哨兵模式下Redis怎么保证不停机还能自动切换故障的那些事儿

哨兵模式是Redis官方提供的一种高可用方案,它的核心目标就是解决一个问题:当主Redis服务器(Master)突然挂掉的时候,整个系统能够自动地、尽快地恢复正常服务,让用户几乎感觉不到故障的发生,这事儿听起来简单,但背后是一套精巧的“侦察兵”和“选举”机制。
哨兵们是怎么工作的?
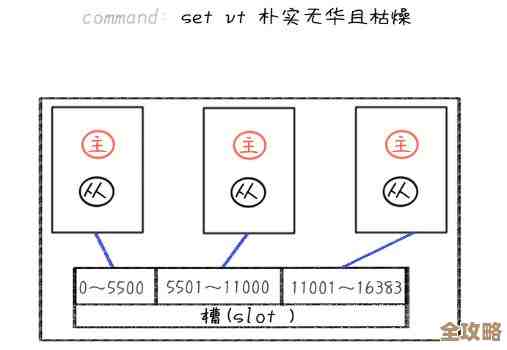
你可以把哨兵(Sentinel)想象成一群被独立部署的、不干具体存储活儿的值班侦察兵,这些哨兵进程是独立的,通常建议至少部署三个,并且分布在不同的服务器上,这样可以防止某台服务器整体宕机导致哨兵系统本身瘫痪。

这群哨兵的主要任务就是时时刻刻盯着主Redis服务器和它手下的从服务器(Slaves)是否还“活着”,它们之间也会互相通信,交换情报,具体的监视过程是这样的(根据Redis官方文档描述的工作机制):
- 定期检查(心跳检测):每个哨兵会每隔一秒钟向所有被监控的主服务器、从服务器以及其他哨兵发送一个名为“PING”的命令,这就像哨兵每隔一秒就对各个节点喊一声“喂,你还在吗?”。
- 主观下线判断:如果被PING的节点(比如主服务器)在设定的时间内(通常配置为30秒)没有给出正确的回复,那么发起这次PING的哨兵就会“主观地”认为这个主服务器可能挂掉了,它会在自己的小本本上记下“主节点疑似下线”,但这时候还不能贸然行动,因为可能只是这个哨兵自己网络不好,误判了。
- 客观下线判断:当有一个哨兵认为主节点主观下线后,它会把这个怀疑告诉给其他哨兵,其他哨兵收到消息后,也会各自去尝试联系这个主节点,当认为主节点下线的哨兵数量达到一个预设的法定人数(比如三个哨兵中至少有两个都认为主节点挂了),那么哨兵们就会达成共识,做出一个“客观下线”的判定,这相当于民主投票,少数服从多数,避免了单个哨兵误判导致瞎指挥。
故障发生了,怎么自动切换?

一旦主节点被判定为客观下线,哨兵们就要开始执行最关键的步骤——选举新的主节点,这个过程是为了避免混乱,确保只有一个新主节点被选出(根据Redis官方文档描述的故障转移流程):
- 选举领头哨兵:这群哨兵需要先内部选出一个“领头羊”(Leader)来主持大局,这个选举过程也遵循投票机制,每个哨兵都会投票给第一个向它发起投票请求的哨兵,并且每个哨兵在每一轮选举中只能投一票,得票超过半数的哨兵就成为领头哨兵,由这个领头哨兵来负责后续的故障转移操作,这样能保证指令的唯一性。
- 挑选新主节点:领头哨兵诞生后,它就要从现存的所有从节点中挑选一个最合适的“扶正”为新的主节点,挑选可不是随便点的,它有一套筛选规则:
- 优先级:管理员可以给从节点设置一个优先级(slave-priority),数字越小优先级越高,哨兵会优先选择优先级最高的从节点。
- 数据同步程度:如果优先级相同,哨兵会检查每个从节点复制主节点数据的偏移量,偏移量越大,说明这个从节点的数据和原主节点断开连接前的数据越接近,数据最完整、最新。
- 运行ID:如果连数据偏移量都一模一样(这种情况极少),那就选择一个运行ID最小的从节点(可以理解为资历最老的)。
- 执行切换:新主节点选定后,领头哨兵就会向这个从节点发送“SLAVEOF no one”命令,让它“翻身做主人”,停止复制操作,开始以主节点的身份提供服务。
- 通知与切换:紧接着,领头哨兵会向其他所有从节点发送新的配置信息,命令它们去复制这个新上任的主节点,它也会将最新的配置(谁是新的主节点)通知给仍然在线的客户端,这样,客户端之后就会自动连接到新的主节点上进行读写操作。
- 旧主节点处理:哨兵还会持续监控那个已经挂掉的旧主节点,如果某一天它恢复了,哨兵会检测到它重新上线,然后会命令它以从节点的身份加入新的体系,让它去复制新主节点的数据,这样,它就变成了一个新的从节点,而不会自动抢回主节点的位置,避免了二次混乱。
总结一下
哨兵模式保证Redis不停机自动切换故障的核心,就在于那一群哨兵通过多数决机制进行客观判断,并民主选举出领头者来执行有序的故障转移,它通过自动化的监控、判断、选举和配置更新,实现了从故障发生到服务恢复的无人值守,大大提高了Redis服务的可靠性,虽然不能保证100%的数据不丢失(因为主从复制是异步的,故障时可能丢失极少量最新数据),但它极大地保障了服务的持续可用性。
本文由歧云亭于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75544.html