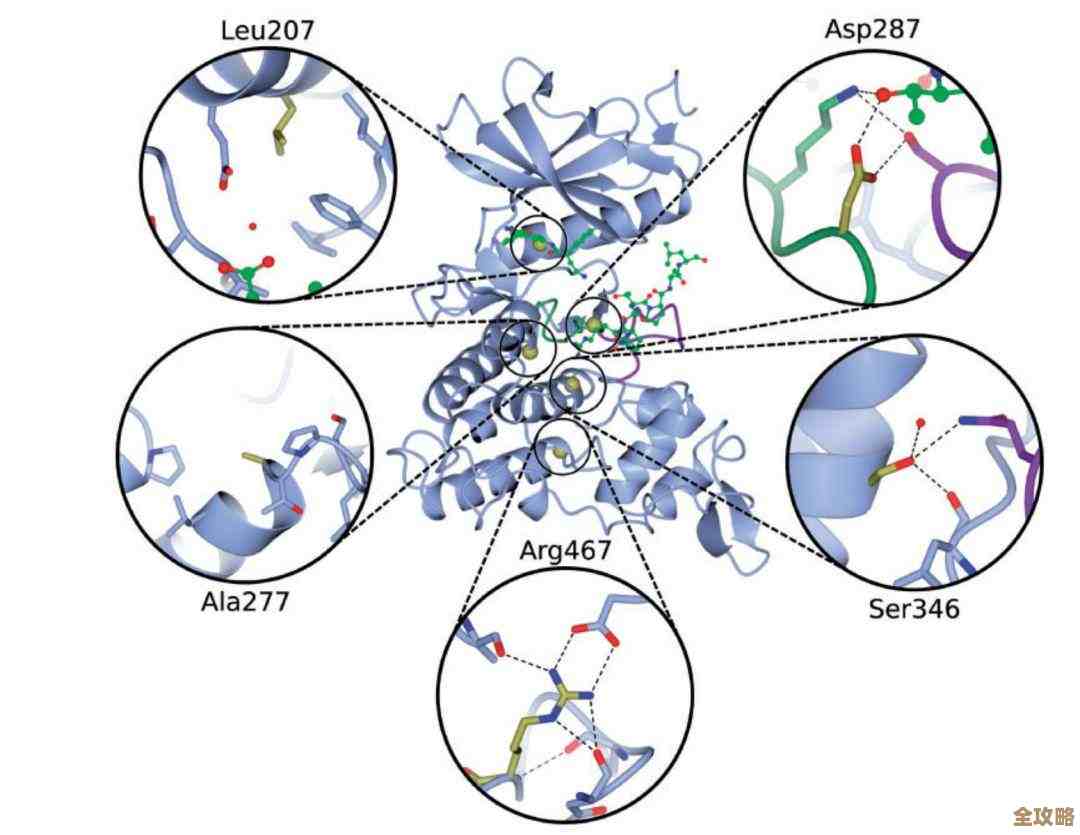
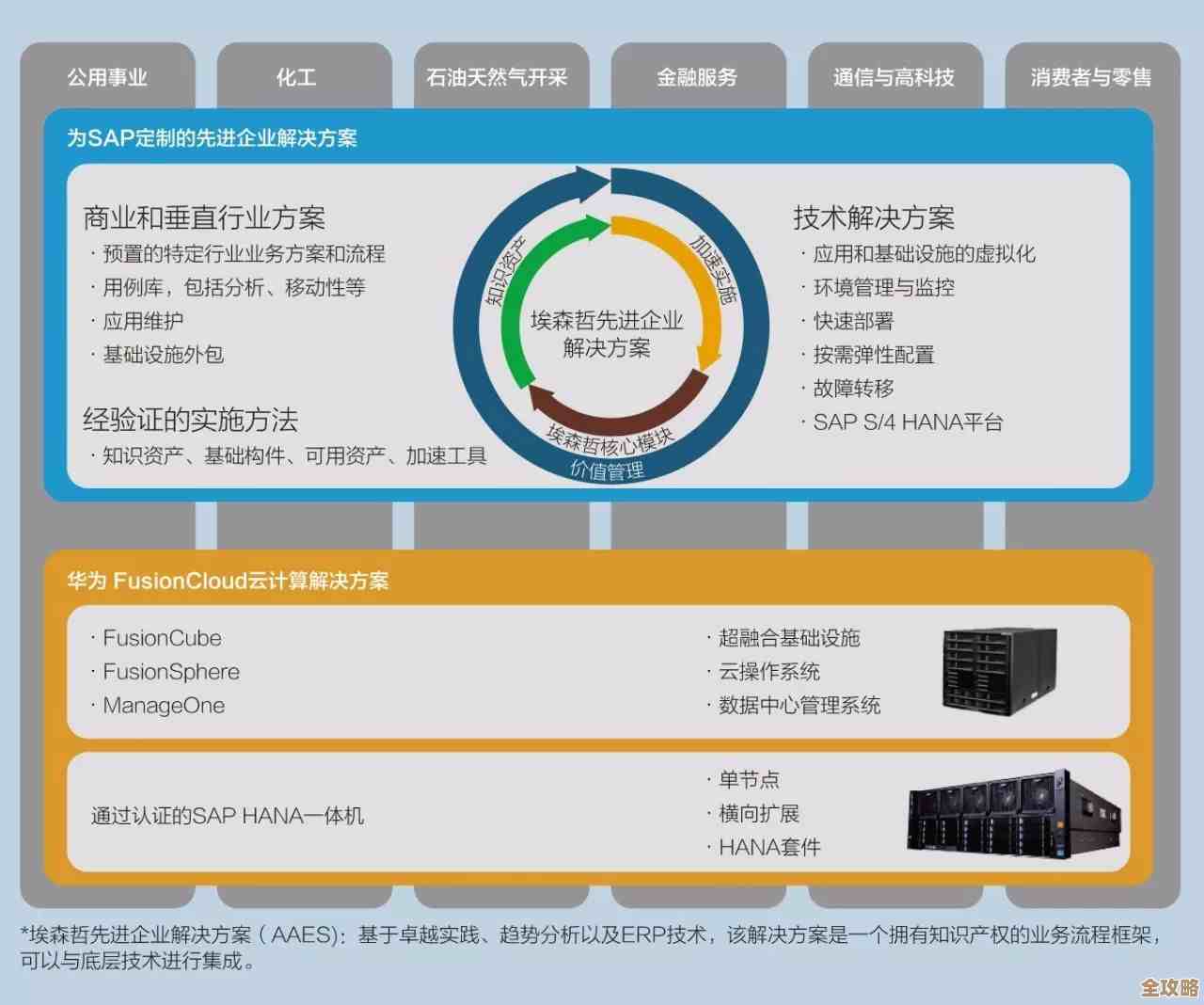
拖库数据库到底是啥,为什么说它成了数据库管理的新风向标?

