激活”,就是数据库认为当前环境不具备转换为物理备用的基本通信条件。

远程排查思路与步骤
由于是远程支持,我们无法直接接触服务器,所有操作都依赖于客户的配合和通过终端工具获取的信息,我们的排查遵循了从简到繁、从表象到本质的原则。
-
确认当前数据库状态 我们让客户连接上出现问题的快照备用库实例,查询其当前状态,通过执行
SELECT DATABASE_ROLE, OPEN_MODE FROM V$DATABASE;,确认该数据库确实处于“SNAPSHOT STANDBY”角色,但OPEN_MODE可能显示为“READ WRITE”或出现了异常,这一步是为了确保我们操作的对象是正确的。 -
详细分析告警日志 告警日志是诊断Data Guard问题的金矿,我们让客户提供了错误发生时间点前后的完整告警日志内容,在日志中,除了ORA-16419错误本身,我们还重点关注了以下几个线索:

- 日志传输状态:检查是否有关于ARC(归档进程)、LNS(日志网络服务器进程)的错误信息,果然,在错误发生前,日志中持续存在尝试连接主库但失败的记录,Error 12514 received logging on to the standby”,这表明备用库无法正确解析或连接到主库的服务名。
- 网络连接性:日志中的网络超时或连接拒绝错误,直接指向了网络或监听器问题。
- 参数文件检查:对比了主库和备用库的初始化参数文件(pfile或spfile),重点关注
LOG_ARCHIVE_DEST_n参数(特别是指向主库的配置)、FAL_SERVER、DB_UNIQUE_NAME等关键参数,发现备用库的LOG_ARCHIVE_DEST_2(指向主库)的状态被意外设置为了DEFER,这意味着日志传输服务到主库的方向被手动延迟了,参考Oracle官方文档关于日志归档目的地参数的说明,DEFER状态会暂停传输。
-
检查网络与监听器 基于告警日志的提示,我们指导客户检查了网络连通性,使用
tnsping命令测试从备用库服务器到主库监听器的连接,结果是通的,排除了基础网络故障,检查主库的监听器状态lsnrctl status,确认监听器正常运行,并且注册了主库的实例服务。 -
深入挖掘根本原因 虽然网络是通的,监听器是好的,但日志传输仍然失败,且参数被设置为
DEFER,这很不寻常,我们进一步询问客户在尝试转换前是否进行过其他操作,客户回忆说,之前因为做测试,为了暂时断开与主库的同步,曾经执行过ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2=DEFER;命令,但在测试结束后,忘记将其恢复为ENABLE,这个被遗忘的操作,正是导致ORA-16419错误的根本原因,快照备用库在转换回物理备用时,需要先与主库重新建立日志传输链路,但由于目标被延迟,这个预备步骤失败,从而触发了错误。
解决方案与执行过程
找到原因后,解决方案就非常清晰了,我们的目标是重新启用日志传输服务,然后再次尝试转换。

-
重新启用日志传输目标 在快照备用库上,我们让客户执行命令:
ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2=ENABLE;,这个命令立即生效,取消了延迟状态。 -
验证日志传输恢复 执行启用命令后,我们让客户观察备用库的告警日志,很快,日志中出现了新的条目,显示归档进程(ARC)开始尝试向主库传输日志,并且连接成功建立,可以在主库端通过查询
V$ARCHIVED_LOG视图或监视日志传输状态来确认。 -
再次执行转换命令 在确认日志传输服务恢复正常后,我们谨慎地让客户再次执行转换命令:
ALTER DATABASE CONVERT TO PHYSICAL STANDBY;,这一次,命令顺利执行完成,没有报错。 -
转换后检查 转换完成后,立即检查数据库状态:
SELECT DATABASE_ROLE, OPEN_MODE FROM V$DATABASE;,角色应显示为“PHYSICAL STANDBY”,打开模式为“MOUNTED”,随后,启动Redo Apply进程:ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;,再次确认备用库的同步状态,例如查询V$DATAGUARD_STATS等视图,确保数据同步正常进行。
经验总结与反思
这次远程修复ORA-16419错误的过程,给我们带来了几点重要的启示,这些经验也记录在我们的内部知识库中:
- 参数管理要谨慎:对于Data Guard环境中的关键参数(尤其是
LOG_ARCHIVE_DEST_STATE_n),任何修改都应有详细的记录和复核流程,临时性的调整必须在事后及时恢复,否则会为后续操作埋下隐患。 - 告警日志是第一手资料:遇到任何Data Guard错误,首要任务就是仔细、完整地阅读告警日志,它往往能直接或间接地指出问题的方向,避免走弯路。
- 操作前做好检查:在执行像角色转换这样的重要操作之前,应该有一个简单的预检清单,检查所有必要的日志传输链路是否处于“ENABLE”状态,验证网络连通性等,防患于未然。
- 远程协作效率关键:远程处理问题时,清晰的指令和有效的信息获取至关重要,指导方需要明确告诉对方需要执行什么命令、观察什么现象、提供什么日志;被指导方则需要准确执行并及时反馈。
ORA-16419错误虽然看起来棘手,但通常根源在于配置或状态异常,通过系统性的排查,特别是紧扣“日志传输服务”这个核心,大多数问题都可以得到有效解决。
本文由畅苗于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75780.html