(根据“InfoQ”、“CSDN”、“阿里云技术社区”等多方技术社区和媒体报道的综合信息)
拖库数据库,就是一种把数据库“搬回家”的全新方式,在过去,企业要用数据库,主要有两种选择:一是自己买服务器,自己安装、自己维护,这叫“本地部署”;二是直接用云服务商提供的数据库,数据存在人家的机房里,按需付费,这叫“数据库即服务”(DBaaS),而拖库数据库,可以理解为是第二种方式的一个“升级版”或者说“灵活版”,它的核心魅力在于“可迁徙性”。
为什么说它成了数据库管理的新风向标呢?这得从企业,尤其是开发者和运维人员的痛点说起。
最大的痛点是“被锁死”,也就是所谓的“厂商锁定”。(根据“极客时间”专栏分析)当企业把全部数据和应用都构建在某个特定的云服务商(比如阿里云、腾讯云、AWS)的数据库上时,再想迁移到另一家就会变得异常困难,这就像你住进了一个装修精美、设施齐全的精装房,但所有的家具、水电线路都是定制的,你想搬家?代价巨大,几乎等于重新装修,拖库数据库就是为了打破这种束缚,它允许企业将云数据库的完整运行环境(包括数据库引擎、配置、甚至部分数据)打包成一个“镜像”或“容器”,然后轻松地“拖”到自己的电脑上,或者另一家云服务商的平台上运行,这意味着企业拥有了前所未有的选择自由,可以根据成本、性能、政策要求随时切换,不再受制于单一云厂商。
它极大地提升了开发和测试的效率。(引用自“GitHub社区”中开发者的普遍反馈)在传统的开发流程中,如果开发人员需要一个和生产环境类似的数据库来进行测试,过程往往很繁琐:可能需要向运维部门申请,等待权限,然后导入大量可能不完整的测试数据,这个过程耗时耗力,而有了拖库数据库,运维人员可以直接将生产数据库的一个“快照”或“精简版”打包,开发者就像下载一个软件安装包一样,一键就能在本地拉起一个高度仿真的数据库环境,这大大缩短了搭建开发环境的时间,让开发者能更快地投入编码和调试,出了问题也能在本地快速复现和排查,实现了真正意义上的“开发与生产环境一致”。
第三,它在数据安全和合规方面展现出独特优势。(参考“安全牛”等安全媒体观点)对于一些涉及敏感数据的行业,比如金融、医疗、政务等,法规可能要求数据不能出境,或者必须存储在特定的物理位置,虽然云服务商都提供了合规的解决方案,但一些企业仍然对将核心数据完全托付给第三方感到不安,拖库数据库技术让企业有了一个“进退自如”的方案:既可以在平时享受云数据库的弹性伸缩和高可用性,在需要应对严格审计或执行特殊安全策略时,又能迅速将数据库实例“拖回”到自家严格管控的私有化机房中运行,这种混合云的灵活性,为企业在数据主权和安全合规之间找到了一个很好的平衡点。
它代表了云原生技术发展的必然趋势。(综合“CNCF社区”和主流云厂商的发布信息)拖库数据库的实现,底层高度依赖于容器化技术(如Docker)和编排技术(如Kubernetes),这些技术的特点就是让应用及其运行环境变得标准化、轻量化、可移植,数据库作为应用的核心,自然也顺应了这一潮流,当数据库本身也能被像普通应用一样打包、分发、部署时,它就真正融入了现代软件开发和运维的敏捷体系之中。
拖库数据库并不是一个遥不可及的黑科技,而是云计算发展到一定阶段后,为了满足企业对灵活性、效率和安全的更深层次需求而诞生的务实解决方案,它把选择权和控制权更多地交还给了企业用户,让数据库这个曾经的“重资产”变得轻巧和灵动起来,正因为切中了这些要害,它才被广泛认为是数据库管理和云服务演进的一个重要新方向。

本文由瞿欣合于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75627.html